{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Getting Started with OpenACC"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In this lab you will learn the basics of using OpenACC to parallelize a simple application to run on multicore CPUs and GPUs. This lab is intended for C/C++ programmers. If you prefer to use Fortran, click [this link.](../../Fortran/jupyter_notebook/openacc_fortran_lab1.ipynb)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"Let's execute the cell below to display information about the GPUs running on the server by running the `nvaccelinfo` command, which ships with the NVIDIA HPC compiler that we will be using. To do this, execute the cell block below by giving it focus (clicking on it with your mouse), and hitting Ctrl-Enter, or pressing the play button in the toolbar above. If all goes well, you should see some output returned below the grey cell."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!nvaccelinfo"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The output of the above command will vary according to which GPUs you have in your system. For example, if you are running the lab on a machine with NVIDIA Tesla V100 GPUs, you might would see the following:\n",
"\n",
"```\n",
"CUDA Driver Version: 10010\n",
"NVRM version: NVIDIA UNIX x86_64 Kernel Module 418.87.01 Wed Sep 25 06:00:38 UTC 2019\n",
"\n",
"Device Number: 0\n",
"Device Name: Tesla V100-SXM2-16GB\n",
"Device Revision Number: 7.0\n",
"Global Memory Size: 16914055168\n",
"Number of Multiprocessors: 80\n",
"Concurrent Copy and Execution: Yes\n",
"Total Constant Memory: 65536\n",
"Total Shared Memory per Block: 49152\n",
"Registers per Block: 65536\n",
"Warp Size: 32\n",
"Maximum Threads per Block: 1024\n",
"Maximum Block Dimensions: 1024, 1024, 64\n",
"Maximum Grid Dimensions: 2147483647 x 65535 x 65535\n",
"Maximum Memory Pitch: 2147483647B\n",
"Texture Alignment: 512B\n",
"Clock Rate: 1530 MHz\n",
"Execution Timeout: No\n",
"Integrated Device: No\n",
"Can Map Host Memory: Yes\n",
"Compute Mode: default\n",
"Concurrent Kernels: Yes\n",
"ECC Enabled: Yes\n",
"Memory Clock Rate: 877 MHz\n",
"Memory Bus Width: 4096 bits\n",
"L2 Cache Size: 6291456 bytes\n",
"Max Threads Per SMP: 2048\n",
"Async Engines: 6\n",
"Unified Addressing: Yes\n",
"Managed Memory: Yes\n",
"Concurrent Managed Memory: Yes\n",
"Preemption Supported: Yes\n",
"Cooperative Launch: Yes\n",
" Multi-Device: Yes\n",
"Default Target: -ta=tesla:cc70\n",
"```\n",
"\n",
"This gives us lots of details about the GPU, for instance the device number, the type of device, and at the very bottom the command line argument we should use when targeting this GPU (see *_NVIDIA HPC Compiler Option_*). We will use this command line option a bit later to build for our GPU."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"## Introduction\n",
"\n",
"Our goal for this lab is to learn the first steps in accelerating an application with OpenACC. We advocate the following 3-step development cycle for OpenACC.\n",
" \n",
" \n",
"\n",
"**Analyze** your code to determine most likely places needing parallelization or optimization.\n",
"\n",
"**Parallelize** your code by starting with the most time consuming parts and check for correctness.\n",
"\n",
"**Optimize** your code to improve observed speed-up from parallelization.\n",
"\n",
"One should generally start the process at the top with the **analyze** step. For complex applications, it's useful to have a profiling tool available to learn where your application is spending its execution time and to focus your efforts there. The NVIDIA HPC Software Development Kit (SDK) comes with NVIDIA Nsight Systems/Compute for interactive HPC applications performance profiler. Since our example code is quite a bit simpler than a full application, we'll skip profiling the code and simply analyze the code by reading it. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Analyze the Code\n",
"\n",
"In the section below you will learn about the algorithm implemented in the example code and see examples pulled out of the source code. If you want a sneak peek at the source code, you can take a look at the files linked below or open the downloaded file.\n",
"\n",
"[jacobi.c](../source_code/lab1/jacobi.c) \n",
"[laplace2d.c](../source_code/lab1/laplace2d.c) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Code Description\n",
"\n",
"The code simulates heat distribution across a 2-dimensional metal plate. In the beginning, the plate will be unheated, meaning that the entire plate will be room temperature. A constant heat will be applied to the edge of the plate and the code will simulate that heat distributing across the plate over time. \n",
"\n",
"This is a visual representation of the plate before the simulation starts: \n",
" \n",
" \n",
" \n",
"We can see that the plate is uniformly room temperature, except for the top edge. Within the [laplace2d.c](../source_code/lab1/laplace2d.c) file, we see a function called **`initialize`**. This function is what \"heats\" the top edge of the plate. \n",
" \n",
"```cpp\n",
"void initialize(double *restrict A, double *restrict Anew, int m, int n) \n",
"{ \n",
" memset(A, 0, n * m * sizeof(double)); \n",
" memset(Anew, 0, n * m * sizeof(double)); \n",
" \n",
" for(int i = 0; i < m; i++){ \n",
" A[i] = 1.0; \n",
" Anew[i] = 1.0; \n",
" } \n",
"} \n",
"```\n",
"\n",
"After the top edge is heated, the code will simulate the heat distributing across the length of the plate. We will keep the top edge at a constant heat as the simulation progresses.\n",
"\n",
"This is the plate after several iterations of our simulation: \n",
" \n",
" \n",
"\n",
"That's the theory: simple heat distribution. However, we are more interested in how the code works. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Code Breakdown\n",
"\n",
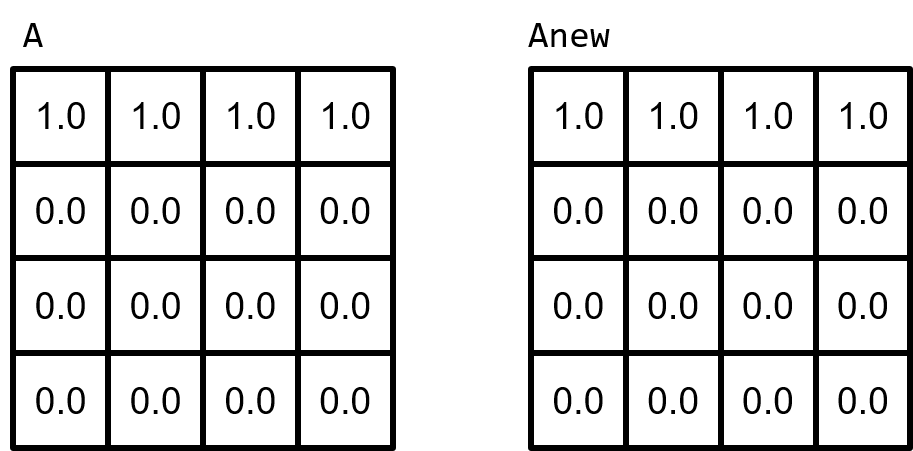
