{
"cells": [
{
"cell_type": "markdown",
"id": "basic-position",
"metadata": {},
"source": [
"## Custom Data Cleaning\n",
"---\n",
"\n",
"## Learning Objectives\n",
"\n",
"Big langauge model is sampling efficient, which implies that if the data fed to the model were full of misspelled words, vulgar by nature ( This is often the case with uncensored data extracted from web forums/chat rooms), contain large volume of other langauges than the target langauge, or were having undesired and mischievous characteristic. It is strongly recommanded to consider a pipeline to clean and filter the data.\n",
"\n",
"Since Megatron-LM will sample sentences from documents during training run, we also need to construct a mechanism to find sentence boundary per document.\n",
"\n",
"As is for data deduplication, this notebook offers one way, there are many other ways, to deduplicate the data on document level, base on a similarity threshold. \n",
"Why is it important ? Let's take newspaper for example, imagine, a catastrophic event such as tsunami occured in Thailand which claimed many lives, such event could be reported repeatedly in a great many number of news articles all over the world. Wouldn't we want to deduplicate the almost identical news articles, with a good similarity measuring mechanism ?\n",
"\n",
"Similarily, when we blend datasets from a variety of sources in order to obtain big data for training big langauge model, we would want to have a way to deduplicate the repeated documents which are present across the collected datasets.\n",
"\n",
"\n",
"Therefore, the goal of this lab is to provide some basic tools for cleaning and filtering data which should be carefully applied to custom langauge datasets, and preserve the inherit charateristics in the datasets. \n",
"\n",
"In particular, this notebook covers the following steps :\n",
"\n",
" 1. Langauge Detection. \n",
" 2. Find sentence boundaries.\n",
" 3. Deduplicate documents based on similarity score.\n",
"Note: The method recommanded in the [Megatron-LM repo, namely LSH](https://github.com/NVIDIA/Megatron-LM/tree/main/tools/openwebtext) will be used for deduplication.\n",
"\n",
"What this notebook will _NOT_ cover :\n",
"\n",
" - Constructing a black-list to block and filter out inappropriate words/sentences/document.\n",
" - Clean empty lines or empty sentences.\n",
" Note : This can be done in many ways, for example, using sed or awk commands.\n",
" - Spell-check words and punctuations.\n",
" - Remove sentences/documents with too few tokens.\n",
" and many more customized data cleaning methods which one should consider adding to the data cleaning pipelins.\n",
"\n",
"At the end, there will be a [**mini-challenge**](./Lab2-2_SentenceBoundary_and_Deduplicate.ipynb#Mini-Challenge) for hands-on practicing identifying the numbers of duplicated documents as close as you can be comparing to the ground truth!"
]
},
{
"cell_type": "markdown",
"id": "mathematical-insert",
"metadata": {},
"source": [
"---\n",
"We will start by installing all the python libraries we need.\n",
"\n",
"In case you encounter problems of installing LSH, here is the fix :\n",
"\n",
" Install LSH - \n",
"\n",
" Follow instruction from [Megatron-LM/tools/openwebtext/README](https://github.com/NVIDIA/Megatron-LM/tree/main/tools/openwebtext) in openwebtext clearning folder \n",
"\n",
" Note : In a restricted environment where sudo is not allowed, please follow the below instruction to modify installation.\n",
" \n",
" Call out a terminal as illustrated below. \n",
" 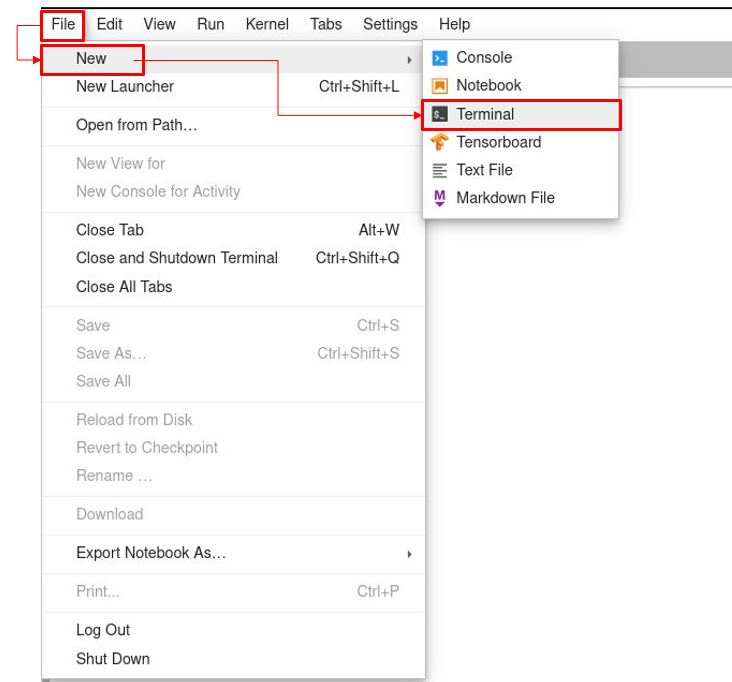\n",
" \n",
" cd gpubootcamp/ai/Megatron/English/Python/jupyter_notebook/Megatron-LM/tools/openwebtext/\n",
" \n",
" git clone https://github.com/mattilyra/LSH.git\n",
" cd LSH\n",
" pip install -U --user cython>=0.24.1\n",
