|
|
@@ -0,0 +1,768 @@
|
|
|
+{
|
|
|
+ "cells": [
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "# TLT Image Classification \n",
|
|
|
+ "---\n",
|
|
|
+ "## Learning Objectives\n",
|
|
|
+ "In this notebook, you will learn how to leverage the simplicity and convenience of TLT to:\n",
|
|
|
+ "\n",
|
|
|
+ "* Take a pretrained resnet18 model and finetune on a sample dataset converted from PascalVOC\n",
|
|
|
+ "* Prune the finetuned model\n",
|
|
|
+ "* Retrain the pruned model to recover lost accuracy\n",
|
|
|
+ "* Export the pruned model\n",
|
|
|
+ "* Run Inference on the trained model\n",
|
|
|
+ "* Export the pruned and retrained model to a .etlt file for deployment to DeepStream\n",
|
|
|
+ "\n",
|
|
|
+ "### Table of Contents\n",
|
|
|
+ "This notebook shows an example use case for classification using the Transfer Learning Toolkit.\n",
|
|
|
+ "\n",
|
|
|
+ "0. [Set up env variables](#head-0)\n",
|
|
|
+ "1. [Prepare dataset and pretrained model](#head-1)\n",
|
|
|
+ " 1. [Split the dataset into train/test/val](#head-1-1)\n",
|
|
|
+ " 2. [Download pre-trained model](#head-1-2)\n",
|
|
|
+ "2. [Provide training specfication](#head-2)\n",
|
|
|
+ "3. [Run TLT training](#head-3)\n",
|
|
|
+ "4. [Evaluate trained models](#head-4)\n",
|
|
|
+ "5. [Prune trained models](#head-5)\n",
|
|
|
+ "6. [Retrain pruned models](#head-6)\n",
|
|
|
+ "7. [Testing the model](#head-7)\n",
|
|
|
+ "8. [Visualize inferences](#head-8)\n",
|
|
|
+ "9. [Export and Deploy!](#head-9)\n",
|
|
|
+ " 1. [Int8 Optimization](#head-9-1)\n",
|
|
|
+ " 2. [Generate TensorRT engine](#head-9-2)"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "# Transfer Learning with TLT\n",
|
|
|
+ "\n",
|
|
|
+ "Transfer learning is the process of transferring learned features from one application to another. It is a commonly used training technique where you use a model trained on one task and re-train to use it on a different task. \n",
|
|
|
+ "\n",
|
|
|
+ "Transfer Learning Toolkit (TLT) is a simple and easy-to-use Python based AI toolkit for taking purpose-built AI models and customizing them with users' own data.\n",
|
|
|
+ "\n",
|
|
|
+ "<img align=\"center\" src=\"https://developer.nvidia.com/sites/default/files/akamai/embedded-transfer-learning-toolkit-software-stack-1200x670px.png\" width=\"720\"> "
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
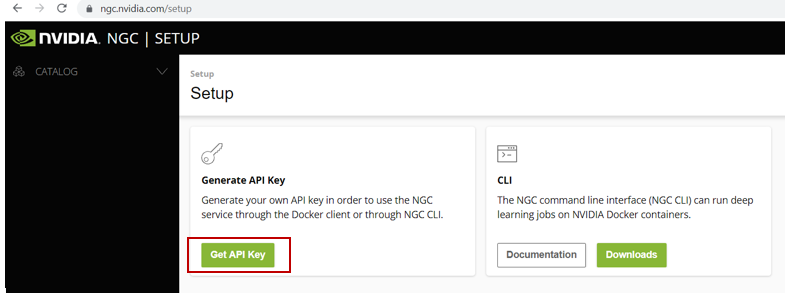
+ "Before TLT can be use, you need to register at ngc.nvidia.com and proceed to generate an API Key. A step-by-step process to achieving this is given below:\n",
|
|
|
+ "- From your browser visit `ngc.nvidia.com`\n",
|
|
|
+ "- Click on `Welcome Guest` and you would see a dropdown menu and then click on `Sign In/Sign Up`. \n",
|
|
|
+ "- Click on `continue` button where `NVIDIA Account (use existing or create a new NVIDIA ac-)` is written.\n",
|
|
|
+ "- Click on `Create account` and get registered. Thereafter you may proceed to login with your new account credentials.\n",
|
|
|
+ "- At the top right corner, click on your `username`, you would see a dropdown menu, then click on `Setup`.\n",
|
|
|
+ "- proceed and click on `Get API Key` button.\n",
|
|
|
+ "- Next, you would find at the top right corner a `Generate API Key` button, click on this button. A dialog box would appear after the click, you must click on the `confirm` button on it.\n",
|
|
|
+ "- Finally, copy your generated API Key and Username, and save it somewhere on your local system.\n",
|
|
|
+ "\n",
|
|
|