"The 2-dimensional plate is represented by a 2-dimensional array containing double-precision floating point values. These doubles represent temperature; 0.0 is room temperature, and 1.0 is our max temperature. The 2-dimensional plate has two states, one represents the current temperature, and one represents the expected temperature values at the next step in our simulation. These two states are represented by arrays **`A`** and **`Anew`** respectively. The following is a visual representation of these arrays, with the top edge \"heated\".\n",
"\n",
" \n",
" \n",
"Simulating this state in two arrays is very important for our **`calcNext`** function. Our calcNext is essentially our \"simulate\" function. calcNext will look at the inner elements of A (meaning everything except for the edges of the plate) and update each elements temperature based on the temperature of its neighbors. If we attempted to calculate in-place (using only **`A`**), then each element would calculate its new temperature based on the updated temperature of previous elements. This data dependency not only prevents parallelizing the code, but would also result in incorrect results when run in serial. By calculating into the temporary array **`Anew`** we ensure that an entire step of our simulation has completed before updating the **`A`** array.\n",
"\n",
" \n",
"\n",
"Below is the **`calcNext`** function:\n",
"```cpp\n",
"01 double calcNext(double *restrict A, double *restrict Anew, int m, int n)\n",
"02 {\n",
"03 double error = 0.0; \n",
"04 for( int j = 1; j < n-1; j++) \n",
"05 { \n",
"06 for( int i = 1; i < m-1; i++ ) \n",
"07 { \n",
"08 Anew[OFFSET(j, i, m)] = 0.25 * ( A[OFFSET(j, i+1, m)] + A[OFFSET(j, i-1, m)] \n",
"09 + A[OFFSET(j-1, i, m)] + A[OFFSET(j+1, i, m)]); \n",
"10 error = fmax( error, fabs(Anew[OFFSET(j, i, m)] - A[OFFSET(j, i , m)])); \n",
"11 } \n",
"12 } \n",
"13 return error; \n",
"14 } \n",
"```\n",
"\n",
"We see on lines 08 and 09 where we are calculating the value of **`Anew`** at **`i,j`** by averaging the current values of its neighbors. Line 10 is where we calculate the current rate of change for the simulation by looking at how much the **`i,j`** element changed during this step and finding the maximum value for this **`error`**. This allows us to short-circuit our simulation if it reaches a steady state before we've completed our maximum number of iterations.\n",
"\n",
"Lastly, our **`swap`** function will copy the contents of **`Anew`** to **`A`**.\n",
"\n",
"```cpp\n",
"01 void swap(double *restrict A, double *restrict Anew, int m, int n)\n",
"02 {\t\n",
"03 for( int j = 1; j < n-1; j++)\n",
"04 {\n",
"05 for( int i = 1; i < m-1; i++ )\n",
"06 {\n",
"07 A[OFFSET(j, i, m)] = Anew[OFFSET(j, i, m)]; \n",
"08 }\n",
"09 }\n",
"10 }\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Run the Code\n",
"\n",
"Now that we've seen what the code does, let's build and run it. We need to record the results of our program before making any changes so that we can compare them to the results from the parallel code later on. It is also important to record the time that the program takes to run, as this will be our primary indicator to whether or not our parallelization is improving performance."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Compiling the Code with NVIDIA HPC\n",
"\n",
"For this lab we are using the NVIDIA HPC compiler to compiler our code. You will not need to memorize the compiler commands to complete this lab, however, they will be helpful to know if you want to parallelize your own personal code with OpenACC.\n",
"\n",
"**nvc** : this is the command to compile C code \n",
"**nvc++** : this is the command to compile C++ code \n",
"**nvfortran** : this is the command to compile Fortran code \n",
"**-fast** : this compiler flag instructs the compiler to use what it believes are the best possible optimizations for our system"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab1 && make clean && make laplace_serial && echo \"Compilation Successful!\" && ./laplace"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Expected Output\n",
"```\n",
"jacobi.c:\n",
"laplace2d.c:\n",
"Compilation Successful!\n",
"Jacobi relaxation Calculation: 4096 x 4096 mesh\n",
" 0, 0.250000\n",
" 100, 0.002397\n",
" 200, 0.001204\n",
" 300, 0.000804\n",
" 400, 0.000603\n",
" 500, 0.000483\n",
" 600, 0.000403\n",
" 700, 0.000345\n",
" 800, 0.000302\n",
" 900, 0.000269\n",
" total: 60.725809 s\n",
"```\n",
"\n",
"### Understanding Code Results\n",
"\n",
"We see from the output that onces every hundred steps the program outputs the value of `error`, which is the maximum rate of change among the cells in our array. If these outputs change during any point while we parallelize our code, we know we've made a mistake. For simplicity, focus on the last output, which occurred at iteration 900 (the error is 0.000269). It is also helpful to record the time the program took to run (it should have been around a minute). Our goal while parallelizing the code is ultimately to make it faster, so we need to know our \"base runtime\" in order to know if the code is running faster. Keep in mind that if you run the code multiple times you may get slightly different total runtimes, but you should get the same values for the error rates."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Parallelizing Loops with OpenACC\n",
"\n",
"At this point we know that most of the work done in our code happens in the `calcNext` and `swap` routines, so we'll focus our efforts there. We want the compiler to parallelize the loops in those two routines because that will give up the maximum speed-up over the baseline we just measured. To do this, we're going to use the OpenACC `parallel loop` directive."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## OpenACC Directives\n",
"\n",
"Using OpenACC directives will allow us to parallelize our code without needing to explicitly alter our code. What this means is that, by using OpenACC directives, we can have a single code that will function as both a sequential code and a parallel code.\n",