" open setup.py in an editor and modify as below\n",
" \n",
"\n",
" python setup.py install --user "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "reliable-circle",
"metadata": {},
"outputs": [],
"source": [
"!pip install ftfy langdetect numpy torch pandas nltk sentencepiece boto3 tqdm regex bs4 htmlmin tldextract sentence-splitter"
]
},
{
"cell_type": "markdown",
"id": "liquid-speaking",
"metadata": {},
"source": [
"1. Langauge Detection "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "false-drunk",
"metadata": {},
"outputs": [],
"source": [
"from langdetect import detect\n",
"swe_raw_text='Under fredagsförmiddagen höll polis och räddningstjänst presskonferens tillsammans med en representanter från flygplatsens egna räddningsenhet och Örebro kommun.'\n",
"detect(swe_raw_text)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "quiet-price",
"metadata": {},
"outputs": [],
"source": [
"danish_text='1. januar 2021 var folketallet 5.840.045. Ved den første folketælling i 1735 var der 718.000 danskere.'\n",
"detect(danish_text)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "thirty-huntington",
"metadata": {},
"outputs": [],
"source": [
"finnish_text='Jokaisella on oikeus vapaasti osallistua yhteiskunnan sivistyselämään, nauttia taiteista sekä päästä osalliseksi tieteen edistyksen mukanaan tuomista eduista.'\n",
"detect(finnish_text)"
]
},
{
"cell_type": "markdown",
"id": "announced-wiring",
"metadata": {},
"source": [
"Once we have a way to identify which langauge does this document belong to, we can then filter or remove the documents at will and keep only the selected language(s)."
]
},
{
"cell_type": "markdown",
"id": "rising-sleeve",
"metadata": {},
"source": [
"2. Find sentence boundaries - alternative 1 : NLTK"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "infrared-charity",
"metadata": {},
"outputs": [],
"source": [
"import nltk\n",
"nltk.download('punkt')"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "threaded-placement",
"metadata": {},
"outputs": [],
"source": [
"import nltk\n",
"from nltk.tokenize import sent_tokenize\n",
"text='Detta är ett stycke. Den innehåller flera meningar. “Men varför”, frågar du? Andersson pekas ut som nästa partiledare: “Medlemmarna ska säga sitt”'\n",
"print(\"original doc is :\\n \", text)\n",
"sents=sent_tokenize(text)\n",
"i=0\n",
"for sent in sents:\n",
" print(\"------- sentence {} -------\".format(str(i))) \n",
" print(sent)\n",
" i+=1"
]
},
{
"cell_type": "markdown",
"id": "perceived-hollow",
"metadata": {},
"source": [
"Below is the expected outputs :\n",
"\n",
"Observe how NLTK tokenizer sentence per given document :\n",
"\n",
" ------- sentence 0 -------\n",
" Detta är ett stycke.\n",
" ------- sentence 1 -------\n",
" Den innehåller flera meningar.\n",
" ------- sentence 2 -------\n",
" “Men varför”, frågar du?\n",
" ------- sentence 3 -------\n",
" Andersson pekas ut som nästa partiledare: “Medlemmarna ska säga sitt”"
]
},
{
"cell_type": "markdown",
"id": "bound-banks",
"metadata": {},
"source": [
"2. Find sentence boundaries - alternative 2 : NLTK + custom function "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "thousand-smooth",
"metadata": {},
"outputs": [],
"source": [
"import re\n",
"import nltk\n",
"from nltk.tokenize import sent_tokenize\n",
"def normal_cut_sentence(temp):\n",
" return sent_tokenize(temp)\n",
"\n",
"def cut_sentence_with_quotation_marks(text):\n",
" p = re.compile(\"“.*?”\")\n",
" ls = []\n",
" index = 0\n",
" length = len(text)\n",
" for i in p.finditer(text):\n",
" temp = ''\n",
" start = i.start()\n",
" end = i.end()\n",
" for j in range(index, start):\n",
" temp += text[j]\n",
" if temp != '':\n",
" temp_list = normal_cut_sentence(temp)\n",
" ls += temp_list\n",
" temp = ''\n",