+ "<img align=\"center\" src=\" image/ngc_setup_key.PNG\" width=\"600\"> \n",
|
|
|
+ "<img align=\"center\" src=\" image/ngc_key.PNG\" width=\"700\">\n",
|
|
|
+ "\n",
|
|
|
+ "## API Key\n",
|
|
|
+ "\n",
|
|
|
+ "- Your API key represents your credentials\n",
|
|
|
+ " - Used for programmatic interaction (e.g., docker, REST API, etc.)\n",
|
|
|
+ " - Uniquely identifies you (think “Username & Password”)\n",
|
|
|
+ " - There can be only one (regenerating your API key invalidates the old one)\n",
|
|
|
+ "- Programmatic interface at `nvcr.io`: Use API Key"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "## 0. Setup env variables <a class=\"anchor\" id=\"head-0\"></a>\n",
|
|
|
+ "\n",
|
|
|
+ "Please copy your API Key from where you saved it and paste it within the empty single quote in front of `%env KEY=''`."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "%env USER_EXPERIMENT_DIR=/workspace/tlt-experiments/classification\n",
|
|
|
+ "%env DATA_DOWNLOAD_DIR=/workspace/tlt-experiments/data\n",
|
|
|
+ "#%env SPECS_DIR=/workspace/tlt-experiments/classification/specs\n",
|
|
|
+ "%env SPECS_DIR=/workspace/tlt-experiments/specs\n",
|
|
|
+ "%env KEY='aWNydmQ5bGRjNmppcDdoOTUwMGxuMHYzaWQ6MzFkYWI4ZTItYTEwZi00YTY4LWE5NTctYzJkNjQwMjUwMDdk'\n",
|
|
|
+ "#%env KEY=''"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "## 1. Prepare datasets and pre-trained model <a class=\"anchor\" id=\"head-1\"></a>"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "We will be using the pascal VOC dataset for the tutorial. To find more details please visit \n",
|
|
|
+ "http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html#devkit. if you intend to run this notebook on your local workstation, Please download the dataset present at http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar to $DATA_DOWNLOAD_DIR or `workspace/tlt-experiments/data`."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "# Check that file is present\n",
|
|
|
+ "import os\n",
|
|
|
+ "DATA_DIR = os.environ.get('DATA_DOWNLOAD_DIR')\n",
|
|
|
+ "if not os.path.isfile(os.path.join(DATA_DIR , 'VOCtrainval_11-May-2012.tar')):\n",
|
|
|
+ " print('tar file for dataset not found. Please download.')\n",
|
|
|
+ "else:\n",
|
|
|
+ " print('Found dataset.')"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "# unpack \n",
|
|
|
+ "!tar -xvf $DATA_DOWNLOAD_DIR/VOCtrainval_11-May-2012.tar -C $DATA_DOWNLOAD_DIR "
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "# verify\n",
|
|
|
+ "!ls $DATA_DOWNLOAD_DIR/VOCdevkit/VOC2012"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "### A. Split the dataset into train/val/test <a class=\"anchor\" id=\"head-1-1\"></a>"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "Pascal VOC Dataset is converted to our format (for classification) and then to train/val/test in the next two blocks."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "from os.path import join as join_path\n",
|
|
|
+ "import os\n",
|
|
|
+ "import glob\n",
|
|
|
+ "import re\n",
|
|
|
+ "import shutil\n",
|
|
|
+ "\n",
|
|
|
+ "DATA_DIR=os.environ.get('DATA_DOWNLOAD_DIR')\n",
|
|
|
+ "source_dir = join_path(DATA_DIR, \"VOCdevkit/VOC2012\")\n",
|
|
|
+ "target_dir = join_path(DATA_DIR, \"formatted\")\n",
|
|
|
+ "\n",
|
|
|
+ "\n",
|
|
|
+ "suffix = '_trainval.txt'\n",
|
|
|
+ "classes_dir = join_path(source_dir, \"ImageSets\", \"Main\")\n",
|
|
|
+ "images_dir = join_path(source_dir, \"JPEGImages\")\n",
|
|
|
+ "classes_files = glob.glob(classes_dir+\"/*\"+suffix)\n",
|
|
|
+ "for file in classes_files:\n",
|
