{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[Previous Notebook](Part_2.ipynb)\n",
" \n",
" \n",
" \n",
" \n",
"[Home Page](../Start_Here.ipynb)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# CNN Primer and Keras 101 - Continued \n",
"\n",
"This notebook covers introduction to Convolutional Neural Networks, and it's terminologies.\n",
"\n",
"**Contents of the this Notebook:**\n",
"\n",
"- [Convolution Neural Networks ( CNNs )](#Convolution-Neural-Networks-(-CNNs-))\n",
"- [Why CNNs are good in Image related tasks? ](#Why-CNNs-are-good-in-Image-related-tasks?)\n",
"- [Implementing Image Classification using CNN's](#Implementing-Image-Classification-using-CNN's)\n",
"- [Conclusion](#Conclusion-:)\n",
"\n",
"\n",
"**By the end of this notebook you will:**\n",
"\n",
"- Understand how a Convolution Neural Network works\n",
"- Write your own CNN Classifier and train it."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Convolution Neural Networks ( CNNs ) \n",
"\n",
"Convolution Neural Networks are widely used in the field of Image Classification, Object Detection, and Face Recognition because they are very effective in reducing the number of parameters without losing on the quality of models.\n",
"\n",
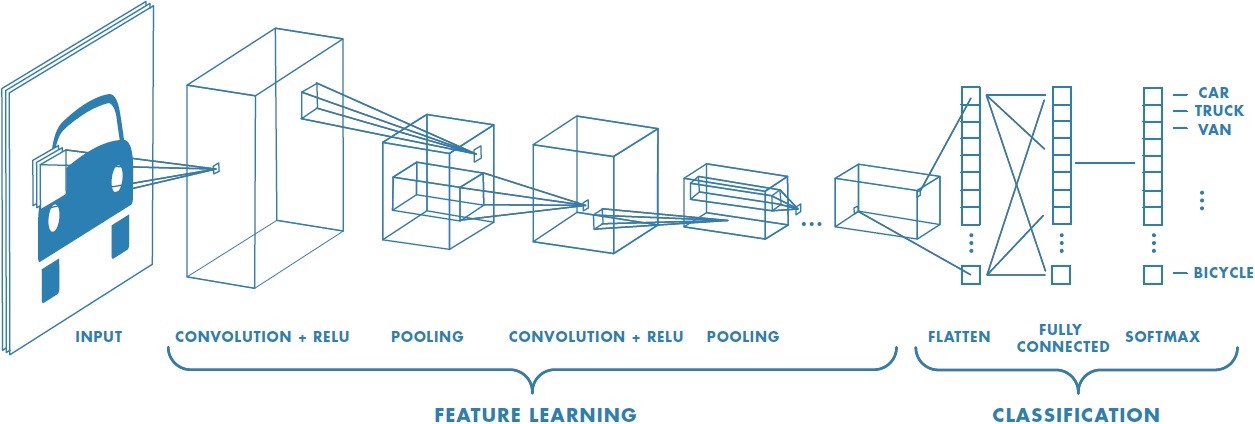
"Let's now understand what makes up a CNN Architecture and how it works : \n",
"\n",
"Here is an example of a CNN Architecture for a Classification task : \n",
"\n",
"\n",
"\n",
"*Source: https://fr.mathworks.com/solutions/deep-learning/convolutional-neural-network.html*\n",
"\n",
"Each input image will pass it through a series of convolution layers with filters (Kernels), pooling, fully connected layers (FC) and apply Softmax function to classify an object with probabilistic values between 0 and 1. \n",
"\n",
"Let us discuss in brief about the following in detail : \n",
"\n",
"- Convolution Layer \n",
"- Strides and Padding \n",
"- Pooling Layer\n",
"- Fully Connected Layer \n",
"\n",
"#### Convolution Layer : \n",
"\n",
"Convolution layer is the first layer to learn features from the input by preserving the relationships between neighbouring pixels. The Kernel Size is a Hyper-parameter and can be altered according to the complexity of the problem.\n",
"\n",
"Now that we've discussed Kernels. Let's see how a Kernel operates on the layer.\n",
"\n",
"\n",
"\n",
"*Source: https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53*\n",
"\n",
"We have seen how the convolution operation works, and now let us now see how convolution operation is carried out with multiple layers.\n",
"\n",
"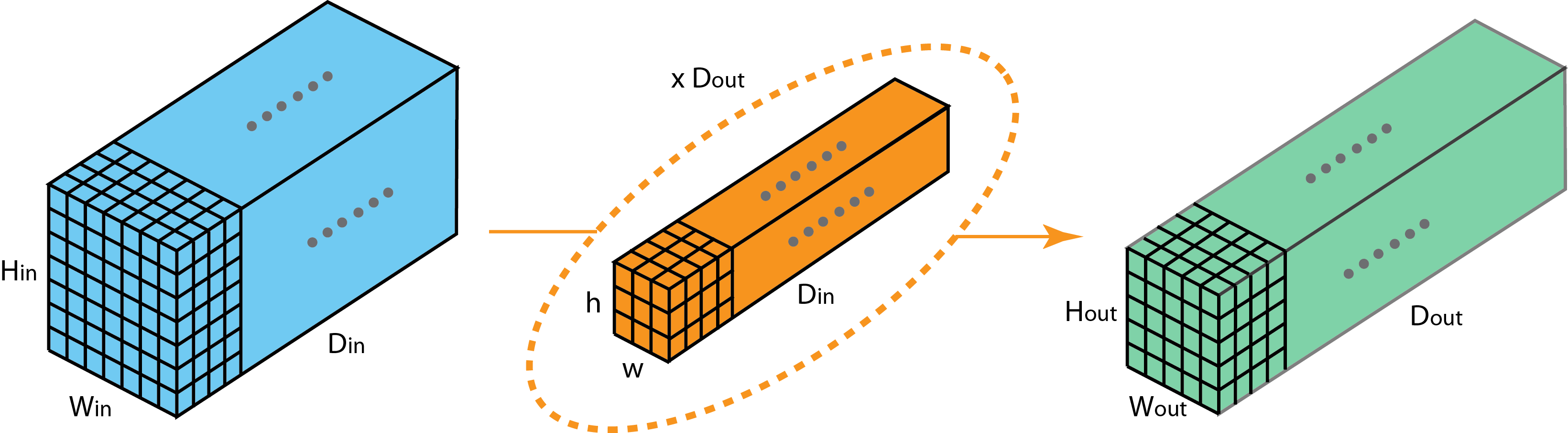\n",
"\n",
"*Source: https://towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e58215*\n",
"\n",
"\n",
"Let us define the terms :\n",
"\n",
"- Hin : Height dimension of the layer\n",
"- Win : Width dimension of the layer\n",
"- Din : Depth of the layer\n",
"- h : height of the kernel \n",
"- w : width of the kernal \n",
"- Dout : Number of kernels acting on the Layer \n",
"\n",
"Note : Din for the Layer and Kernel needs to be the same.\n",
"\n",
