
 Lucas A. Wilson
ebce5d74b7
Issue #271: Updated .md files for Omnia Core and Appliance
Lucas A. Wilson
ebce5d74b7
Issue #271: Updated .md files for Omnia Core and Appliance
|
4 years ago | |
|---|---|---|
| .. | ||
| images | 4 years ago | |
| metalLB | 4 years ago | |
| CONTRIBUTORS.md | 4 years ago | |
| INSTALL_OMNIA.md | 4 years ago | |
| INSTALL_OMNIA_APPLIANCE.md | 4 years ago | |
| INVENTORY | 4 years ago | |
| MONITOR_CLUSTERS.md | 4 years ago | |
| PREINSTALL_OMNIA.md | 4 years ago | |
| PREINSTALL_OMNIA_APPLIANCE.md | 4 years ago | |
| README.md | 4 years ago | |
| _config.yml | 4 years ago | |
README.md
Omnia (Latin: all or everything) is a deployment tool to configure Dell EMC PowerEdge servers running standard RPM-based Linux OS images into clusters capable of supporting HPC, AI, and data analytics workloads. It uses Slurm, Kubernetes, and other packages to manage jobs and run diverse workloads on the same converged solution. It is a collection of Ansible playbooks, is open source, and is constantly being extended to enable comprehensive workloads.
What Omnia does
Omnia can build clusters which use Slurm or Kubernetes (or both!) for workload management. Omnia will install software from a variety of sources, including:
- Standard CentOS and ELRepo repositories
- Helm repositories
- Source code compilation
- OpenHPC repositories (coming soon!)
- OperatorHub (coming soon!)
Whenever possible, Omnia will leverage existing projects rather than reinvent the wheel.
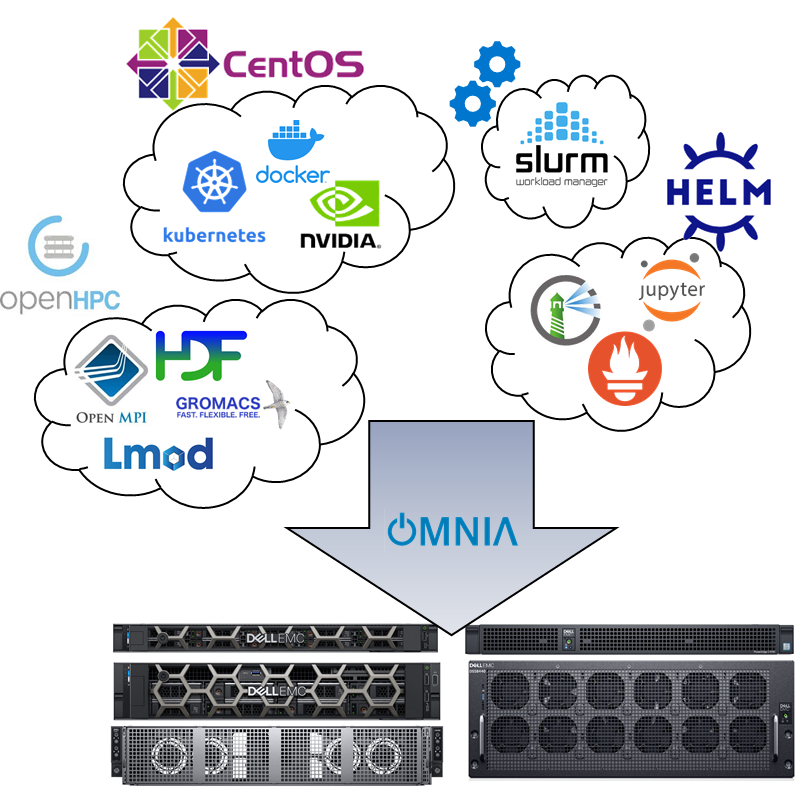
Omnia stacks
Omnia can install Kubernetes or Slurm (or both), along with additional drivers, services, libraries, and user applications.