|
|
+ " # get the filename and make output class folder\n",
|
|
|
+ " classname = os.path.basename(file)\n",
|
|
|
+ " if classname.endswith(suffix):\n",
|
|
|
+ " classname = classname[:-len(suffix)]\n",
|
|
|
+ " target_dir_path = join_path(target_dir, classname)\n",
|
|
|
+ " if not os.path.exists(target_dir_path):\n",
|
|
|
+ " os.makedirs(target_dir_path)\n",
|
|
|
+ " else:\n",
|
|
|
+ " continue\n",
|
|
|
+ " print(classname)\n",
|
|
|
+ "\n",
|
|
|
+ "\n",
|
|
|
+ " with open(file) as f:\n",
|
|
|
+ " content = f.readlines()\n",
|
|
|
+ "\n",
|
|
|
+ "\n",
|
|
|
+ " for line in content:\n",
|
|
|
+ " tokens = re.split('\\s+', line)\n",
|
|
|
+ " if tokens[1] == '1':\n",
|
|
|
+ " # copy this image into target dir_path\n",
|
|
|
+ " target_file_path = join_path(target_dir_path, tokens[0] + '.jpg')\n",
|
|
|
+ " src_file_path = join_path(images_dir, tokens[0] + '.jpg')\n",
|
|
|
+ " shutil.copyfile(src_file_path, target_file_path)"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "import os\n",
|
|
|
+ "import glob\n",
|
|
|
+ "import shutil\n",
|
|
|
+ "from random import shuffle\n",
|
|
|
+ "from tqdm import tqdm_notebook as tqdm\n",
|
|
|
+ "\n",
|
|
|
+ "DATA_DIR=os.environ.get('DATA_DOWNLOAD_DIR')\n",
|
|
|
+ "SOURCE_DIR=join_path(DATA_DIR, 'formatted')\n",
|
|
|
+ "TARGET_DIR=os.path.join(DATA_DIR,'split')\n",
|
|
|
+ "# list dir\n",
|
|
|
+ "dir_list = next(os.walk(SOURCE_DIR))[1]\n",
|
|
|
+ "# for each dir, create a new dir in split\n",
|
|
|
+ "for dir_i in tqdm(dir_list):\n",
|
|
|
+ " newdir_train = os.path.join(TARGET_DIR, 'train', dir_i)\n",
|
|
|
+ " newdir_val = os.path.join(TARGET_DIR, 'val', dir_i)\n",
|
|
|
+ " newdir_test = os.path.join(TARGET_DIR, 'test', dir_i)\n",
|
|
|
+ " \n",
|
|
|
+ " if not os.path.exists(newdir_train):\n",
|
|
|
+ " os.makedirs(newdir_train)\n",
|
|
|
+ " if not os.path.exists(newdir_val):\n",
|
|
|
+ " os.makedirs(newdir_val)\n",
|
|
|
+ " if not os.path.exists(newdir_test):\n",
|
|
|
+ " os.makedirs(newdir_test)\n",
|
|
|
+ "\n",
|
|
|
+ " img_list = glob.glob(os.path.join(SOURCE_DIR, dir_i, '*.jpg'))\n",
|
|
|
+ " # shuffle data\n",
|
|
|
+ " shuffle(img_list)\n",
|
|
|
+ "\n",
|
|
|
+ " for j in range(int(len(img_list)*0.7)):\n",
|
|
|
+ " shutil.copy2(img_list[j], os.path.join(TARGET_DIR, 'train', dir_i))\n",
|
|
|
+ "\n",
|
|
|
+ " for j in range(int(len(img_list)*0.7), int(len(img_list)*0.8)):\n",
|
|
|
+ " shutil.copy2(img_list[j], os.path.join(TARGET_DIR, 'val', dir_i))\n",
|
|
|
+ " \n",
|
|
|
+ " for j in range(int(len(img_list)*0.8), len(img_list)):\n",
|
|
|
+ " shutil.copy2(img_list[j], os.path.join(TARGET_DIR, 'test', dir_i))\n",
|
|
|
+ " \n",
|
|
|
+ "print('Done splitting dataset.')"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!ls $DATA_DOWNLOAD_DIR/split/test/cat"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "### B. Download pretrained models <a class=\"anchor\" id=\"head-1-2\"></a>"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "- View list of classification domain pretrained models"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {
|
|
|
+ "scrolled": true
|
|
|
+ },