"\n",
"### OpenACC Syntax\n",
"\n",
"**`#pragma acc `**\n",
"\n",
"**#pragma** in C/C++ is what's known as a \"compiler hint.\" These are very similar to programmer comments, however, the compiler will actually read our pragmas. Pragmas are a way for the programmer to \"guide\" the compiler above and beyond what the programming languages allow. If the compiler does not understand the pragma, it can ignore it, rather than throw a syntax error.\n",
"\n",
"**acc** is an addition to our pragma. It specifies that this is an **OpenACC pragma**. Any non-OpenACC compiler will ignore this pragma. Even our NVIDIA HPC compiler can be told to ignore them. (which lets us run our parallel code sequentially!)\n",
"\n",
"**directives** are commands in OpenACC that will tell the compiler to do some action. For now, we will only use directives that allow the compiler to parallelize our code.\n",
"\n",
"**clauses** are additions/alterations to our directives. These include (but are not limited to) optimizations. The way that I prefer to think about it: directives describe a general action for our compiler to do (such as, paralellize our code), and clauses allow the programmer to be more specific (such as, how we specifically want the code to be parallelized).\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"### Parallel and Loop Directives\n",
"\n",
"There are three directives we will cover in this lab: `parallel`, `loop`, and `parallel loop`. Once we understand all three of them, you will be tasked with parallelizing our laplace code with your preferred directive (or use all of them, if you'd like!)\n",
"\n",
"The parallel directive may be the most straight-forward of the directives. It will mark a region of the code for parallelization (this usually only includes parallelizing a single **for** loop.) Let's take a look:\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop\n",
"for (int i = 0; i < N; i++ )\n",
"{\n",
" < loop code >\n",
"}\n",
"```\n",
"\n",
"We may also define a \"parallel region\". The parallel region may have multiple loops (though this is often not recommended!) The parallel region is everything contained within the outer-most curly braces.\n",
"\n",
"```cpp\n",
"#pragma acc parallel\n",
"{\n",
" #pragma acc loop\n",
" for (int i = 0; i < N; i++ )\n",
" {\n",
" < loop code >\n",
" }\n",
"}\n",
"```\n",
"\n",
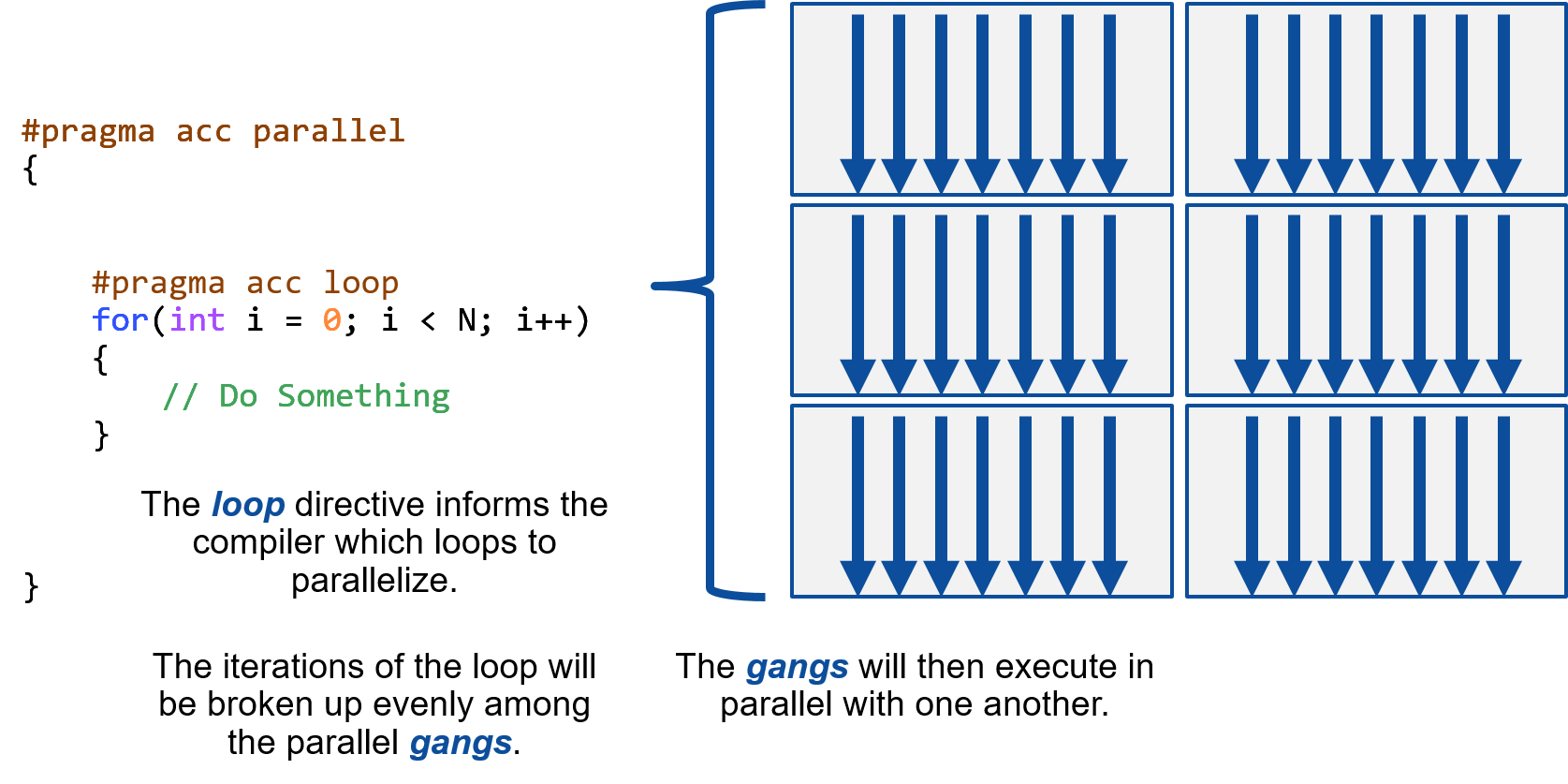
"`#pragma acc parallel loop` will mark the next loop for parallelization. It is extremely important to include the `loop`, otherwise you will not be parallelizing the loop properly. The parallel directive tells the compiler to \"redundantly parallelize\" the code. The `loop` directive specifically tells the compiler that we want the loop parallelized. Let's look at an example of why the loop directive is so important. The `parallel` directive tells the compiler to create somewhere to run parallel code. OpenACC calls that somewhere a `gang`, which might be a thread on the CPU or maying a CUDA threadblock or OpenCL workgroup. It will choose how many gangs to create based on where you're running, only a few on a CPU (like 1 per CPU core) or lots on a GPU (1000's possibly). Gangs allow OpenACC code to scale from small CPUs to large GPUs because each one works completely independently of each other gang. That's why there's a space between gangs in the images below.\n",
"\n",
"\n",
"\n",
"---\n",
"\n",
"\n",
"\n",
"There's a good chance that I don't want my loop to be run redundantly in every gang though, that seems wasteful and potentially dangerous. Instead I want to instruct the compiler to break up the iterations of my loop and to run them in parallel on the gangs. To do that, I simply add a `loop` directive to the interesting loops. This instructs the compiler that I want my loop to be parallelized and promises to the compiler that it's safe to do so. Now that I have both `parallel` and `loop`, things loop a lot better (and run a lot faster). Now the compiler is spreading my loop iterations to all of my gangs, but also running multiple iterations of the loop at the same time within each gang as a *vector*. Think of a vector like this, I have 10 numbers that I want to add to 10 other numbers (in pairs). Rather than looking up each pair of numbers, adding them together, storing the result, and then moving on to the next pair in-order, modern computer hardware allows me to add all 10 pairs together all at once, which is a lot more efficient. \n",
"\n",
"\n",
"\n",
"The `acc parallel loop` directive is both a promise and a request to the compiler. I as the programmer am promising that the loop can safely be parallelized and am requesting that the compiler do so in a way that makes sense for the machine I am targeting. The compiler may make completely different decisions if I'm compiling for a multicore CPU than it would for a GPU and that's the idea. OpenACC enables programmers to parallelize their codes without having to worry about the details of how best to do so for every possible machine. \n",
"\n",
"### Reduction Clause\n",
"\n",
"There's one very important clause that you'll need to know for our example code: the `reduction` clause. Take note of how the loops in `calcNext` each calculate an error value and then compare against the maximum value to find an absolute maximum. When executing this operation in parallel, it's necessary to do a *reduction* in order to ensure you always get the correct answer. A reduction takes all of the values of `error` calculated in the loops and *reduces* them down to a single answer, in this case the maximum. There are a variety of reductions that can be done, but for our example code we only care about the max operation. We will inform the compiler about our reduction by adding a `reduction(max:error)` clause to the `acc parallel loop` in the `calcNext` function."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Parallelize the Example Code\n",
"\n",