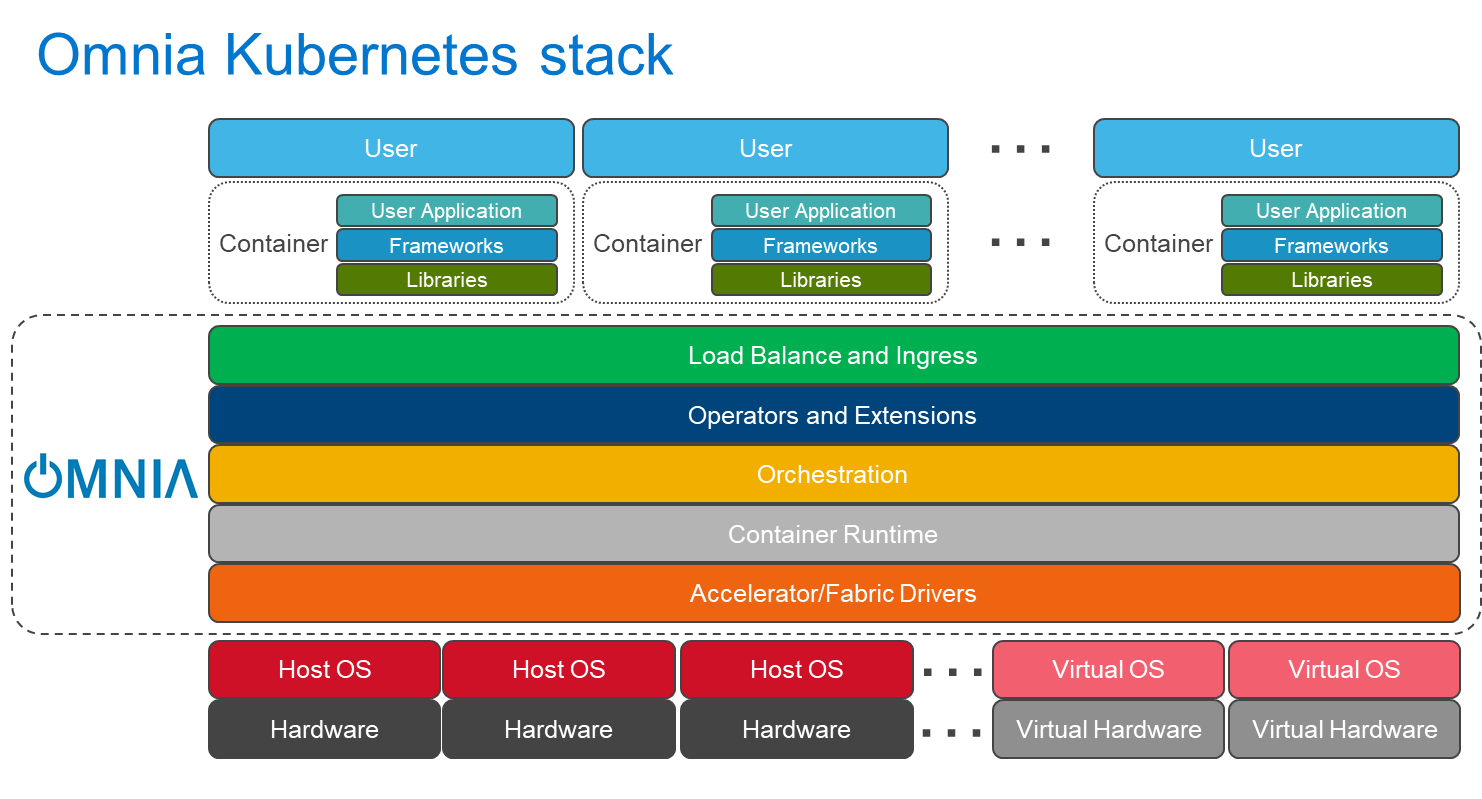
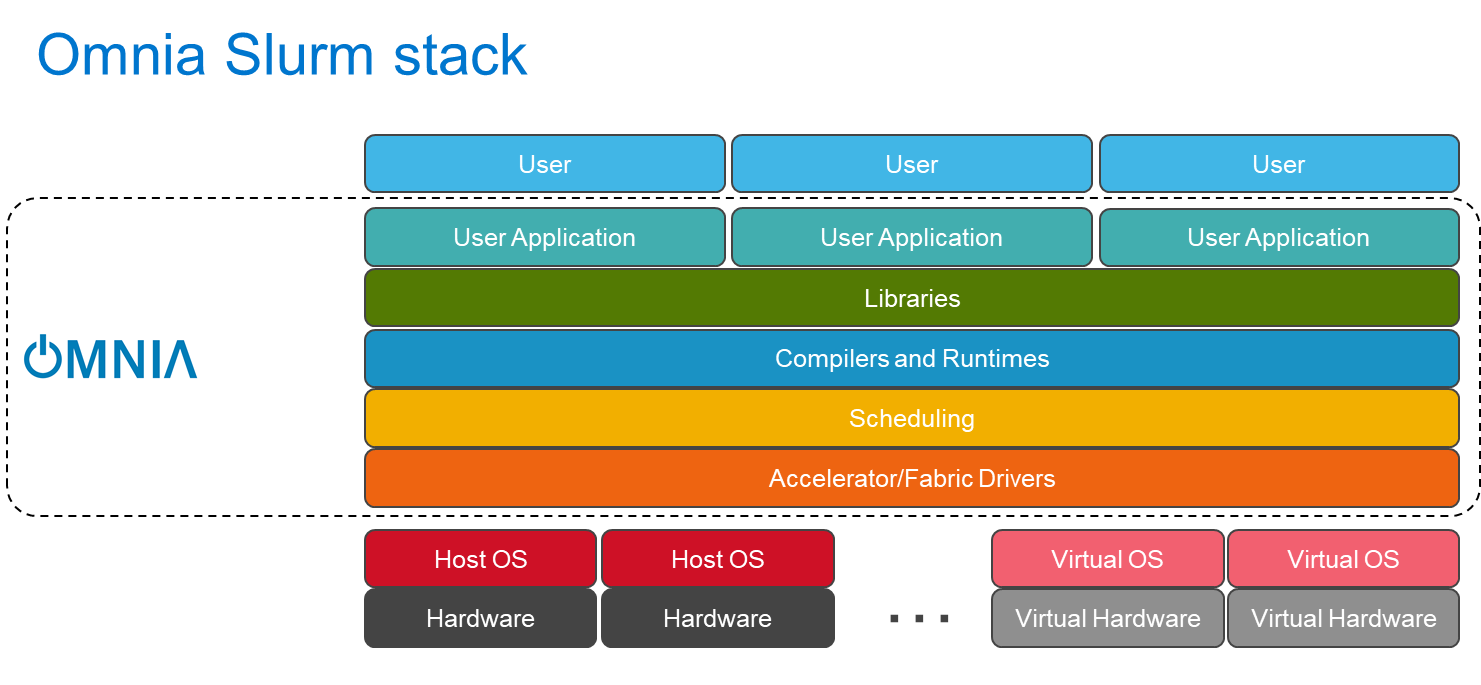
Installing Omnia
Omnia requires that servers already have an RPM-based Linux OS running on them, and are all connected to the Internet. Currently all Omnia testing is done on CentOS. Please see Preparation to install Omnia for instructions on network setup.
Once servers have functioning OS and networking, you can use Omnia to install and start Slurm and/or Kubernetes. Please see Install Omnia using CLI for detailed instructions.
Installing the Omnia appliance
Ensure all the prerequisites listed in the PREINSTALL_OMNIA_APPLIANCE are met before installing the Omnia appliance.
For detailed instructions on installing the Omnia appliance, see INSTALL_OMNIA_APPLIANCE.
System requirements
Ensure the supported version of all the software are installed as per the following table and other versions than those listed are not supported by Omnia. This is to ensure that there is no impact to the functionality of Omnia.
| Software and hardware requirements | Version |
|---|---|
| OS installed on the management node | CentOS 7.9 2009 |
| OS deployed by Omnia on bare-metal servers | CentOS 7.9 2009 Minimal Edition |
| Cobbler | 2.8.5 |
| Ansible AWX | 15.0.0 |
| Slurm Workload Manager | 20.11.2 |
| Kubernetes Controllers | 1.16.7 |
| Kubeflow | 1 |
| Prometheus | 2.23.0 |
| Supported PowerEdge servers | R640, R740, R7525, C4140, DSS8440, and C6420 |
Software managed by Omnia
Ensure the supported version of all the software are installed as per the following table and other versions than those listed are not supported by Omnia. This is to ensure that there is no impact to the functionality of Omnia.
