Scaling is just resizing of the image. OpenCV comes with a function cv2.resize() for this purpose. The size of the image can be specified manually, or you can specify the scaling factor. Different interpolation methods are used. Preferable interpolation methods are cv2.INTER_AREA for shrinking and cv2.INTER_CUBIC (slow) & cv2.INTER_LINEAR for zooming. By default, interpolation method used is cv2.INTER_LINEAR for all resizing purposes.\n", "\n", "* cv2.INTER_AREA ( Preferable for Shrinking ) \n", "* cv2.INTER_CUBIC ( Preferable for Zooming but slow )\n", "* cv2.INTER_LINEAR ( Preferable for Zooming and the default option )\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Step 2 : Choosing a Random Patch from the Image\n", "\n", "We will use the `np.random.randint()` function from the Numpy toolbox to generate random numbers. The parameters of this function are the upper limits and size of the Output array as mentioned in the [Numpy Documentation](https://numpy.org/doc/stable/reference/random/generated/numpy.random.randint.html)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Wrapping things up" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "#Import numpy to Generate Random Numbers \n", "import numpy as np\n", "#Generate random number from [0,0] to [23,23] and define start and end points \n", "start_pt= np.random.randint(24,size=2)\n", "end_pt = start_pt + [232,232]\n", "# Scale Image and Take a Random patch from it\n", "img = cv2.resize(img,(256,256))\n", "rand = img[start_pt[0]:end_pt[0],start_pt[1]:end_pt[1]]\n", "plt.imshow(rand)" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "rand.shape" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "The output Of the final images is obtained as (232, 232, 3)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "# Annotating our dataset \n", "\n", "Let us start by taking an example of Katrina Hurricane from 2005 and scaling it for all the Cyclones" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "import pandas as pd\n", "# Read the CSV we saved earlier\n", "df = pd.read_csv('atlantic_storms.csv')\n", "# Create a Mask to Filter our Katrina Cyclone (2005)\n", "mask = (df['date'] > '2005-01-01') & (df['date'] <= '2006-01-01') & ( df['name'] == 'KATRINA')\n", "# Apply the Mask to the Original Data Frame and Extract the new Dataframe\n", "new_df = df.loc[mask]" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "new_df" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "#Getting the list of Images from Our Dataset for Katrina\n", "import os\n", "e = os.listdir('Dataset/tcdat/tc05/ATL/12L.KATRINA/ir/geo/1km')\n", "e.sort()\n", "#Show First five images\n", "e[:5]" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "#### We can observe, the images are taken once 30 minutes, but the text data is available once every 6 hours. So we will be interpolating the text data to fit the curve" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "#Get list of Dates and Velocity from the New Dataframe\n", "date_list = new_df['date'].tolist()\n", "velocity_list = new_df['maximum_sustained_wind_knots'].tolist()" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "print(date_list[:5])\n", "type(date_list[0])" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "The Dates are in STR Format which we will be converting now to datetime format to work with." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "from datetime import datetime\n", "# Get and Convert to Datetime format for the First Last recorded time of Text Data.