"Here the Din and Dout is also called as the number of channels of the layer. We can notice from the first image that typically the number of channels keeps increasing over the layers while the height and width keep decreasing. This is done so that the filters learn the features from the previous layers, they can also be called as feature channels.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"#### Strides and Padding \n",
"\n",
"Stride is the number of pixels shifts over the input matrix during convolution. When the stride is 1, then we move the filters to 1 pixel at a time. When the stride is 2, then we move the filters to 2 pixels at a time and so on. \n",
"\n",
"Sometimes filter do not fit perfectly on the input image. So, we have two options:\n",
"- Pad the picture with zeros (zero-padding) so that it fits\n",
"- Drop the part of the image where the filter did not fit. This is called valid padding which keeps only the valid part of the image.\n",
"\n",
"#### Pooling Layer :\n",
"\n",
"Pooling layers section would reduce the number of parameters when the images are too large. Spatial pooling also called subsampling or downsampling, which reduces the dimensionality of each map but retains important information. Spatial pooling can be of different types:\n",
"- Max Pooling :\n",
" - Max pooling is one of the common pooling used, and it takes the largest element from the rectified feature map.\n",
"- Average Pooling\n",
" - Taking the average of the elements is called Average pooling.\n",
"- Sum Pooling\n",
" - Sum of all elements in the feature map call is called as sum pooling.\n",
"\n",
"\n",
"\n",
"*Source: https://www.programmersought.com/article/47163598855/*\n",
"\n",
"#### Fully Connected Layer :\n",
"\n",
"We will then flatten the output from the convolutions layers and feed into it a _Fully Connected layer_ to generate a prediction. The fully connected layer is an ANN Model whose inputs are the features of the Inputs obtained from the Convolutions Layers. \n",
"\n",
"These Fully Connected Layers are then trained along with the _kernels_ during the training process.\n",
"\n",
"We will also be comparing later between CNN's and ANN's during our example to benchmark their results on Image Classification tasks.\n",
"\n",
"### Transposed Convolution :\n",
"\n",
"When we apply our Convolution operation over an image, we find that the number of channels increase while the height and width of the image decreases, now in some cases, for different applications we will need to up-sample our images, _Transposed convolution_ helps to up sample the images from these layers.\n",
"\n",
"Here is an animation to Tranposed convolution: \n",
"\n",
"\n",
"\n",
"  | \n",
"  | \n",
"
\n",
"\n",
"\n",
"*Source https://towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e58215*\n",
"\n",
"Tranposed Convolution can also be visualised as Convolution of a Layer with 2x2 padding as displayed in the right gif.\n",
"\n",
"\n",
"## Why CNNs are good in Image related tasks? \n",
"\n",
"1970, **David Marr** wrote a book called [vision](https://mitpress.mit.edu/books/vision).It was a breakthrough in understating of how the brain does vision; he stated that vision task is performed in a hierarchal manner. You start simple and get complex. For example, you start with as simple as identifying edge, colours and then build upon them to detect the object and then classify them and so on.\n",