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!ngc registry model list nvidia/tlt_pretrained_classification:*"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "- Create a folder named `pretrained_resnet18` where resnet18 model pulled from NGC would be stored"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!mkdir -p $USER_EXPERIMENT_DIR/pretrained_resnet18/"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "- Pull resnet18 pretrained model from NGC"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!ngc registry model download-version nvidia/tlt_pretrained_classification:resnet18 --dest $USER_EXPERIMENT_DIR/pretrained_resnet18"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "- Check that model is downloaded into directory"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!ls -l $USER_EXPERIMENT_DIR/pretrained_resnet18/tlt_pretrained_classification_vresnet18"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "## 2. Provide training specfication <a class=\"anchor\" id=\"head-2\"></a>\n",
|
|
|
+ "* Training dataset\n",
|
|
|
+ "* Validation dataset\n",
|
|
|
+ "* Pre-trained models\n",
|
|
|
+ "* Other training (hyper-)parameters such as batch size, number of epochs, learning rate etc."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "- Run the cell below to view the model spec configuration file. **Your task would be to modify the hyper-parameters to achieve desirable accuracy result**. You can access the `classification_spec.cfg` file in the `spec folder` seen at the top left-side of the jupyter lab. Please, remember to save the file with `ctl s` after modification and then rerun the cell below to see if your changes have reflected."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {
|
|
|
+ "scrolled": true
|
|
|
+ },
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!cat $SPECS_DIR/classification_spec.cfg"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "## 3. Run TLT training <a class=\"anchor\" id=\"head-3\"></a>\n",
|
|
|
+ "* Provide the sample spec file and the output directory location for models.\n",
|
|
|
+ "- Run the cell below to train on a **single GPU**. \n",
|
|
|
+ "- Please note some parameter definition: \n",
|
|
|
+ " - -e: `spec file`; -k: `API key encoding`; -r: `result directory`; --gpu_index: `index of GPU`; --init_epoch: `epoch number`"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!classification train -e $SPECS_DIR/classification_spec.cfg -r $USER_EXPERIMENT_DIR/output -k $KEY"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "- To run this training using **multiple GPUs**, please uncomment the cell below and update the `--gpus` parameter to the number of GPU's you wish to use. However, you are restricted to maximum of `2 GPUs` per teams on the cluster."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "#!classification train -e $SPECS_DIR/classification_spec.cfg \\\n",
|
|
|
+ "# -r $USER_EXPERIMENT_DIR/output \\\n",
|
|
|
+ "# -k $KEY --gpus 2"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "- To resume from a **checkpoint**, use `--init_epoch` along with your checkpoint configured in the spec file.\n",
|
|
|
+ "- Please make sure that the `model_path` in the spec file is now updated to the `.tlt` file of the corresponding\n",
|
|
|
+ " epoch you wish to resume from. You may choose from the files found under, `$USER_EXPERIMENT_DIR/output/weights` folder."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "# !classification train -e $SPECS_DIR/classification_spec.cfg \\\n",
|
|
|
+ "# -r $USER_EXPERIMENT_DIR/output \\\n",
|
|
|
+ "# -k $KEY --gpus 2 \\\n",
|
|
|
+ "# --init_epoch N"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "## 4. Evaluate trained models <a class=\"anchor\" id=\"head-4\"></a>\n",
|
|
|
+ "\n",
|
|
|