\n", "first = (datetime.strptime(date_list[0], \"%Y-%m-%d %H:%M:%S\"))\n", "last = (datetime.strptime(date_list[-1], \"%Y-%m-%d %H:%M:%S\"))\n", "print(first)\n", "type(first)" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "#Changes the list from Convert everything to seconds from the first image to interpolate the data\n", "for i in range(len(date_list)):\n", " date_list[i]=( (datetime.strptime(date_list[i], \"%Y-%m-%d %H:%M:%S\")) - first ).total_seconds()\n", " print(date_list[i])" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# Interpolate using the Scipy Library Funciton\n", "from scipy import interpolate\n", "func = interpolate.splrep(date_list,velocity_list)" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "#Getting List of Katrina Images \n", "import os\n", "e = os.listdir('Dataset/tcdat/tc05/ATL/12L.KATRINA/ir/geo/1km')\n", "# Sort images by time\n", "e.sort()\n", "x=[]\n", "y=[]\n", "for m in e :\n", " try :\n", " #Strip the Time Data from image and convert it the a datetime type.\n", " time_img=(datetime.strptime(m[:13], \"%Y%m%d.%H%M\"))\n", " # If the Image is taken between the available text data\n", " if(time_img>=first and time_img <= last):\n", " # Get Interpolated Value for that time and Save It \n", " value = int(interpolate.splev((time_img-first).total_seconds(),func))\n", " x.append((time_img-first).total_seconds())\n", " y.append(value)\n", " except :\n", " pass " ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "import matplotlib.pyplot as plt\n", "# Plot All the Saved Data Points\n", "f = plt.figure(figsize=(24,10))\n", "ax = f.add_subplot(121)\n", "ax2 = f.add_subplot(122)\n", "ax.title.set_text('Datapoints frm csv file')\n", "ax2.title.set_text('Interpolated from CSV file to images')\n", "ax.plot(date_list,velocity_list,'-o')\n", "ax2.plot(x,y)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Now we have interpolated and found relevant velocity for all images between the recorded text timeframe. Let us now use it for training our Model." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "# Wrapping Things Up :" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Preparing the Dataset\n", "\n", "##### All the above modules are joined together and make It into a single function to load data" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "import sys\n", "sys.path.append('/workspace/python/source_code')\n", "# Import Utlility functions\n", "from utils import * \n", "# Load dataset\n", "filenames,labels = load_dataset()" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "val_filenames , val_labels = make_test_set(filenames,labels,val=0.1)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "# Understand our dataset :\n", "\n", "We can see the following lines from the Output : \n", "\n", "`[344, 344, 344, 344, 344, 344, 344, 344]` and `{2: 7936, 3: 5339, 1: 3803, 4: 2934, 5: 2336, 6: 2178, 7: 204, 0: 100}`\n", "\n", "This is the distribution of our validation set and training set over it's classes. \n", "\n", "For the validation set we use *Stratified Validation* set so that our validation set nearly respresent the whole class. \n" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "#Make train test set\n", "test = 0.2\n", "from sklearn.model_selection import train_test_split\n", "x_train, x_test, y_train, y_test = train_test_split(filenames, labels, test_size=test, random_state=1)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "# One-Hot Encoding \n", "\n", "`y_train` is a list containing data from 0-7 such as [ 2,4,5,....] but our Model Needs an Input of Array for Each Output as as 1D vector :\n", "\n", "2 --- > [ 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0] \n", "\n", "4 --- > [ 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0] \n", "\n", "\n", "This is encoded as such because keeping the other values 0 is necessary for the model to find the model Loss and use backpropagation for making it learn the _Weight Matrix_.