"\n",
"The architecture of CNNs is designed as such to emulate the human brain's technique to deal with images. As convolutions are mainly used for extracting high-level features from the images such as edges/other patterns, these algorithms try to emulate our understanding of the vision. Certain filters do operations such as blurring the image, sharpening the image and then performing pooling operations on each of these filters to extract information from an image. As stated earlier, our understanding of vision consists that vision is a hierarchal process, and our brain deals with vision in a similar fashion. CNN also deals with understanding and classifying images similarly, thereby making them the appropriate choice for these kinds of tasks.\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Implementing Image Classification using CNN's\n",
"\n",
"We will the following the same steps for Data Pre-processing as mentioned in the previous Notebook : "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Import Necessary Libraries\n",
"\n",
"from __future__ import absolute_import, division, print_function, unicode_literals\n",
"\n",
"# TensorFlow and tf.keras\n",
"import tensorflow as tf\n",
"from tensorflow import keras\n",
"\n",
"# Helper libraries\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Let's Import the Dataset\n",
"fashion_mnist = keras.datasets.fashion_mnist\n",
"\n",
"(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()\n",
"\n",
"class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',\n",
" 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']\n",
"\n",
"#Print Array Size of Training Set \n",
"print(\"Size of Training Images :\"+str(train_images.shape))\n",
"#Print Array Size of Label\n",
"print(\"Size of Training Labels :\"+str(train_labels.shape))\n",
"\n",
"#Print Array Size of Test Set \n",
"print(\"Size of Test Images :\"+str(test_images.shape))\n",
"#Print Array Size of Label\n",
"print(\"Size of Test Labels :\"+str(test_labels.shape))\n",
"\n",
"#Let's See how our Outputs Look like \n",
"print(\"Training Set Labels :\"+str(train_labels))\n",
"#Data in the Test Set\n",
"print(\"Test Set Labels :\"+str(test_labels))\n",
"\n",
"train_images = train_images / 255.0\n",
"test_images = test_images / 255.0"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Further Data pre-processing : \n",
"\n",
"You may have noticed by now that the Training Set is of Shape `(60000,28,28)`.\n",
"\n",
"In CNN's, we need to feed the data in the form of a 4D Array as follows : \n",
"\n",
"`( Num_Images, X-dims, Y-dims, # of Channels of Image )`\n",
"\n",
"So, as our image is grayscale, we will reshape it to `(60000,28,28,1)` before passing it to our Architecture.\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Reshape input data from (28, 28) to (28, 28, 1)\n",
"w, h = 28, 28\n",
"train_images = train_images.reshape(train_images.shape[0], w, h, 1)\n",
"test_images = test_images.reshape(test_images.shape[0], w, h, 1)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Defining Convolution Layers\n",