+ "In this step, we assume that the training is complete and the model from the final epoch (`resnet_080.tlt`) is available. If you would like to run evaluation on an earlier model, please edit the spec file at `$SPECS_DIR/classification_spec.cfg` to point to the intended model."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!classification evaluate -e $SPECS_DIR/classification_spec.cfg -k $KEY"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "## 5. Prune trained models <a class=\"anchor\" id=\"head-5\"></a>\n",
|
|
|
+ "* Specify pre-trained model\n",
|
|
|
+ "* Equalization criterion\n",
|
|
|
+ "* Threshold for pruning\n",
|
|
|
+ "* Exclude prediction layer that you don't want pruned (e.g. predictions)\n",
|
|
|
+ "\n",
|
|
|
+ "Usually, you just need to adjust `-pth` (threshold) for accuracy and model size trade off. Higher `pth` gives you smaller model (and thus higher inference speed) but worse accuracy. The threshold to use is depend on the dataset. A pth value 0.68 is just a starting point. If the retrain accuracy is good, you can increase this value to get smaller models. Otherwise, lower this value to get better accuracy."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "# Defining the checkpoint epoch number of the model to be used for the pruning.\n",
|
|
|
+ "# This should be lesser than the number of epochs training has been run for, incase training was interrupted earlier.\n",
|
|
|
+ "# By default, the default final model is at epoch 080.\n",
|
|
|
+ "%env EPOCH=080\n",
|
|
|
+ "!mkdir -p $USER_EXPERIMENT_DIR/output/resnet_pruned\n",
|
|
|
+ "!classification prune -m $USER_EXPERIMENT_DIR/output/weights/resnet_$EPOCH.tlt \\\n",
|
|
|
+ " -o $USER_EXPERIMENT_DIR/output/resnet_pruned/resnet18_nopool_bn_pruned.tlt \\\n",
|
|
|
+ " -eq union \\\n",
|
|
|
+ " -pth 0.6 \\\n",
|
|
|
+ " -k $KEY"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "print('Pruned model:')\n",
|
|
|
+ "print('------------')\n",
|
|
|
+ "!ls -r1t $USER_EXPERIMENT_DIR/output/resnet_pruned"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "## 6. Retrain pruned models <a class=\"anchor\" id=\"head-6\"></a>\n",
|
|
|
+ "* Model needs to be re-trained to bring back accuracy after pruning\n",
|
|
|
+ "- Run the cell below to view the retrain spec configuration file. Your task would be to modify the hyper-parameters to achieve desirable accuracy result. You can access the `classification_retrain_spec.cfg` file in the `spec folder` seen at the top left-side of the jupyter lab. Please, remember to save the file with `ctl s` after modification and then rerun the cell below to see if your changes have reflected."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!cat $SPECS_DIR/classification_retrain_spec.cfg"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!classification train -e $SPECS_DIR/classification_retrain_spec.cfg \\\n",
|
|
|
+ " -r $USER_EXPERIMENT_DIR/output_retrain \\\n",
|
|
|
+ " -k $KEY"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "## 7. Testing the model! <a class=\"anchor\" id=\"head-7\"></a>\n",
|
|
|
+ "\n",
|
|
|
+ "In this step, we assume that the training is complete and the model from the final epoch (`resnet_080.tlt`) is available. If you would like to run evaluation on an earlier model, please edit the spec file at `$SPECS_DIR/classification_retrain_spec.cfg` to point to the intended model."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!classification evaluate -e $SPECS_DIR/classification_retrain_spec.cfg -k $KEY"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "## 8. Visualize Inferences <a class=\"anchor\" id=\"head-8\"></a>"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "To see the output results of our model on test images, we can use the `tlt-infer` tool. Note that using models trained for higher epochs will usually result in better results. First we'll run inference in single image mode."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "# Choosing a random test image from the test set.\n",