"At this point you have all of the tools you need to begin accelerating your application. The loops you will be parallelizing are in `laplace2d.c`. Click on the [laplace2d.c](../source_code/lab1/laplace2d.c) link and modify `laplace2d.c`. Remember to **SAVE** your code after changes, before running below cells.\n",
"\n",
"It is advisable to start with the `calcNext` routine and test your changes by compiling and running the code before moving on to the `swap` routine. OpenACC can be incrementally added to your application so that you can ensure each change is correct before getting too far along, which greatly simplifies debugging.\n",
"\n",
"Once you have made your changes, you can compile and run the application by running the cell below. Please note that our compiler options have changed a little bit, we've added the following two important flags:\n",
"\n",
"* `-ta=multicore` - This instructs the compiler to build your OpenACC loops and to target them to run across the cores of a multicore CPU. \n",
"* `-Minfo=accel` - This instructs the compiler to give us some additional information about how it parallelized the code. We'll review how to interpret this feedback in just a moment.\n",
"\n",
"Go ahead and build and run the code, noting both the error value at the 900th iteration and the total runtime. If the error value changed, you may have made a mistake. Don't forget the `reduction(max:error)` clause on the loop in the `calcNext` function!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab1 && make clean && make laplace_multicore && echo \"Compilation Successful!\" && ./laplace"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here's the ouput you should see after running the above cell. Your total runtime may be slightly different, but it should be close. If you find yourself stuck on this part, you can take a look at [our solution](../source_code/lab1/solutions/laplace2d.parallel.c). If you see a warning like `48, Accelerator restriction: size of the GPU copy of Anew,A is unknown`, you can safely ignore it.\n",
"\n",
"```\n",
"jacobi.c:\n",
"laplace2d.c:\n",
"calcNext:\n",
" 47, Generating Multicore code\n",
" 48, #pragma acc loop gang\n",
" 48, Accelerator restriction: size of the GPU copy of Anew,A is unknown\n",
" Generating reduction(max:error)\n",
" 50, Loop is parallelizable\n",
"swap:\n",
" 62, Generating Multicore code\n",
" 63, #pragma acc loop gang\n",
" 63, Accelerator restriction: size of the GPU copy of Anew,A is unknown\n",
" 65, Loop is parallelizable\n",
"Compilation Successful!\n",
"Jacobi relaxation Calculation: 4096 x 4096 mesh\n",
" 0, 0.250000\n",
" 100, 0.002397\n",
" 200, 0.001204\n",
" 300, 0.000804\n",
" 400, 0.000603\n",
" 500, 0.000483\n",
" 600, 0.000403\n",
" 700, 0.000345\n",
" 800, 0.000302\n",
" 900, 0.000269\n",
" total: 30.998768 s\n",
"```\n",
"\n",
"Great! Now our code is running roughly twice as fast by using all of the cores on our CPU, but I really want to run the code on a GPU. Once you have accelerated both loop nests in the example application and are sure you're getting correct results, you only need to change one compiler option to build the code for the GPUs on our node.\n",
"\n",
"Here's the new compiler option we'll be using:\n",
"* `-ta=tesla:cc70,managed` - Build the code for the NVIDIA Tesla GPU on our system, using managed memory \n",
"\n",
"Notice above that I'm using something called *managed memory* for this task. Since our CPU and GPU each have their own physical memory I need to move the data between these memories. To simplify things this week, I'm telling the compiler to manage all of that data movement for me. Next week you'll learn how and why to manage the data movement yourself."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab1 && make clean && make laplace_gpu && echo \"Compilation Successful!\" && ./laplace"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Wow! That ran a lot faster! This demonstrates the power of using OpenACC to accelerate an application. I made very minimal code changes and could run my code on multicore CPUs and GPUs by only changing my compiler option. Very cool!\n",
"\n",
"Just for your reference, here's the timings I saw at each step of the process. Please keep in mind that your times may be just a little bit different\n",
"\n",
"| Version | Time (s) |\n",
"|-----------|----------|\n",
"| Original | 60s |\n",
"| Multicore | 31s |\n",
"| GPU | 4s |\n",
"\n",
"So how did the compiler perform this miracle of speeding up my code on both the CPU and GPU? Let's look at the compiler output from those two versions:\n",
"\n",
"#### CPU\n",
"```\n",
"calcNext:\n",
" 47, Generating Multicore code\n",
" 48, #pragma acc loop gang\n",
" 48, Accelerator restriction: size of the GPU copy of Anew,A is unknown\n",
" Generating reduction(max:error)\n",
" 50, Loop is parallelizable\n",
"```\n",
"\n",
"#### GPU\n",
"\n",
"```\n",
"calcNext:\n",
" 47, Accelerator kernel generated\n",
" Generating Tesla code\n",
" 48, #pragma acc loop gang /* blockIdx.x */\n",
" Generating reduction(max:error)\n",
" 50, #pragma acc loop vector(128) /* threadIdx.x */\n",
" 47, Generating implicit copyin(A[:])\n",
" Generating implicit copy(error)\n",
" Generating implicit copyout(Anew[:])\n",
" 50, Loop is parallelizable\n",
"\n",
"```\n",
"\n",
"Notice the differences on lines 48 and 50 . The compiler recognized that the loops could be parallelized, but chose to break up the work in different ways. In a future lab you will learn more about how OpenACC breaks up the work, but for now it's enough to know that the compiler understood the differences between these two processors and changed its plan to make sense for each."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Conclusion\n",
"\n",
"That's it, you now have the necessary tools to start using OpenACC in your application! In future labs you will learn about how to manage the CPU and GPU memories and how to optimize your loops to run faster, so be sure to attend each week of this online course and to do each lab."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Bonus Task\n",