"\n",
"Let us see how to define a Convolution Layer, MaxPooling Layer and Dropout \n",
"\n",
"\n",
"#### Convolution Layer \n",
"\n",
"We will be using the following API to define the Convolution Layer.\n",
"\n",
"```tf.keras.layers.Conv2D(filters, kernel_size, padding='valid', activation=None, input_shape)```\n",
"\n",
"\n",
"Let us define the parameters in brief :\n",
"\n",
"- Filters: The dimensionality of the output space (i.e. the number of output filters in the convolution).\n",
"- Kernel_size: An integer or tuple/list of 2 integers, specifying the height and width of the 2D convolution window. Can be a single integer to specify the same value for all spatial dimensions.\n",
"- Padding: one of \"valid\" or \"same\" (case-insensitive).\n",
"- Activation: Activation function to use (see activations). If you don't specify anything, no activation is applied (ie. \"linear\" activation: a(x) = x).\n",
"\n",
"Refer here for the Full Documentation -> [Convolutional Layers](https://keras.io/layers/convolutional/) \n",
"\n",
"#### Pooling Layer \n",
"\n",
"`tf.keras.layers.MaxPooling2D(pool_size=2)`\n",
"\n",
"- Pool size : Size of the max pooling windows.\n",
"\n",
"Keras Documentation -> [Pooling Layers](https://keras.io/layers/pooling/)\n",
"\n",
"#### Dropout \n",
"\n",
"Dropout is an approach to regularization in neural networks which helps reducing interdependent learning amongst the neurons.\n",
"\n",
"Simply put, dropout refers to ignoring units (i.e. neurons) during the training phase of certain set of neurons which is chosen at random. By “ignoring”, we mean these units are not considered during a particular forward or backward pass.\n",
"\n",
"It is defined by the following function :\n",
"\n",
"`tf.keras.layers.Dropout(0.3)`\n",
"\n",
"- Parameter : float between 0 and 1. Fraction of the input units to drop.\n",
"\n",
"Keras Documentation -> [Dropout](https://keras.io/layers/core/#dropout)\n",
"\n",
"## Defining our Model and Training \n",
"\n",
"Now that we are aware of the code for building a CNN , Let us now build a 5 Layer Model :\n",
"\n",
"- Input Layer : ( 28 , 28 ,1 ) \n",
" - Size of the Input Image\n",
"- Convolution layers :\n",
" - First Layer : Kernel Size ( 2x2 ) and we obtain 64 layers from it. \n",
" - Pooling of Size ( 2 x 2) making the layer to be ( 14 x 14 x 64 ) \n",
" - Second Layer : Kernel Size ( 2 x 2 ) and obtaining 32 layers.\n",
" - Pooling of Size ( 2 x 2 ) making the layer to be ( 7 x 7 x 32 )\n",
"- Fully Connected Layers : \n",
" - Flatten the Convolution layers to nodes of 1567 = ( 7 * 7 * 32 ) \n",
" - Dense Layer of 256 \n",
"- Output Layer : \n",
" - Densely Connected Layer with 10 classes with `softmax` activation\n",
" \n",
"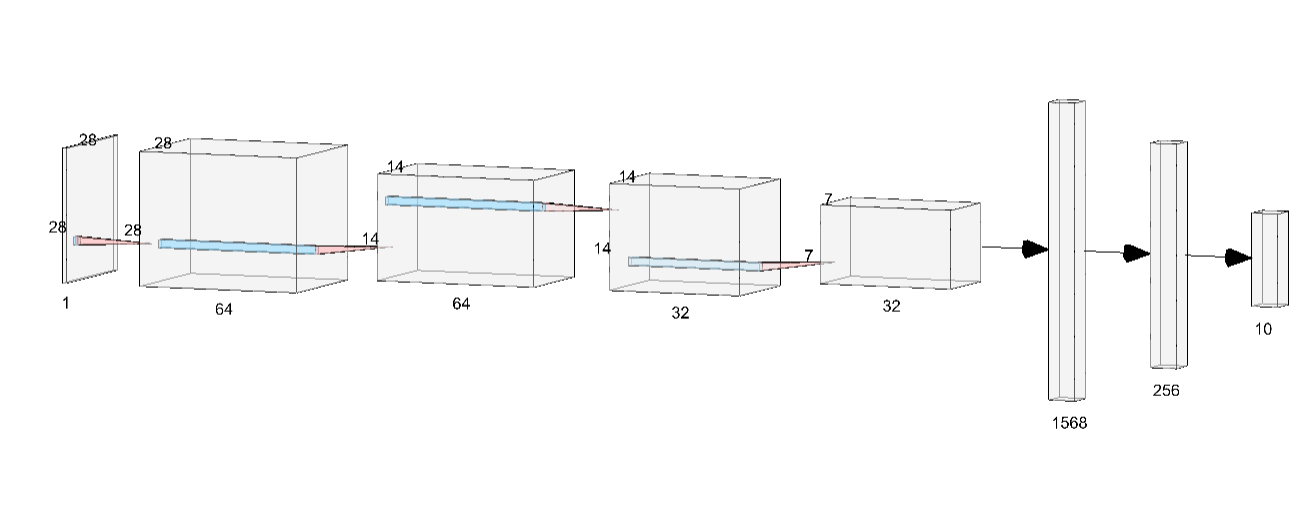\n",
" \n",
" Here , Let us now define our Model in Keras "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from tensorflow.keras import backend as K\n",
"import tensorflow as tf\n",
"K.clear_session()\n",
"model = tf.keras.Sequential()\n",
"\n",
"# Must define the input shape in the first layer of the neural network\n",
"model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1))) \n",