|
|
|
+ "import os\n",
|
|
|
+ "import random\n",
|
|
|
+ "\n",
|
|
|
+ "test_dataset = os.path.join(os.environ.get('DATA_DOWNLOAD_DIR'), 'split', 'test')\n",
|
|
|
+ "classes = [item for item in os.listdir(test_dataset) if os.path.isdir(os.path.join(test_dataset,item))]\n",
|
|
|
+ "class_under_test = random.choice(classes)\n",
|
|
|
+ "test_image_dir = os.path.join(test_dataset, class_under_test)\n",
|
|
|
+ "image_list = [os.path.join(test_image_dir, item) for item in os.listdir(test_image_dir)\n",
|
|
|
+ " if item.endswith('.jpg')]\n",
|
|
|
+ "os.environ['TEST_IMAGE'] = random.choice(image_list)\n",
|
|
|
+ "\n",
|
|
|
+ "print(\"Input image is from class: {}\".format(class_under_test))\n",
|
|
|
+ "print(\"Image path is: {}\".format(os.environ['TEST_IMAGE']))"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "- Defining the checkpoint epoch number to use for the subsequent steps. This should be lesser than the number of epochs training has been run for, incase training was interrupted earlier. By default, the default final model is at epoch 080.\n",
|
|
|
+ "- Please note some parameter definition:\n",
|
|
|
+ " - -m:`retrained model;` -e:`retrain spec file;` -cm: `classmap;` -k: `encoding key;` -b: `batch size;` -d: `test data dir` "
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "%env EPOCH=080"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!classification inference -e $SPECS_DIR/classification_retrain_spec.cfg \\\n",
|
|
|
+ " -m $USER_EXPERIMENT_DIR/output_retrain/weights/resnet_$EPOCH.tlt \\\n",
|
|
|
+ " -k $KEY -b 32 -i $TEST_IMAGE \\\n",
|
|
|
+ " -cm $USER_EXPERIMENT_DIR/output_retrain/classmap.json"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "We can also run inference in directory mode to run on a set of test images. "
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!classification inference -e $SPECS_DIR/classification_retrain_spec.cfg \\\n",
|
|
|
+ " -m $USER_EXPERIMENT_DIR/output_retrain/weights/resnet_$EPOCH.tlt \\\n",
|
|
|
+ " -k $KEY -b 32 -d $DATA_DOWNLOAD_DIR/split/test/person \\\n",
|
|
|
+ " -cm $USER_EXPERIMENT_DIR/output_retrain/classmap.json"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "This above cell also outputs a `results.csv` file in the same directory. We can use a simple python program in the cell below to see and the visualize the output of csv the file."
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "import matplotlib.pyplot as plt\n",
|
|
|
+ "from PIL import Image \n",
|
|
|
+ "import os\n",
|
|
|
+ "import csv\n",
|
|
|
+ "from math import ceil\n",
|
|
|
+ "\n",
|
|
|
+ "DATA_DIR = os.environ.get('DATA_DOWNLOAD_DIR')\n",
|
|
|
+ "csv_path = os.path.join(DATA_DIR, 'split', 'test', 'person', 'result.csv')\n",
|
|
|
+ "results = []\n",
|
|
|
+ "with open(csv_path) as csv_file:\n",
|
|
|
+ " csv_reader = csv.reader(csv_file, delimiter=',')\n",
|
|
|
+ " for row in csv_reader:\n",
|
|
|
+ " results.append((row[0], row[1]))\n",
|
|
|
+ "\n",
|
|
|
+ "w,h = 200,200\n",
|
|
|
+ "fig = plt.figure(figsize=(30,30))\n",
|
|
|
+ "columns = 5\n",
|
|
|
+ "rows = 1\n",
|
|
|
+ "for i in range(1, columns*rows + 1):\n",
|
|
|
+ " ax = fig.add_subplot(rows, columns,i)\n",
|
|