" for k in range(start, end):\n",
" temp += text[k]\n",
" if temp != ' ':\n",
" ls.append(temp)\n",
" index = end\n",
" return ls"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "brilliant-fireplace",
"metadata": {},
"outputs": [],
"source": [
"sents=cut_sentence_with_quotation_marks(text)\n",
"i=0\n",
"for sent in sents:\n",
" print(\"------- sentence {} -------\".format(str(i))) \n",
" print(sent)\n",
" i+=1"
]
},
{
"cell_type": "markdown",
"id": "balanced-darkness",
"metadata": {},
"source": [
"Below is the expected outputs :\n",
"\n",
"Observe how the custom function `cut_sentence_with_quotation_marks` modifies NLTK and adding quotation marks as an additional sentence-splitter :\n",
"\n",
" ------- sentence 0 -------\n",
" Detta är ett stycke.\n",
" ------- sentence 1 -------\n",
" Den innehåller flera meningar.\n",
" ------- sentence 2 -------\n",
" “Men varför”\n",
" ------- sentence 3 -------\n",
" , frågar du?\n",
" ------- sentence 4 -------\n",
" Andersson pekas ut som nästa partiledare:\n",
" ------- sentence 5 -------\n",
" “Medlemmarna ska säga sitt”\n",
" \n",
"There are many ways to split the sentence within a document, the above is just one example.\n",
"\n",
"One can construct other custom function to do sentence splitting with or without NLTK. "
]
},
{
"cell_type": "markdown",
"id": "average-token",
"metadata": {},
"source": [
"3. Deduplicate documents based on similarity score.\n",
"\n",
"[Local Sensitive Hash](http://snap.stanford.edu/class/cs246-2012/slides/03-lsh.pdf)\n",
"\n",
"First, we create shingles from the document with ngram, then fingerprints were created and Jaccard Similarity measured is used in order to find the top _K_ most similar items given pairs of documents based on an arbitrary threshold."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "opposed-national",
"metadata": {},
"outputs": [],
"source": [
"import itertools\n",
"from lsh import cache, minhash # https://github.com/mattilyra/lsh\n",
"from lsh import minhash\n",
"import pandas as pd\n",
"\n",
"# a pure python shingling function that will be used in comparing\n",
"# LSH to true Jaccard similarities\n",
"def shingles(text, char_ngram=5):\n",
" return set(text[head:head + char_ngram] for head in range(0, len(text) - char_ngram))\n",
"\n",
"\n",
"def jaccard(set_a, set_b):\n",
" intersection = set_a & set_b\n",
" union = set_a | set_b\n",
" return len(intersection) / len(union)\n",
"\n",
"\n",
"def candidate_duplicates(document_feed, char_ngram=5, seeds=100, bands=5, hashbytes=4):\n",
" char_ngram = char_ngram\n",
" sims = []\n",
" hasher = minhash.MinHasher(seeds=seeds, char_ngram=char_ngram, hashbytes=hashbytes)\n",
" if seeds % bands != 0:\n",
" raise ValueError('Seeds has to be a multiple of bands. {} % {} != 0'.format(seeds, bands))\n",
" \n",
" lshcache = cache.Cache(num_bands=bands, hasher=hasher)\n",
" for i_line, line in enumerate(document_feed):\n",
" line = line.decode('utf8')\n",
" docid, headline_text = line.split('\\t', 1)\n",
" fingerprint = hasher.fingerprint(headline_text.encode('utf8'))\n",
" \n",
" # in addition to storing the fingerpring store the line\n",
" # number and document ID to help analysis later on\n",
" lshcache.add_fingerprint(fingerprint, doc_id=(i_line, docid))\n",
"\n",
" candidate_pairs = set()\n",
" for b in lshcache.bins:\n",
" for bucket_id in b:\n",
" if len(b[bucket_id]) > 1:\n",
" pairs_ = set(itertools.combinations(b[bucket_id], r=2))\n",
" candidate_pairs.update(pairs_)\n",
" \n",
" return candidate_pairs"
]
},
{
"cell_type": "markdown",
"id": "strange-addition",
"metadata": {},
"source": [