| Software | Licence | Compatible Version | Description |
|---|---|---|---|
| MariaDB | GPL 2.0 | 5.5.68 | Relational database used by Slurm |
| Slurm | GNU General Public | 20.11.2 | HPC Workload Manager |
| Docker CE | Apache-2.0 | 20.10.2 | Docker Service |
| NVIDIA container runtime | Apache-2.0 | 3.4.2 | Nvidia container runtime library |
| Python PIP | MIT Licence | 3.2.1 | Python Package |
| Python2 | - | 2.7.5 | - |
| Kubelet | Apache-2.0 | 1.16.7 | Provides external, versioned ComponentConfig API types for configuring the kubelet |
| Kubeadm | Apache-2.0 | 1.16.7 | "fast paths" for creating Kubernetes clusters |
| Kubectl | Apache-2.0 | 1.16.7 | Command line tool for Kubernetes |
| JupyterHub | Modified BSD Licence | 1.1.0 | Multi-user hub |
| Kfctl | Apache-2.0 | 1.0.2 | CLI for deploying and managing Kubeflow |
| Kubeflow | Apache-2.0 | 1 | Cloud Native platform for machine learning |
| Helm | Apache-2.0 | 3.5.0 | Kubernetes Package Manager |
| Helm Chart | - | 0.9.0 | - |
| TensorFlow | Apache-2.0 | 2.1.0 | Machine Learning framework |
| Horovod | Apache-2.0 | 0.21.1 | Distributed deep learning training framework for Tensorflow |
| MPI | Copyright (c) 2018-2019 Triad National Security,LLC. All rights reserved. | 0.2.3 | HPC library |
| CoreDNS | Apache-2.0 | 1.6.2 | DNS server that chains plugins |
| CNI | Apache-2.0 | 0.3.1 | Networking for Linux containers |
| AWX | Apache-2.0 | 15.0.0 | Web-based User Interface |
| PostgreSQL | Copyright (c) 1996-2020, PostgreSQL Global Development Group | 10.15 | Database Management System |
| Redis | BSD-3-Clause Licence | 6.0.10 | In-memory database |
| NGINX | BSD-2-Clause Licence | 1.14 | - |
Known issue
Issue: Hosts do not display on the AWX UI.
Resolution:
- Verify if
provisioned_hosts.ymlis present in theomnia/appliance/roles/inventory/filesfolder. - Verify if hosts are not listed in the
provisioned_hosts.ymlfile. If hosts are not listed, then servers are not PXE booted yet. - If hosts are listed in the
provisioned_hosts.ymlfile, then an IP address has been assigned to them by DHCP. However, hosts are not displyed on the AWX UI as the PXE boot is still in process or is not initiated. - Check for the reachable and unreachable hosts using the
provisioned_report.ymltool present in theomnia/appliance/toolsfolder. To run provisioned_report.yml, in the omnia/appliance directory, runplaybook -i roles/inventory/files/provisioned_hosts.yml tools/provisioned_report.yml.
Frequently asked questions
- Why is the error "Wait for AWX UI to be up" displayed when
appliance.yamlfails?
Cause:- When AWX is not accessible even after five minutes of wait time.
- When isMigrating or isInstalling is seen in the failure message.
Resolution:
Wait for AWX UI to be accessible at http://\<management-station-IP>:8081, and then run the `appliance.yaml` file again, where __management-station-IP__ is the ip address of the management node.
What are the next steps after the nodes in a Kubernetes cluster reboots?
Resolution: Wait for upto 15 minutes after the Kubernetes cluster reboots. Next, verify status of the cluster using the following services:kubectl get nodeson the manager node provides correct k8s cluster status.kubectl get pods --all-namespaceson the manager node displays all the pods in the Running state.kubectl cluster-infoon the manager node displays both k8s master and kubeDNS are in the Running state.
What to do when the Kubernetes services are not in the Running state?
Resolution:- Run
kubectl get pods --all-namespacesto verify the pods are in the Running state. - If the pods are not in the Running state, delete the pods using the command:
kubectl delete pods <name of pod> - Run the corresponding playbook that was used to install Kubernetes:
omnia.yml,jupyterhub.yml, orkubeflow.yml.
- Run
What to do when the JupyterHub or Prometheus UI are not accessible?
