{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Data Management with OpenACC"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This version of the lab is intended for C/C++ programmers. The Fortran version of this lab is available [here](../../Fortran/jupyter_notebook/openacc_fortran_lab2.ipynb)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You will receive a warning five minutes before the lab instance shuts down. Remember to save your work! If you are about to run out of time, please see the [Post-Lab](#Post-Lab-Summary) section for saving this lab to view offline later."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"Let's execute the cell below to display information about the GPUs running on the server. To do this, execute the cell block below by giving it focus (clicking on it with your mouse), and hitting Ctrl-Enter, or pressing the play button in the toolbar above. If all goes well, you should see some output returned below the grey cell."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"!nvaccelinfo"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Introduction\n",
"\n",
"Our goal for this lab is to use the OpenACC Data Directives to properly manage our data.\n",
" \n",
" \n",
"\n",
"This is the OpenACC 3-Step development cycle.\n",
"\n",
"**Analyze** your code, and predict where potential parallelism can be uncovered. Use profiler to help understand what is happening in the code, and where parallelism may exist.\n",
"\n",
"**Parallelize** your code, starting with the most time consuming parts. Focus on maintaining correct results from your program.\n",
"\n",
"**Optimize** your code, focusing on maximizing performance. Performance may not increase all-at-once during early parallelization.\n",
"\n",
"We are currently tackling the **parallelize** and **optimize** steps by adding the *data clauses* necessary to parallelize the code without CUDA Managed Memory and then *structured data directives* to optimize the data movement of our code."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Run the Code (With Managed Memory)\n",
"\n",
"In the [previous lab](openacc_c_lab1.ipynb), we added OpenACC loop directives and relied on a feature called CUDA Managed Memory to deal with the separate CPU & GPU memories for us. Just adding OpenACC to our two loop nests we achieved a considerable performance boost. However, managed memory is not compatible with all GPUs or all compilers and it sometimes performs worse than programmer-defined memory management. Let's start with our solution from the previous lab and use this as our performance baseline. Note the runtime from the follow cell."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2 && make clean && make laplace_managed && ./laplace_managed"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Optional: Analyze the Code\n",
"\n",
"If you would like a refresher on the code files that we are working on, you may view both of them using the two links below by openning the downloaded file.\n",
"\n",
"[jacobi.c](../source_code/lab2/jacobi.c) \n",
"[laplace2d.c](../source_code/lab2/laplace2d.c) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Building Without Managed Memory\n",
"\n",
"For this exercise we ultimately don't want to use CUDA Managed Memory, so let's remove the managed option from our compiler options. Try building and running the code now. What happens?"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2 && make clean && make laplace_no_managed && ./laplace"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Uh-oh, this time our code failed to build. Let's take a look at the compiler output to understand why:\n",
"\n",
"```\n",
"jacobi.c:\n",
"laplace2d.c:\n",
"NVC++-S-0155-Compiler failed to translate accelerator region (see -Minfo messages): Could not find allocated-variable index for symbol (laplace2d.c: 47)\n",
"calcNext:\n",
" 47, Accelerator kernel generated\n",
" Generating Tesla code\n",
" 48, #pragma acc loop gang /* blockIdx.x */\n",
" 50, #pragma acc loop vector(128) /* threadIdx.x */\n",
" 54, Generating implicit reduction(max:error)\n",
" 48, Accelerator restriction: size of the GPU copy of Anew,A is unknown\n",
" 50, Loop is parallelizable\n",
"NVC++-F-0704-Compilation aborted due to previous errors. (laplace2d.c)\n",
"NVC++/x86-64 Linux 18.7-0: compilation aborted\n",
"```\n",
"\n",
"This error message is not very intuitive, so let me explain it to you.:\n",
"\n",
"* `NVC++-S-0155-Compiler failed to translate accelerator region (see -Minfo messages): Could not find allocated-variable index for symbol (laplace2d.c: 47)` - The compiler doesn't like something about a variable from line 47 of our code.\n",
"* `48, Accelerator restriction: size of the GPU copy of Anew,A is unknown` - I don't see any further information about line 47, but at line 48 the compiler is struggling to understand the size and shape of the arrays Anew and A. It turns out, this is our problem.\n",
"\n",
"So, what these cryptic compiler errors are telling us is that the compiler needs to create copies of A and Anew on the GPU in order to run our code there, but it doesn't know how big they are, so it's giving up. We'll need to give the compiler more information about these arrays before it can move forward, so let's find out how to do that."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## OpenACC Data Clauses\n",