"We want to verify how good this algorithm is, hence, we will hand-crafted duplications of documents from our toy data `extractedNVblogs.txt` obtained from`Lab1-1_Website_scrapping.ipynb`. We will flag the duplicated documents which we hand-crafted, in a column called `duplicate` and set the value to _True_ when the given two documents were identical and _False_ otherwise. This column will serve as the ground truth for us, we will use this hand-crafted data to verify whether this LSH algorithm will work as expected."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "instrumental-opening",
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd\n",
"cols=['doc1']\n",
"df=pd.read_csv('../../../../dataset/EN/extractedNVblogs.txt',sep='\\n', names=cols ,skiprows=1)\n",
"df.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "polish-identification",
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"def create_duplicates(df):\n",
" doc2=[]\n",
" duplicate=[]\n",
" n=len(df)\n",
" for i in range(n):\n",
" other_population=[k for k in range(n) if k!=i]\n",
" \n",
" other_idx=np.random.choice(other_population)\n",
" current_idx=np.random.choice([i,other_idx], p=[0.3,0.7])\n",
" if current_idx==i: \n",
" duplicate.append(True)\n",
" else:\n",
" duplicate.append(False)\n",
" doc2.append(df.iloc[current_idx,0])\n",
" df['index']=df.index\n",
" df['doc2']=doc2\n",
" df['duplicate']=duplicate\n",
" cols=['index','doc1','doc2','duplicate']\n",
" df=df[cols]\n",
" return df"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "twenty-unknown",
"metadata": {},
"outputs": [],
"source": [
"df2=create_duplicates(df)\n",
"df2.tail()"
]
},
{
"cell_type": "markdown",
"id": "fabulous-rubber",
"metadata": {},
"source": [
"Below is the expected outputs :\n",
" \n",
" \n",
" index \tdoc1 \tdoc2 \tduplicate\n",
" 65 \t65 \tThis post was updated July 20, 2021 to reflect... \tThis post was updated July 20, 2021 to reflect... \tTrue\n",
" 66 \t66 \tResearchers, developers, and engineers worldwi... \tThis post was originally published in August 2... \tFalse\n",
" 67 \t67 \tLooking to reveal secrets of days past, histor... \tThe NVIDIA Deep Learning Institute (DLI) exten... \tFalse\n",
" 68 \t68 \tScientists searching the universe for gravitat... \tRobotics researchers from NVIDIA and Universit... \tFalse\n",
" 69 \t69 \tAt GTC ’21, experts presented a variety of tec... \tThe NVIDIA Hardware Grant Program helps advanc... \tFalse"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "crazy-exhibition",
"metadata": {},
"outputs": [],
"source": [
"df2.duplicate.value_counts()"
]
},
{
"cell_type": "markdown",
"id": "colonial-vitamin",
"metadata": {},
"source": [
"Below is an example of the expected outputs :\n",
" \n",
" False 45 <--- the number might change here in your run.\n",
" True 25 <--- the number might change here in your run.\n",
" Name: duplicate, dtype: int64\n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "charming-melissa",
"metadata": {},
"outputs": [],
"source": [
"df2.columns"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "ordinary-leisure",
"metadata": {},
"outputs": [],
"source": [
"del df\n",
"keep_cols_to_write=['index','doc1','doc2']\n",
"df3=df2[keep_cols_to_write]\n",
"df3.head()"
]
},
{
"cell_type": "markdown",
"id": "unknown-tragedy",
"metadata": {},
"source": [
"Below is the expected outputs :\n",
"\n",
" index \tdoc1 \tdoc2\n",
" 0 \t0 \tDeep learning models have been successfully us... \tDeep learning models have been successfully us...\n",
" 1 \t1 \tBreast cancer is the most frequently diagnosed... \tIn NVIDIA Clara Train 4.0, we added homomorphi...\n",
" 2 \t2 \tThe NVIDIA Deep Learning Institute (DLI) exten... \tThe NVIDIA Deep Learning Institute (DLI) exten...\n",
" 3 \t3 \tEngineers, product developers and designers ar... \tDeep learning research requires working at sca...\n",
" 4 \t4 \tDespite substantial progress in natural langua... \tNVIDIA announces our newest release of the CUD..."