"model.add(tf.keras.layers.MaxPooling2D(pool_size=2))\n",
"# model.add(tf.keras.layers.Dropout(0.3))\n",
"#Second Convolution Layer\n",
"model.add(tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'))\n",
"model.add(tf.keras.layers.MaxPooling2D(pool_size=2))\n",
"model.add(tf.keras.layers.Dropout(0.3))\n",
"#Fully Connected Layer\n",
"model.add(tf.keras.layers.Flatten())\n",
"model.add(tf.keras.layers.Dense(256, activation='relu'))\n",
"model.add(tf.keras.layers.Dropout(0.5))\n",
"model.add(tf.keras.layers.Dense(10, activation='softmax'))\n",
"\n",
"# Take a look at the model summary\n",
"model.summary()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Compile the model\n",
"\n",
"Before the model is ready for training, it needs a few more settings. These are added during the model's *compile* step:\n",
"\n",
"* *Loss function* —This measures how accurate the model is during training. You want to minimize this function to \"steer\" the model in the right direction.\n",
"* *Optimizer* —This is how the model is updated based on the data it sees and its loss function.\n",
"* *Metrics* —Used to monitor the training and testing steps. The following example uses *accuracy*, the fraction of the images that are correctly classified."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model.compile(optimizer='adam',\n",
" loss='sparse_categorical_crossentropy',\n",
" metrics=['accuracy'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Train the model\n",
"\n",
"Training the neural network model requires the following steps:\n",
"\n",
"1. Feed the training data to the model. In this example, the training data is in the `train_images` and `train_labels` arrays.\n",
"2. The model learns to associate images and labels.\n",
"3. You ask the model to make predictions about a test set—in this example, the `test_images` array. Verify that the predictions match the labels from the `test_labels` array.\n",
"\n",
"To start training, call the `model.fit` method—so called because it \"fits\" the model to the training data:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model.fit(train_images, train_labels,batch_size=32 ,epochs=5)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#Evaluating the Model using the Test Set\n",
"\n",
"test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)\n",
"\n",
"print('\\nTest accuracy:', test_acc)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Making Predictions : "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Making Predictions from the test_images\n",
"\n",
"predictions = model.predict(test_images)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Reshape input data from (28, 28) to (28, 28, 1)\n",
"w, h = 28, 28\n",
"train_images = train_images.reshape(train_images.shape[0], w, h)\n",
"test_images = test_images.reshape(test_images.shape[0], w, h)\n",
"\n",
"\n",
"# Helper Functions to Plot Images \n",
"def plot_image(i, predictions_array, true_label, img):\n",
" predictions_array,true_label, img = predictions_array, true_label[i], img[i]\n",
" plt.grid(False)\n",
" plt.xticks([])\n",
" plt.yticks([])\n",
"\n",
" plt.imshow(img, cmap=plt.cm.binary)\n",
"\n",
" predicted_label = np.argmax(predictions_array)\n",