Resolution: Run the commandkubectl get pods --namespace defaultto ensure nfs-client pod and all prometheus server pods are in the Running state.While configuring the Cobbler, why does the
appliance.ymlfail with an error during the Run import command?
Cause:- When the mounted .iso file is corrupt.
- When the mounted .iso file is corrupt.
Resolution:
1. Go to __var__->__log__->__cobbler__->__cobbler.log__ to view the error.
2. If the error message is **repo verification failed** then it signifies that the .iso file is not mounted properly.
3. Verify if the downloaded .iso file is valid and correct.
4. Delete the Cobbler container using `docker rm -f cobbler` and rerun `appliance.yml`.
- Why does the PXE boot fail with tftp timeout or service timeout errors?
Cause:- When RAID is configured on the server.
- When more than two servers in the same network have Cobbler services running.
Resolution:
1. Create a Non-RAID or virtual disk in the server.
2. Check if other systems except for the management node has cobblerd running. If yes, then stop the Cobbler container using the following commands: `docker rm -f cobbler` and `docker image rm -f cobbler`.
What to do when the Slurm services do not start automatically after the cluster reboots?
Resolution:- Manually restart the slurmd services on the manager node by running the following commands:
systemctl restart slurmdbdsystemctl restart slurmctldsystemctl restart prometheus-slurm-exporter
- Run
systemctl status slurmdto manually restart the following service on all the compute nodes.
- Manually restart the slurmd services on the manager node by running the following commands:
What to do when the Slurm services fail? Cause: The
slurm.confis not configured properly.
Resolution:- Run the following commands:
slurmdbd -Dvvvslurmctld -Dvvv
- Verify
/var/lib/log/slurmctld.logfile.
- Run the following commands:
What to do when when the error "ports are unavailable" is displayed? Cause: Slurm database connection fails.
Resolution:- Run the following commands:
slurmdbd -Dvvv*slurmctld -Dvvv
- Verify the
/var/lib/log/slurmctld.logfile. - Verify: netstat -antp | grep LISTEN
- If PIDs are in the Listening state, kill the processes of that specific port.
- Restart all Slurm services:
- slurmctl restart slurmctld on manager node
- systemctl restart slurmdbd on manager node
- systemctl restart slurmd on compute node
- Run the following commands:
What to do if Kubernetes Pods are unable to communicate with the servers when the DNS servers are not responding? Cause: With the host network which is DNS issue. Resolution:
- In your Kubernetes cluster, run
kubeadm reset -fon the nodes. - In the management node, edit the
omnia_config.ymlfile to change the Kubernetes Pod Network CIDR. Suggested IP range is 192.168.0.0/16 and ensure you provide an IP which is not in use in your host network. - Execute omnia.yml and skip slurm using _skip tag slurm.
- In your Kubernetes cluster, run
Limitations
- Removal of Slurm and Kubernetes component roles are not supported. However, skip tags can be provided at the start of installation to select the component roles.
- After the installation of the Omnia appliance, changing the manager node is not supported. If you need to change the manager node, you must redeploy the entire cluster.
- Dell Technologies provides support to the Dell developed modules of Omnia. All the other third-party tools deployed by Omnia are outside the support scope.
To change the Kubernetes single node cluster to a multi-node cluster or to change a multi-node cluster to a single node cluster, you must either redeploy the entire cluster or run
kubeadm reset -fon all the nodes of the cluster. You then need to runomnia.ymlfile and skip the installation of Slurm using the skip tags.Contributing to Omnia
The Omnia project was started to give members of the Dell Technologies HPC Community a way to easily setup clusters of Dell EMC servers, and to contribute useful tools, fixes, and functionality back to the HPC Community.
Open to All
While we started Omnia within the Dell Technologies HPC Community, that doesn't mean that it's limited to Dell EMC servers, networking, and storage. This is an open project, and we want to encourage everyone to use and contribute to Omnia!
Anyone can contribute!
It's not just new features and bug fixes that can be contributed to the Omnia project! Anyone should feel comfortable contributing. We are asking for all types of contributions:
- New feature code
- Bug fixes
- Documentation updates
- Feature suggestions
- Feedback
- Validation that it works for your particular configuration
If you would like to contribute, see [CONTRIBUTORS](https://github.com/dellhpc/omnia/b