]
},
{
"cell_type": "markdown",
"id": "sound-government",
"metadata": {},
"source": [
"We could proceed to write the above dataframe to a csv file, however, for the sake of keeping determinism in our mini-challenge, we will use a deterministic dataset.\n",
"\n",
"**Note** : In order to preserve determinism, we will load the previously saved `HandCrafted_Duplicates.csv` file instead, so that all attendees have the exact same file to do mini-challenge with.\n",
"\n",
"The `HandCrafted_Duplicates.csv` file is therefore provided in this repo.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "patient-wednesday",
"metadata": {},
"outputs": [],
"source": [
"## We will now read in the HandCrafted_Duplicates.csv file and overwrite the df2 dataframe\n",
"df2=pd.read_csv('HandCrafted_Duplicates.csv', names=['index', 'doc1', 'doc2', 'duplicate'], skiprows=1)\n",
"df2.head()"
]
},
{
"cell_type": "markdown",
"id": "funded-bangladesh",
"metadata": {},
"source": [
"Below is the expected outputs , outputs should look exactly the same as below:\n",
"\n",
" index \tdoc1 \tdoc2 \tduplicate\n",
" 0 \t0 \tToday, NVIDIA announced new pretrained models ... \tAstrophysics researchers have long faced a tra... \tFalse\n",
" 1 \t1 \tThis post was updated July 20, 2021 to reflect... \tThis post was updated July 20, 2021 to reflect... \tTrue\n",
" 2 \t2 \tIn part 1 of this series, we introduced new AP... \tEdge computing has been around for a long time... \tFalse\n",
" 3 \t3 \tThe NVIDIA NGC team is hosting a webinar with ... \tThe NVIDIA NGC team is hosting a webinar with ... \tTrue\n",
" 4 \t4 \tNVIDIA announces our newest release of the CUD... \tAs an undergraduate student excited about AI f... \tFalse"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "catholic-pharmacology",
"metadata": {},
"outputs": [],
"source": [
"## this is our groundtruth, count duplicate == Truth is 31 \n",
"df2.duplicate.value_counts()"
]
},
{
"cell_type": "markdown",
"id": "democratic-sodium",
"metadata": {},
"source": [
"Below is the expected outputs , outputs should look exactly the same as below:\n",
"\n",
" False 42\n",
" True 31\n",
" Name: duplicate, dtype: int64"
]
},
{
"cell_type": "markdown",
"id": "alien-primary",
"metadata": {},
"source": [
"In below code block, we will test whether LSH can correctly identify the duplicated / Not duplicated pair of documents which we hand-crafted!"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "wooden-speed",
"metadata": {},
"outputs": [],
"source": [
"from lsh import minhash\n",
"import random\n",
"\n",
"# wrap the deduplication into a function \n",
"def duplicated_or_not(doc1,doc2,threshold=0.85):\n",
" avg=0\n",
" cnt=0\n",
" shingles_1 = [doc1[i:i+5] for i in range(len(doc1))][:-5] \n",
" shingles_2 = [doc2[i:i+5] for i in range(len(doc2))][:-5]\n",
" for _ in range(5):\n",
" hasher = minhash.MinHasher(seeds=100, char_ngram=5)\n",
" fingerprint0 = hasher.fingerprint(doc1.encode('utf8'))\n",
" fingerprint1 = hasher.fingerprint(doc2.encode('utf8'))\n",
" curr_avg=sum(fingerprint0[i] in fingerprint1 for i in range(hasher.num_seeds)) / hasher.num_seeds\n",
" avg+=curr_avg\n",
" cnt+=1\n",
" score= round(avg / cnt,5)\n",
" flag=True if score >=threshold else False\n",
" return flag, score\n",
"\n",
"\n",
"print(\" === Testing LSH with hand-crafted duplicated dataset ===\")\n",
"for idx in [0,1]: \n",
" truth=df2.iloc[idx,3]\n",
" doc1=df2.iloc[idx,1]\n",