"\n",
"It just so happens that the `acc parallel loop` directive isn't the only way we could have parallelized our code with OpenACC, it's just the easiest to understand. As a bonus task, [click here](openacc_c_lab1-bonus.ipynb) to learn about the `acc kernels` directive and how it differs from the approach we've already taken."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Post-Lab Summary\n",
"\n",
"If you would like to download this lab for later viewing, it is recommend you go to your browsers File menu (not the Jupyter notebook file menu) and save the complete web page. This will ensure the images are copied down as well.\n",
"\n",
"You can also execute the following cell block to create a zip-file of the files you've been working on, and download it with the link below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%bash\n",
"cd ..\n",
"rm -f openacc_files.zip\n",
"zip -r openacc_files.zip *"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**After** executing the above zip command, you should be able to download and save the zip file by holding down Shift and Right-Clicking [Here](../openacc_files.zip)\n",
"\n",
"---\n",
"## Licensing\n",
"This material is released by OpenACC-Standard.org, in collaboration with NVIDIA Corporation, under the Creative Commons Attribution 4.0 International (CC BY 4.0)."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.9"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
\n",
"\n",
"**Analyze** your code to determine most likely places needing parallelization or optimization.\n",
"\n",
"**Parallelize** your code by starting with the most time consuming parts and check for correctness.\n",
"\n",
"**Optimize** your code to improve observed speed-up from parallelization.\n",
"\n",
"One should generally start the process at the top with the **analyze** step. For complex applications, it's useful to have a profiling tool available to learn where your application is spending its execution time and to focus your efforts there. The NVIDIA HPC Software Development Kit (SDK) comes with NVIDIA Nsight Systems/Compute for interactive HPC applications performance profiler. Since our example code is quite a bit simpler than a full application, we'll skip profiling the code and simply analyze the code by reading it. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Analyze the Code\n",
"\n",
"In the section below you will learn about the algorithm implemented in the example code and see examples pulled out of the source code. If you want a sneak peek at the source code, you can take a look at the files linked below or open the downloaded file.\n",
"\n",
"[jacobi.c](../source_code/lab1/jacobi.c) \n",
"[laplace2d.c](../source_code/lab1/laplace2d.c) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Code Description\n",
"\n",
"The code simulates heat distribution across a 2-dimensional metal plate. In the beginning, the plate will be unheated, meaning that the entire plate will be room temperature. A constant heat will be applied to the edge of the plate and the code will simulate that heat distributing across the plate over time. \n",
"\n",
"This is a visual representation of the plate before the simulation starts: \n",
" \n",
" \n",
" \n",
"We can see that the plate is uniformly room temperature, except for the top edge. Within the [laplace2d.c](../source_code/lab1/laplace2d.c) file, we see a function called **`initialize`**. This function is what \"heats\" the top edge of the plate. \n",
" \n",
"```cpp\n",
"void initialize(double *restrict A, double *restrict Anew, int m, int n) \n",
"{ \n",
" memset(A, 0, n * m * sizeof(double)); \n",
" memset(Anew, 0, n * m * sizeof(double)); \n",
" \n",
" for(int i = 0; i < m; i++){ \n",
" A[i] = 1.0; \n",
" Anew[i] = 1.0; \n",
" } \n",
"} \n",
"```\n",
"\n",
"After the top edge is heated, the code will simulate the heat distributing across the length of the plate. We will keep the top edge at a constant heat as the simulation progresses.\n",
"\n",
"This is the plate after several iterations of our simulation: \n",
" \n",
" \n",
"\n",
"That's the theory: simple heat distribution. However, we are more interested in how the code works. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Code Breakdown\n",
"\n",
"The 2-dimensional plate is represented by a 2-dimensional array containing double-precision floating point values. These doubles represent temperature; 0.0 is room temperature, and 1.0 is our max temperature. The 2-dimensional plate has two states, one represents the current temperature, and one represents the expected temperature values at the next step in our simulation. These two states are represented by arrays **`A`** and **`Anew`** respectively. The following is a visual representation of these arrays, with the top edge \"heated\".\n",
"\n",
" \n",
" \n",
"Simulating this state in two arrays is very important for our **`calcNext`** function. Our calcNext is essentially our \"simulate\" function. calcNext will look at the inner elements of A (meaning everything except for the edges of the plate) and update each elements temperature based on the temperature of its neighbors. If we attempted to calculate in-place (using only **`A`**), then each element would calculate its new temperature based on the updated temperature of previous elements. This data dependency not only prevents parallelizing the code, but would also result in incorrect results when run in serial. By calculating into the temporary array **`Anew`** we ensure that an entire step of our simulation has completed before updating the **`A`** array.\n",
"\n",
" \n",
"\n",
"Below is the **`calcNext`** function:\n",
"```cpp\n",
"01 double calcNext(double *restrict A, double *restrict Anew, int m, int n)\n",
"02 {\n",
"03 double error = 0.0; \n",
"04 for( int j = 1; j < n-1; j++) \n",
"05 { \n",
"06 for( int i = 1; i < m-1; i++ ) \n",