\n", "\n", "The below given image is an example of One-Hot Encoding :\n", "\n", "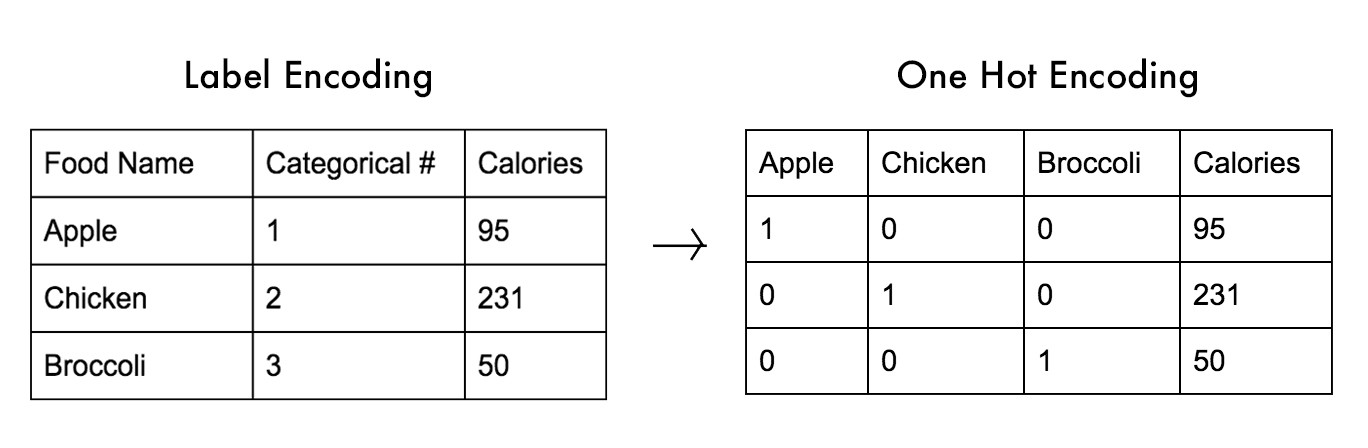\n", "\n", "Reference : [What is One Hot Encoding and How to Do It](https://medium.com/@michaeldelsole/what-is-one-hot-encoding-and-how-to-do-it-f0ae272f1179)" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "import tensorflow as tf\n", "y_train = tf.one_hot(y_train,depth=8)\n", "y_test = tf.one_hot(y_test,depth=8)\n", "val_labels = tf.one_hot(val_labels,depth=8)" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "train,test,val = make_dataset((x_train,y_train,128),(x_test,y_test,32),(val_filenames,val_labels,32))" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Defining our Model\n", "\n", "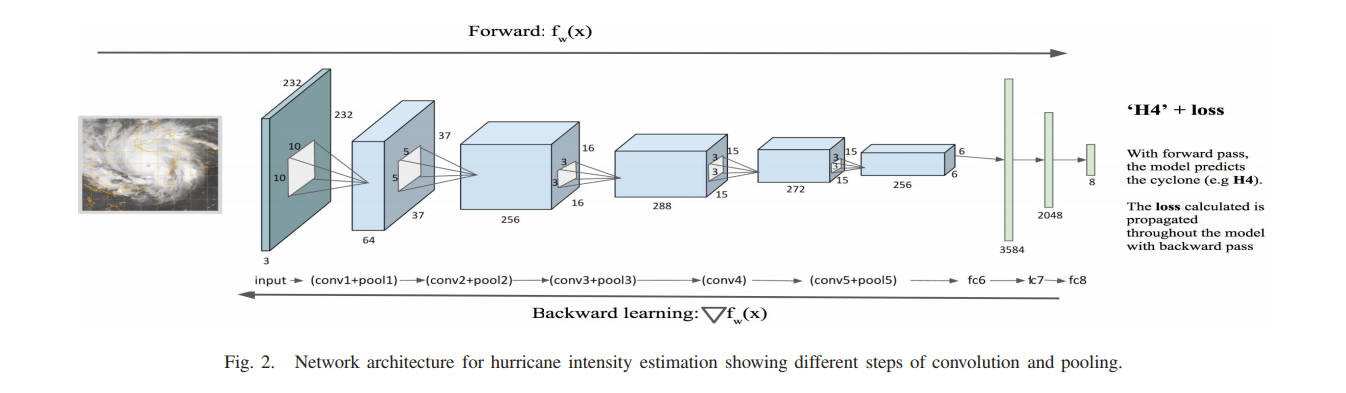\n", "\n", "We will be Implementing this model in Keras using the following code" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "import numpy as np\n", "import os\n", "\n", "os.environ[\"CUDA_VISIBLE_DEVICES\"]=\"0\"\n", "tf.random.set_seed(1337)\n", "\n", "import tensorflow.keras\n", "from tensorflow.keras.models import Sequential\n", "from tensorflow.keras.layers import Dense, Conv2D, Flatten ,Dropout, MaxPooling2D\n", "from tensorflow.keras import backend as K \n", "\n", "#Reset Graphs and Create Sequential model\n", "K.clear_session()\n", "model = Sequential()\n", "#Convolution Layers\n", "\n", "model.add(Conv2D(64, kernel_size=10,strides=3, activation='relu', input_shape=(232,232,3)))\n", "model.add(MaxPooling2D(pool_size=(3, 3),strides=2))\n", "model.add(Conv2D(256, kernel_size=5,strides=1,activation='relu'))\n", "model.add(MaxPooling2D(pool_size=(3, 3),strides=2))\n", "model.add(Conv2D(288, kernel_size=3,strides=1,padding='same',activation='relu'))\n", "model.add(MaxPooling2D(pool_size=(2, 2),strides=1))\n", "model.add(Conv2D(272, kernel_size=3,strides=1,padding='same',activation='relu'))\n", "model.add(Conv2D(256, kernel_size=3,strides=1,activation='relu'))\n", "model.add(MaxPooling2D(pool_size=(3, 3),strides=2))\n", "model.add(Dropout(0.5))\n", "model.add(Flatten())\n", "\n", "#Linear Layers \n", "\n", "model.add(Dense(3584,activation='relu'))\n", "model.add(Dense(2048,activation='relu'))\n", "model.add(Dense(8, activation='softmax'))\n", "\n", "# Print Model Summary\n", "\n", "model.summary()" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Compiling and Training our Model\n", "\n", "We will be using the following : \n", "\n", "- Optimizer : SGD ( Stochastic Gradient Descent ) with parameters mentioned in the research paper.\n", " - Learning Rate : 0.001\n", " - Momentum : 0.9\n", "- Loss Function : Categorical Cross Entropy ( Used in Multi-class classification ) \n", "- Metrics : We will be using two metrics to determine how our model performs \n", " - Accuracy : Number of Predictions correct / Total number of Predictions\n", " - Top -2 Accuracy : Top-2 accuracy means that any of your model 2 highest probability answers must match the expected answer.\n" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "import functools\n", "\n", "# Include Top-2 Accuracy Metrics \n", "top2_acc = functools.partial(tensorflow.keras.metrics.top_k_categorical_accuracy, k=2)\n", "top2_acc.__name__ = 'top2_acc'\n", "\n", "#Define Number of Epochs\n", "epochs = 4\n", "\n", "#But Training our model from scratch will take a long time\n", "#So we will load a partially trained model to speedup the process \n", "model.load_weights(\"trained_16.h5\")\n", "\n", "# Optimizer\n", "sgd = tensorflow.keras.optimizers.SGD(lr=0.001, decay=1e-6, momentum=0.9)\n", "\n", "\n", "#Compile Model with Loss Function , Optimizer and Metrics\n", "model.compile(loss=tensorflow.keras.losses.categorical_crossentropy, \n", " optimizer=sgd,\n", " metrics=['accuracy',top2_acc])\n", "\n", "# Train the Model \n", "trained_model = model.fit(train,\n", " epochs=epochs,\n", " verbose=1,\n", " validation_data=val)\n", "\n", "# Test Model Aganist Validation Set\n", "score = model.evaluate(test, verbose=0)\n", "print('Test loss:', score[0])\n", "print('Test