" doc2=df2.iloc[idx,2]\n",
" flag, score=duplicated_or_not(doc1,doc2,threshold=0.85)\n",
" print(\"groundtruth is\", truth) \n",
" correct='Yes' if truth == flag else 'No'\n",
" LSH_identified_as = 'duplicates' if flag else 'Not duplicates'\n",
" print(\"LSH identify as {}, is it correct:{} , similarity score = {} \".format(LSH_identified_as,correct, score))\n",
" print(\"---\"*10)"
]
},
{
"cell_type": "markdown",
"id": "vanilla-jewel",
"metadata": {},
"source": [
"Expected outputs :\n",
"\n",
" === Testing LSH with hand-crafted duplicated dataset ===\n",
" groundtruth is False\n",
" LSH identify as Not duplicates, is it correct:Yes ,similarity score = 0.098 \n",
" ------------------------------\n",
" groundtruth is True\n",
" LSH identify as duplicates, is it correct:Yes ,similarity score = 1.0 \n",
"\n",
"Indeed, when given a hand-crafted pairs of documents, if they are identical, LSH will identify them correctly as duplicated/Not duplicates.\n",
"\n",
"Now that we know the algorithm LSH is working as expected. Let's now exercise our knowledge with a [mini-challenge](./Lab2-2_SentenceBoundary_and_Deduplicate.ipynb#Mini-Challenge). \n",
"\n",
"Note : The `groundtruth.txt` is simply `df2.csv` but removing the , headers, the label column _duplicate_ for faster processing."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "correct-sleep",
"metadata": {},
"outputs": [],
"source": [
"!wc -l groundtruth.txt"
]
},
{
"cell_type": "markdown",
"id": "wrong-diagram",
"metadata": {},
"source": [
"Below is the expected outputs , outputs should look exactly the same as below:\n",
"\n",
" 73 groundtruth.txt\n",
""
]
},
{
"cell_type": "markdown",
"id": "exciting-chile",
"metadata": {},
"source": [
"## Mini-Challenge\n",
"\n",
"Task : \n",
" You are only allowed to modify parameters within the `##### Begining/End of modifiable block ##### `, do _not_ modify anything else.\n",
" Overwrite the below parameters before calling `candidate_duplicates()` function, and rerun the cell block below.\n",
" \n",
" char_ngram= < input_value >\n",
" seeds=< input_value >\n",
" bands=< input_value >\n",
" hashbytes=< input_value >\n",
"\n",
"Pass : Consider yourself pass this mini challenge when you approach the number **31 +/- 3** ! \n",
"\n",
"\n",
"Re-run the below cell for experiments in order to get as close as possible to the ground truth = 31 duplicates.\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "serious-working",
"metadata": {},
"outputs": [],
"source": [
"## this is the Re Run Cell \n",
"import itertools\n",
"import random\n",
"lines = []\n",
"with open('groundtruth.txt', 'rb') as fh:\n",
" # read the first 1000 lines into memory so we can compare them\n",
" for line in itertools.islice(fh, 1000):\n",
" lines.append(line.decode('utf8'))\n",
" \n",
" # reset file pointer and do LSH\n",
" fh.seek(0)\n",
" feed = itertools.islice(fh, 1000)\n",
"\n",
" ##### Begining of the modifiable block #####\n",
" ## initial value given below, please modify them accordingly to obtain count of number of duplicates to be as close as 31 (= groundtruth)\n",
" char_ngram=13\n",
" seeds=100\n",
" bands=5\n",
" hashbytes=8\n",
" ##### End of modifiable block #####\n",
" candidates = candidate_duplicates(feed, char_ngram=char_ngram, seeds=seeds, bands=bands, hashbytes=hashbytes)\n",
"\n",
"# go over all the candidates comparing their similarities\n",
"similarities = []\n",
"for ((line_a, docid_a), (line_b, docid_b)) in candidates:\n",