"07 { \n",
"08 Anew[OFFSET(j, i, m)] = 0.25 * ( A[OFFSET(j, i+1, m)] + A[OFFSET(j, i-1, m)] \n",
"09 + A[OFFSET(j-1, i, m)] + A[OFFSET(j+1, i, m)]); \n",
"10 error = fmax( error, fabs(Anew[OFFSET(j, i, m)] - A[OFFSET(j, i , m)])); \n",
"11 } \n",
"12 } \n",
"13 return error; \n",
"14 } \n",
"```\n",
"\n",
"We see on lines 08 and 09 where we are calculating the value of **`Anew`** at **`i,j`** by averaging the current values of its neighbors. Line 10 is where we calculate the current rate of change for the simulation by looking at how much the **`i,j`** element changed during this step and finding the maximum value for this **`error`**. This allows us to short-circuit our simulation if it reaches a steady state before we've completed our maximum number of iterations.\n",
"\n",
"Lastly, our **`swap`** function will copy the contents of **`Anew`** to **`A`**.\n",
"\n",
"```cpp\n",
"01 void swap(double *restrict A, double *restrict Anew, int m, int n)\n",
"02 {\t\n",
"03 for( int j = 1; j < n-1; j++)\n",
"04 {\n",
"05 for( int i = 1; i < m-1; i++ )\n",
"06 {\n",
"07 A[OFFSET(j, i, m)] = Anew[OFFSET(j, i, m)]; \n",
"08 }\n",
"09 }\n",
"10 }\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Run the Code\n",
"\n",
"Now that we've seen what the code does, let's build and run it. We need to record the results of our program before making any changes so that we can compare them to the results from the parallel code later on. It is also important to record the time that the program takes to run, as this will be our primary indicator to whether or not our parallelization is improving performance."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Compiling the Code with NVIDIA HPC\n",
"\n",
"For this lab we are using the NVIDIA HPC compiler to compiler our code. You will not need to memorize the compiler commands to complete this lab, however, they will be helpful to know if you want to parallelize your own personal code with OpenACC.\n",
"\n",
"**nvc** : this is the command to compile C code \n",
"**nvc++** : this is the command to compile C++ code \n",
"**nvfortran** : this is the command to compile Fortran code \n",
"**-fast** : this compiler flag instructs the compiler to use what it believes are the best possible optimizations for our system"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab1 && make clean && make laplace_serial && echo \"Compilation Successful!\" && ./laplace"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Expected Output\n",
"```\n",
"jacobi.c:\n",
"laplace2d.c:\n",
"Compilation Successful!\n",
"Jacobi relaxation Calculation: 4096 x 4096 mesh\n",
" 0, 0.250000\n",
" 100, 0.002397\n",
" 200, 0.001204\n",
" 300, 0.000804\n",
" 400, 0.000603\n",
" 500, 0.000483\n",
" 600, 0.000403\n",
" 700, 0.000345\n",
" 800, 0.000302\n",
" 900, 0.000269\n",
" total: 60.725809 s\n",
"```\n",
"\n",
"### Understanding Code Results\n",
"\n",
"We see from the output that onces every hundred steps the program outputs the value of `error`, which is the maximum rate of change among the cells in our array. If these outputs change during any point while we parallelize our code, we know we've made a mistake. For simplicity, focus on the last output, which occurred at iteration 900 (the error is 0.000269). It is also helpful to record the time the program took to run (it should have been around a minute). Our goal while parallelizing the code is ultimately to make it faster, so we need to know our \"base runtime\" in order to know if the code is running faster. Keep in mind that if you run the code multiple times you may get slightly different total runtimes, but you should get the same values for the error rates."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Parallelizing Loops with OpenACC\n",
"\n",
"At this point we know that most of the work done in our code happens in the `calcNext` and `swap` routines, so we'll focus our efforts there. We want the compiler to parallelize the loops in those two routines because that will give up the maximum speed-up over the baseline we just measured. To do this, we're going to use the OpenACC `parallel loop` directive."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## OpenACC Directives\n",
"\n",
"Using OpenACC directives will allow us to parallelize our code without needing to explicitly alter our code. What this means is that, by using OpenACC directives, we can have a single code that will function as both a sequential code and a parallel code.\n",
"\n",
"### OpenACC Syntax\n",
"\n",
"**`#pragma acc `**\n",
"\n",
"**#pragma** in C/C++ is what's known as a \"compiler hint.\" These are very similar to programmer comments, however, the compiler will actually read our pragmas. Pragmas are a way for the programmer to \"guide\" the compiler above and beyond what the programming languages allow. If the compiler does not understand the pragma, it can ignore it, rather than throw a syntax error.\n",
"\n",
"**acc** is an addition to our pragma. It specifies that this is an **OpenACC pragma**. Any non-OpenACC compiler will ignore this pragma. Even our NVIDIA HPC compiler can be told to ignore them. (which lets us run our parallel code sequentially!)\n",
"\n",
"**directives** are commands in OpenACC that will tell the compiler to do some action. For now, we will only use directives that allow the compiler to parallelize our code.\n",
"\n",
"**clauses** are additions/alterations to our directives. These include (but are not limited to) optimizations. The way that I prefer to think about it: directives describe a general action for our compiler to do (such as, paralellize our code), and clauses allow the programmer to be more specific (such as, how we specifically want the code to be parallelized).\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"### Parallel and Loop Directives\n",
"\n",
"There are three directives we will cover in this lab: `parallel`, `loop`, and `parallel loop`. Once we understand all three of them, you will be tasked with parallelizing our laplace code with your preferred directive (or use all of them, if you'd like!)\n",