accuracy:', score[1])" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Visualisations\n", "\n", "Let us now visualise how our model perfromed during the training process : " ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "import matplotlib.pyplot as plt\n", "f = plt.figure(figsize=(15,5))\n", "ax = f.add_subplot(121)\n", "ax.plot(trained_model.history['accuracy'])\n", "ax.plot(trained_model.history['val_accuracy'])\n", "ax.set_title('Model Accuracy')\n", "ax.set_ylabel('Accuracy')\n", "ax.set_xlabel('Epoch')\n", "ax.legend(['Train', 'Val'])\n", "\n", "ax2 = f.add_subplot(122)\n", "ax2.plot(trained_model.history['loss'])\n", "ax2.plot(trained_model.history['val_loss'])\n", "ax2.set_title('Model Loss')\n", "ax2.set_ylabel('Loss')\n", "ax2.set_xlabel('Epoch')\n", "ax2.legend(['Train', 'Val'],loc= 'upper left')\n", "\n", "plt.show()" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Confusion Matrix :\n", "\n", "A confusion matrix is a table that is often used to describe the performance of a classification model (or \"classifier\") on a set of test data for which the true values are known. \n", "\n", "Here , the rows display the predicted class and the columns are the truth value of the classes.From this we can estimate how our model performs over different classes which would in turn help us determine how our data should be fed into our model.\n", "\n", "\n" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "scrolled": false }, "outputs": [], "source": [ "import seaborn as sn\n", "from sklearn.metrics import confusion_matrix\n", "import pandas as pd\n", "\n", "#Plotting a heatmap using the confusion matrix\n", "pred = model.predict(val)\n", "p = np.argmax(pred, axis=1)\n", "y_valid = np.argmax(val_labels, axis=1, out=None)\n", "results = confusion_matrix(y_valid, p) \n", "classes=['NC','TD','TC','H1','H3','H3','H4','H5']\n", "df_cm = pd.DataFrame(results, index = [i for i in classes], columns = [i for i in classes])\n", "plt.figure(figsize = (15,15))\n", "\n", "sn.heatmap(df_cm, annot=True, cmap=\"Blues\")" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Congralutions on running your first model. Now In the next notebook , let us try to understand the drawbacks of this model and make it better :\n", "\n", "\n", "We can notice that the validation accuracy is lesser than the training accuracy. This is because the model is not properly Regularized and the possible reasons are : \n", "\n", "**Not enough data-points / Imbalanced classes**\n", "\n", "Using different techniques we will be regulating and normalising the model in the upcoming notebook.\n", "\n", "## Important:\n", "Shutdown the kernel before clicking on “Next Notebook” to free up the GPU memory.\n", "\n", "## Licensing\n", "This material is released by OpenACC-Standard.org, in collaboration with NVIDIA Corporation, under the Creative Commons Attribution 4.0 International (CC BY 4.0)." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "[Previous Notebook](Approach_to_the_Problem_&_Inspecting_and_Cleaning_the_Required_Data.ipynb)\n", " \n", " \n", " \n", " \n", "[1](The_Problem_Statement.ipynb)\n", "[2](Approach_to_the_Problem_&_Inspecting_and_Cleaning_the_Required_Data.ipynb)\n", "[3]\n", "[4](Countering_Data_Imbalance.ipynb)\n", "[5](Competition.ipynb)\n", " \n", " \n", " \n", " \n", "[Next Notebook](Countering_Data_Imbalance.ipynb)\n", "\n", " \n", " \n", " \n", " \n", " \n", " \n", "[Home Page](../Start_Here.ipynb)" ] } ], "metadata": { "kernelspec": { "display_name": "Python 3", "language": "python", "name": "python3" }, "language_info": { "codemirror_mode": { "name": "ipython", "version": 3 }, "file_extension": ".py", "mimetype": "text/x-python", "name": "python", "nbconvert_exporter": "python", "pygments_lexer": "ipython3", "version": "3.6.2" } }, "nbformat": 4, "nbformat_minor": 2 }