" doc_a, doc_b = lines[line_a], lines[line_b]\n",
" shingles_a = shingles(lines[line_a])\n",
" shingles_b = shingles(lines[line_b])\n",
" hasher = minhash.MinHasher(seeds=seeds, char_ngram=char_ngram, hashbytes=hashbytes)\n",
" jaccard_sim = jaccard(shingles_a, shingles_b)\n",
" fingerprint_a = set(hasher.fingerprint(doc_a.encode('utf8')))\n",
" fingerprint_b = set(hasher.fingerprint(doc_b.encode('utf8')))\n",
" minhash_sim = len(fingerprint_a & fingerprint_b) / len(fingerprint_a | fingerprint_b)\n",
" similarities.append((docid_a, docid_b, jaccard_sim, minhash_sim))\n",
"\n",
"for a,b,jsim, msim in random.sample(similarities, k=2 ):\n",
" print(\"pair of similar sentences with jaccard_sim score:{} and minhash_sim score:{} --- \\n\".format(str(jsim),str(msim)))\n",
" a=int(a)\n",
" b=int(b)\n",
" text_a=df2.iloc[a,1]\n",
" text_b=df2.iloc[b,2]\n",
" if text_a==text_b:\n",
" print(\"100% duplicates \\n\")\n",
" print(\"text_a:\", text_a.split(' ')[:5])\n",
" print(\"text_b:\", text_b.split(' ')[:5])\n",
" print('-----'*10)\n",
" import random\n",
"\n",
"print('\\nThere are **{}** candidate duplicates in total\\n'.format(len(candidates)))\n",
"random.sample(similarities, k=1)"
]
},
{
"cell_type": "markdown",
"id": "likely-iceland",
"metadata": {},
"source": [
"Below is the expected outputs :\n",
"\n",
"A naive run\n",
"\n",
" pair of similar sentences with jaccard_sim score:0.8197797952482132 and minhash_sim score:0.639344262295082 --- \n",
"\n",
" text_a: ['The', 'NVIDIA,', 'Facebook,', 'and', 'TensorFlow']\n",
" text_b: ['Deep', 'learning', '(DL)', 'is', 'the']\n",
" --------------------------------------------------\n",
" pair of similar sentences with jaccard_sim score:0.9133693568066934 and minhash_sim score:0.8867924528301887 --- \n",
"\n",
" 100% duplicates \n",
"\n",
" text_a: ['The', 'first', 'post', 'in', 'this']\n",
" text_b: ['The', 'first', 'post', 'in', 'this']\n",
" --------------------------------------------------\n",
"\n",
" There are **3** candidate duplicates in total\n"
]
},
{
"cell_type": "markdown",
"id": "subject-russell",
"metadata": {},
"source": [
"WOW that is _way too low_ !!! We should have 31 duplicates. \n",
"\n",
"Let's try again!"
]
},
{
"cell_type": "markdown",
"id": "smooth-franklin",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"id": "sunset-egyptian",
"metadata": {},
"source": [
"Go back and rerun cell Jump to ReRun Cell\n",
"\n",
"Solution will be delivered to you at the end of the bootcamp !\n"
]
},
{
"cell_type": "markdown",
"id": "activated-price",
"metadata": {},
"source": [
"--- \n",
"## Links and Resources\n",
"Don't forget to check out additional resources such as [Language Detect](https://github.com/Mimino666/langdetect), [NLTK Sentence Tokenizer](https://www.nltk.org/api/nltk.tokenize.html) and [Local Sensitive Hashing](http://snap.stanford.edu/class/cs246-2012/slides/03-lsh.pdf)."
]
},
{
"cell_type": "markdown",
"id": "acknowledged-momentum",
"metadata": {},
"source": [
"-----\n",
"## HOME NEXT
\n"
]
},
{
"cell_type": "markdown",
"id": "contained-slovenia",
"metadata": {},
"source": [
"-----\n",
"\n",
"\n",
"## Licensing \n",
"\n",
"This material is released by OpenACC-Standard.org, in collaboration with NVIDIA Corporation, under the Creative Commons Attribution 4.0 International (CC BY 4.0). "
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.8"
}
},
"nbformat": 4,
"nbformat_minor": 5
}