"\n",
"The parallel directive may be the most straight-forward of the directives. It will mark a region of the code for parallelization (this usually only includes parallelizing a single **for** loop.) Let's take a look:\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop\n",
"for (int i = 0; i < N; i++ )\n",
"{\n",
" < loop code >\n",
"}\n",
"```\n",
"\n",
"We may also define a \"parallel region\". The parallel region may have multiple loops (though this is often not recommended!) The parallel region is everything contained within the outer-most curly braces.\n",
"\n",
"```cpp\n",
"#pragma acc parallel\n",
"{\n",
" #pragma acc loop\n",
" for (int i = 0; i < N; i++ )\n",
" {\n",
" < loop code >\n",
" }\n",
"}\n",
"```\n",
"\n",
"`#pragma acc parallel loop` will mark the next loop for parallelization. It is extremely important to include the `loop`, otherwise you will not be parallelizing the loop properly. The parallel directive tells the compiler to \"redundantly parallelize\" the code. The `loop` directive specifically tells the compiler that we want the loop parallelized. Let's look at an example of why the loop directive is so important. The `parallel` directive tells the compiler to create somewhere to run parallel code. OpenACC calls that somewhere a `gang`, which might be a thread on the CPU or maying a CUDA threadblock or OpenCL workgroup. It will choose how many gangs to create based on where you're running, only a few on a CPU (like 1 per CPU core) or lots on a GPU (1000's possibly). Gangs allow OpenACC code to scale from small CPUs to large GPUs because each one works completely independently of each other gang. That's why there's a space between gangs in the images below.\n",
"\n",
"\n",
"\n",
"---\n",
"\n",
"\n",
"\n",
"There's a good chance that I don't want my loop to be run redundantly in every gang though, that seems wasteful and potentially dangerous. Instead I want to instruct the compiler to break up the iterations of my loop and to run them in parallel on the gangs. To do that, I simply add a `loop` directive to the interesting loops. This instructs the compiler that I want my loop to be parallelized and promises to the compiler that it's safe to do so. Now that I have both `parallel` and `loop`, things loop a lot better (and run a lot faster). Now the compiler is spreading my loop iterations to all of my gangs, but also running multiple iterations of the loop at the same time within each gang as a *vector*. Think of a vector like this, I have 10 numbers that I want to add to 10 other numbers (in pairs). Rather than looking up each pair of numbers, adding them together, storing the result, and then moving on to the next pair in-order, modern computer hardware allows me to add all 10 pairs together all at once, which is a lot more efficient. \n",
"\n",
"\n",
"\n",
"The `acc parallel loop` directive is both a promise and a request to the compiler. I as the programmer am promising that the loop can safely be parallelized and am requesting that the compiler do so in a way that makes sense for the machine I am targeting. The compiler may make completely different decisions if I'm compiling for a multicore CPU than it would for a GPU and that's the idea. OpenACC enables programmers to parallelize their codes without having to worry about the details of how best to do so for every possible machine. \n",
"\n",
"### Reduction Clause\n",
"\n",
"There's one very important clause that you'll need to know for our example code: the `reduction` clause. Take note of how the loops in `calcNext` each calculate an error value and then compare against the maximum value to find an absolute maximum. When executing this operation in parallel, it's necessary to do a *reduction* in order to ensure you always get the correct answer. A reduction takes all of the values of `error` calculated in the loops and *reduces* them down to a single answer, in this case the maximum. There are a variety of reductions that can be done, but for our example code we only care about the max operation. We will inform the compiler about our reduction by adding a `reduction(max:error)` clause to the `acc parallel loop` in the `calcNext` function."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Parallelize the Example Code\n",
"\n",
"At this point you have all of the tools you need to begin accelerating your application. The loops you will be parallelizing are in `laplace2d.c`. Click on the [laplace2d.c](../source_code/lab1/laplace2d.c) link and modify `laplace2d.c`. Remember to **SAVE** your code after changes, before running below cells.\n",
"\n",
"It is advisable to start with the `calcNext` routine and test your changes by compiling and running the code before moving on to the `swap` routine. OpenACC can be incrementally added to your application so that you can ensure each change is correct before getting too far along, which greatly simplifies debugging.\n",
"\n",
"Once you have made your changes, you can compile and run the application by running the cell below. Please note that our compiler options have changed a little bit, we've added the following two important flags:\n",
"\n",
"* `-ta=multicore` - This instructs the compiler to build your OpenACC loops and to target them to run across the cores of a multicore CPU. \n",
"* `-Minfo=accel` - This instructs the compiler to give us some additional information about how it parallelized the code. We'll review how to interpret this feedback in just a moment.\n",
"\n",