" if predicted_label == true_label:\n",
" color = 'blue'\n",
" else:\n",
" color = 'red'\n",
"\n",
" plt.xlabel(\"{} {:2.0f}% ({})\".format(class_names[predicted_label],\n",
" 100*np.max(predictions_array),\n",
" class_names[true_label]),\n",
" color=color)\n",
"\n",
"def plot_value_array(i, predictions_array, true_label):\n",
" predictions_array, true_label = predictions_array, true_label[i]\n",
" plt.grid(False)\n",
" plt.xticks(range(10))\n",
" plt.yticks([])\n",
" thisplot = plt.bar(range(10), predictions_array, color=\"#777777\")\n",
" plt.ylim([0, 1])\n",
" predicted_label = np.argmax(predictions_array)\n",
"\n",
" thisplot[predicted_label].set_color('red')\n",
" thisplot[true_label].set_color('blue')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Plot the first X test images, their predicted labels, and the true labels.\n",
"# Color correct predictions in blue and incorrect predictions in red.\n",
"num_rows = 5\n",
"num_cols = 3\n",
"num_images = num_rows*num_cols\n",
"plt.figure(figsize=(2*2*num_cols, 2*num_rows))\n",
"for i in range(num_images):\n",
" plt.subplot(num_rows, 2*num_cols, 2*i+1)\n",
" plot_image(i, predictions[i], test_labels, test_images)\n",
" plt.subplot(num_rows, 2*num_cols, 2*i+2)\n",
" plot_value_array(i, predictions[i], test_labels)\n",
"plt.tight_layout()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Conclusion : \n",
"\n",
"Running both our models for 5 Epochs here is a table comparing them : \n",
"\n",
"| Model | Train Accuracy | Train Loss | Test Accuracy | Test Loss |\n",
"|----------|-----------------|-------------|---------------|-----------|\n",
"| Fully connected Neural Networks -After 5 Epochs | 0.8923 | 0.2935 | 0.8731 | 0.2432| \n",
"| Convolution networks - After 5 Epochs | 0.8860| 0.3094 | 0.9048 | 0.1954 | \n",
"\n",
"\n",
"\n",
"Congrats on coming this far, now that you are introduced to Machine Learning and Deep Learning, you can get started on the Domain Specific Problem accessible through the Home Page.\n",
"\n",
"## Exercise \n",
"Play with different hyper-parameters ( Epoch, depth of layers , kernel size ... ) to bring down loss further\n",
"\n",
"## Important:\n",
"Shutdown the kernel before clicking on “Next Notebook” to free up the GPU memory."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"## Acknowledgements : \n",
"\n",
"\n",
"[Transposed Convolutions explained](https://medium.com/apache-mxnet/transposed-convolutions-explained-with-ms-excel-52d13030c7e8)\n",
"\n",
"[Why are CNNs used more for computer vision tasks than other tasks?](https://www.quora.com/Why-are-CNNs-used-more-for-computer-vision-tasks-than-other-tasks)\n",
"\n",
"[Comprehensive introduction to Convolution](https://towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e58215)\n",
"\n",
"## Licensing\n",
"This material is released by OpenACC-Standard.org, in collaboration with NVIDIA Corporation, under the Creative Commons Attribution 4.0 International (CC BY 4.0)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[Previous Notebook](Part_2.ipynb)\n",
" \n",
" \n",
" \n",
" \n",
"[Home Page](../Start_Here.ipynb)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}