|
+ " img = Image.open(results[i][0])\n",
|
|
|
+ " img = img.resize((w,h), Image.ANTIALIAS)\n",
|
|
|
+ " plt.imshow(img)\n",
|
|
|
+ " ax.set_title(results[i][1], fontsize=40)"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "## 9. Export and Deploy! <a class=\"anchor\" id=\"head-9\"></a>"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!classification export \\\n",
|
|
|
+ " -m $USER_EXPERIMENT_DIR/output_retrain/weights/resnet_$EPOCH.tlt \\\n",
|
|
|
+ " -o $USER_EXPERIMENT_DIR/export/final_model.etlt \\\n",
|
|
|
+ " -k $KEY"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "print('Exported model:')\n",
|
|
|
+ "print('------------')\n",
|
|
|
+ "!ls -lh $USER_EXPERIMENT_DIR/export/"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "### A. Int8 Optimization <a class=\"anchor\" id=\"head-9-1\"></a>\n",
|
|
|
+ "Classification model supports int8 optimization for inference in TRT. Inorder to use this, we must calibrate the model to run 8-bit inferences. This involves 2 steps\n",
|
|
|
+ "\n",
|
|
|
+ "* Generate calibration tensorfile from the training data using tlt-int8-tensorfile\n",
|
|
|
+ "* Use tlt-export to generate int8 calibration table.\n",
|
|
|
+ "\n",
|
|
|
+ "*Note: For this example, we generate a calibration tensorfile containing 10 batches of training data.\n",
|
|
|
+ "Ideally, it is best to use atleast 10-20% of the training data to calibrate the model.*"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "!tlt-int8-tensorfile classification -e $SPECS_DIR/classification_retrain_spec.cfg \\\n",
|
|
|
+ " -m 10 \\\n",
|
|
|
+ " -o $USER_EXPERIMENT_DIR/export/calibration.tensor"
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "code",
|
|
|
+ "execution_count": null,
|
|
|
+ "metadata": {},
|
|
|
+ "outputs": [],
|
|
|
+ "source": [
|
|
|
+ "# Remove the pre-existing exported .etlt file.\n",
|
|
|
+ "!rm -rf $USER_EXPERIMENT_DIR/export/final_model.etlt\n",
|
|
|
+ "!classification export \\\n",
|
|
|
+ " -m $USER_EXPERIMENT_DIR/output_retrain/weights/resnet_$EPOCH.tlt \\\n",
|
|
|
+ " -o $USER_EXPERIMENT_DIR/export/final_model.etlt \\\n",
|
|
|
+ " -k $KEY \\\n",
|
|
|
+ " --cal_data_file $USER_EXPERIMENT_DIR/export/calibration.tensor \\\n",
|
|
|
+ " --data_type int8 \\\n",
|
|
|
+ " --batches 10 \\\n",
|
|
|
+ " --cal_cache_file $USER_EXPERIMENT_DIR/export/final_model_int8_cache.bin \\\n",
|
|
|
+ " -v "
|
|
|
+ ]
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "cell_type": "markdown",
|
|
|
+ "metadata": {},
|
|
|
+ "source": [
|
|
|
+ "---\n",
|
|
|
+ "### Source\n",
|
|
|
+ "\n",
|
|
|
+ "This Notebook was adapted from examples within NVIDIA TLT container.\n",
|
|
|
+ "\n",
|
|
|
+ "### Licensing \n",
|
|
|
+ "\n",
|
|
|
+ "This material is released by OpenACC-Standard.org, in collaboration with NVIDIA Corporation, under the Creative Commons Attribution 4.0 International (CC BY 4.0)."
|
|
|
+ ]
|
|
|
+ }
|
|
|
+ ],
|
|
|
+ "metadata": {
|
|
|
+ "kernelspec": {
|
|
|
+ "display_name": "Python 3",
|
|
|
+ "language": "python",
|
|
|
+ "name": "python3"
|
|
|
+ },
|
|
|
+ "language_info": {
|
|
|
+ "codemirror_mode": {
|
|
|
+ "name": "ipython",
|
|
|
+ "version": 3
|
|
|
+ },
|
|
|
+ "file_extension": ".py",
|
|
|
+ "mimetype": "text/x-python",
|
|
|
+ "name": "python",
|
|
|
+ "nbconvert_exporter": "python",
|
|
|
+ "pygments_lexer": "ipython3",
|
|
|
+ "version": "3.8.5"
|
|
|
+ }
|
|
|
+ },
|
|
|
+ "nbformat": 4,
|
|
|
+ "nbformat_minor": 4
|
|
|
+}
|

 Tosin Akinwale Adesuyi
Tosin Akinwale Adesuyi
{kind=link}
{kind=link}