"Go ahead and build and run the code, noting both the error value at the 900th iteration and the total runtime. If the error value changed, you may have made a mistake. Don't forget the `reduction(max:error)` clause on the loop in the `calcNext` function!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab1 && make clean && make laplace_multicore && echo \"Compilation Successful!\" && ./laplace"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here's the ouput you should see after running the above cell. Your total runtime may be slightly different, but it should be close. If you find yourself stuck on this part, you can take a look at [our solution](../source_code/lab1/solutions/laplace2d.parallel.c). If you see a warning like `48, Accelerator restriction: size of the GPU copy of Anew,A is unknown`, you can safely ignore it.\n",
"\n",
"```\n",
"jacobi.c:\n",
"laplace2d.c:\n",
"calcNext:\n",
" 47, Generating Multicore code\n",
" 48, #pragma acc loop gang\n",
" 48, Accelerator restriction: size of the GPU copy of Anew,A is unknown\n",
" Generating reduction(max:error)\n",
" 50, Loop is parallelizable\n",
"swap:\n",
" 62, Generating Multicore code\n",
" 63, #pragma acc loop gang\n",
" 63, Accelerator restriction: size of the GPU copy of Anew,A is unknown\n",
" 65, Loop is parallelizable\n",
"Compilation Successful!\n",
"Jacobi relaxation Calculation: 4096 x 4096 mesh\n",
" 0, 0.250000\n",
" 100, 0.002397\n",
" 200, 0.001204\n",
" 300, 0.000804\n",
" 400, 0.000603\n",
" 500, 0.000483\n",
" 600, 0.000403\n",
" 700, 0.000345\n",
" 800, 0.000302\n",
" 900, 0.000269\n",
" total: 30.998768 s\n",
"```\n",
"\n",
"Great! Now our code is running roughly twice as fast by using all of the cores on our CPU, but I really want to run the code on a GPU. Once you have accelerated both loop nests in the example application and are sure you're getting correct results, you only need to change one compiler option to build the code for the GPUs on our node.\n",
"\n",
"Here's the new compiler option we'll be using:\n",
"* `-ta=tesla:cc70,managed` - Build the code for the NVIDIA Tesla GPU on our system, using managed memory \n",
"\n",
"Notice above that I'm using something called *managed memory* for this task. Since our CPU and GPU each have their own physical memory I need to move the data between these memories. To simplify things this week, I'm telling the compiler to manage all of that data movement for me. Next week you'll learn how and why to manage the data movement yourself."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab1 && make clean && make laplace_gpu && echo \"Compilation Successful!\" && ./laplace"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Wow! That ran a lot faster! This demonstrates the power of using OpenACC to accelerate an application. I made very minimal code changes and could run my code on multicore CPUs and GPUs by only changing my compiler option. Very cool!\n",
"\n",
"Just for your reference, here's the timings I saw at each step of the process. Please keep in mind that your times may be just a little bit different\n",
"\n",
"| Version | Time (s) |\n",
"|-----------|----------|\n",
"| Original | 60s |\n",
"| Multicore | 31s |\n",
"| GPU | 4s |\n",
"\n",
"So how did the compiler perform this miracle of speeding up my code on both the CPU and GPU? Let's look at the compiler output from those two versions:\n",
"\n",
"#### CPU\n",
"```\n",
"calcNext:\n",
" 47, Generating Multicore code\n",
" 48, #pragma acc loop gang\n",
" 48, Accelerator restriction: size of the GPU copy of Anew,A is unknown\n",
" Generating reduction(max:error)\n",
" 50, Loop is parallelizable\n",
"```\n",
"\n",
"#### GPU\n",
"\n",
"```\n",
"calcNext:\n",
" 47, Accelerator kernel generated\n",
" Generating Tesla code\n",
" 48, #pragma acc loop gang /* blockIdx.x */\n",
" Generating reduction(max:error)\n",
" 50, #pragma acc loop vector(128) /* threadIdx.x */\n",
" 47, Generating implicit copyin(A[:])\n",
" Generating implicit copy(error)\n",
" Generating implicit copyout(Anew[:])\n",
" 50, Loop is parallelizable\n",
"\n",
"```\n",
"\n",
"Notice the differences on lines 48 and 50 . The compiler recognized that the loops could be parallelized, but chose to break up the work in different ways. In a future lab you will learn more about how OpenACC breaks up the work, but for now it's enough to know that the compiler understood the differences between these two processors and changed its plan to make sense for each."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Conclusion\n",
"\n",
"That's it, you now have the necessary tools to start using OpenACC in your application! In future labs you will learn about how to manage the CPU and GPU memories and how to optimize your loops to run faster, so be sure to attend each week of this online course and to do each lab."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Bonus Task\n",
"\n",
"It just so happens that the `acc parallel loop` directive isn't the only way we could have parallelized our code with OpenACC, it's just the easiest to understand. As a bonus task, [click here](openacc_c_lab1-bonus.ipynb) to learn about the `acc kernels` directive and how it differs from the approach we've already taken."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Post-Lab Summary\n",
"\n",
"If you would like to download this lab for later viewing, it is recommend you go to your browsers File menu (not the Jupyter notebook file menu) and save the complete web page. This will ensure the images are copied down as well.\n",
"\n",
"You can also execute the following cell block to create a zip-file of the files you've been working on, and download it with the link below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%bash\n",
"cd ..\n",
"rm -f openacc_files.zip\n",
"zip -r openacc_files.zip *"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**After** executing the above zip command, you should be able to download and save the zip file by holding down Shift and Right-Clicking [Here](../openacc_files.zip)\n",
"\n",
"---\n",
"## Licensing\n",
"This material is released by OpenACC-Standard.org, in collaboration with NVIDIA Corporation, under the Creative Commons Attribution 4.0 International (CC BY 4.0)."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.9"
}
},
"nbformat": 4,
"nbformat_minor": 4
}