"\n",
"Data clauses allow the programmer to specify data transfers between the host and device (or in our case, the CPU and the GPU). Because they are clauses, they can be added to other directives, such as the `parallel loop` directive that we used in the previous lab. Let's look at an example where we do not use a data clause.\n",
"\n",
"```cpp\n",
"int *A = (int*) malloc(N * sizeof(int));\n",
"\n",
"#pragma acc parallel loop\n",
"for( int i = 0; i < N; i++ )\n",
"{\n",
" A[i] = 0;\n",
"}\n",
"```\n",
"\n",
"We have allocated an array `A` outside of our parallel region. This means that `A` is allocated in the CPU memory. However, we access `A` inside of our loop, and that loop is contained within a *parallel region*. Within that parallel region, `A[i]` is attempting to access a memory location within the GPU memory. We didn't explicitly allocate `A` on the GPU, so one of two things will happen.\n",
"\n",
"1. The compiler will understand what we are trying to do, and automatically copy `A` from the CPU to the GPU.\n",
"2. The program will check for an array `A` in GPU memory, it won't find it, and it will throw an error.\n",
"\n",
"Instead of hoping that we have a compiler that can figure this out, we could instead use a *data clause*.\n",
"\n",
"```cpp\n",
"int *A = (int*) malloc(N * sizeof(int));\n",
"\n",
"#pragma acc parallel loop copy(A[0:N])\n",
"for( int i = 0; i < N; i++ )\n",
"{\n",
" A[i] = 0;\n",
"}\n",
"```\n",
"\n",
"We will learn the `copy` data clause first, because it is the easiest to use. With the inclusion of the `copy` data clause, our program will now copy the content of `A` from the CPU memory, into GPU memory. Then, during the execution of the loop, it will properly access `A` from the GPU memory. After the parallel region is finished, our program will copy `A` from the GPU memory back to the CPU memory. Let's look at one more direct example.\n",
"\n",
"```cpp\n",
"int *A = (int*) malloc(N * sizeof(int));\n",
"\n",
"for( int i = 0; i < N; i++ )\n",
"{\n",
" A[i] = 0;\n",
"}\n",
"\n",
"#pragma acc parallel loop copy(A[0:N])\n",
"for( int i = 0; i < N; i++ )\n",
"{\n",
" A[i] = 1;\n",
"}\n",
"```\n",
"\n",
"Now we have two loops; the first loop will execute on the CPU (since it does not have an OpenACC parallel directive), and the second loop will execute on the GPU. Array `A` will be allocated on the CPU, and then the first loop will execute. This loop will set the contents of `A` to be all 0. Then the second loop is encountered; the program will copy the array `A` (which is full of 0's) into GPU memory. Then, we will execute the second loop on the GPU. This will edit the GPU's copy of `A` to be full of 1's.\n",
"\n",
"At this point, we have two separate copies of `A`. The CPU copy is full of 0's, and the GPU copy is full of 1's. Now, after the parallel region finishes, the program will copy `A` back from the GPU to the CPU. After this copy, both the CPU and the GPU will contain a copy of `A` that contains all 1's. The GPU copy of `A` will then be deallocated.\n",
"\n",
"This image offers another step-by-step example of using the copy clause.\n",
"\n",
"\n",
"\n",
"We are also able to copy multiple arrays at once by using the following syntax.\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop copy(A[0:N], B[0:N])\n",
"for( int i = 0; i < N; i++ )\n",
"{\n",
" A[i] = B[i];\n",
"}\n",
"```\n",
"\n",
"Of course, we might not want to copy our data both to and from the GPU memory. Maybe we only need the array's values as inputs to the GPU region, or maybe it's only the final results we care about, or perhaps the array is only used temporarily on the GPU and we don't want to copy it either directive. The following OpenACC data clauses provide a bit more control than just the `copy` clause.\n",
"\n",
"* `copyin` - Create space for the array and copy the input values of the array to the device. At the end of the region, the array is deleted without copying anything back to the host.\n",
"* `copyout` - Create space for the array on the device, but don't initialize it to anything. At the end of the region, copy the results back and then delete the device array.\n",
"* `create` - Create space of the array on the device, but do not copy anything to the device at the beginning of the region, nor back to the host at the end. The array will be deleted from the device at the end of the region.\n",
"* `present` - Don't do anything with these variables. I've put them on the device somewhere else, so just assume they're available.\n",
"\n",
"You may also use them to operate on multiple arrays at once, by including those arrays as a comma separated list.\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop copy( A[0:N], B[0:M], C[0:Q] )\n",
"```\n",
"\n",
"You may also use more than one data clause at a time.\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop create( A[0:N] ) copyin( B[0:M] ) copyout( C[0:Q] )\n",
"```\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Array Shaping\n",
"\n",
"The shape of the array specifies how much data needs to be transferred. Let's look at an example:\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop copy(A[0:N])\n",
"for( int i = 0; i < N; i++ )\n",
"{\n",
" A[i] = 0;\n",
"}\n",
"```\n",
"\n",
"Focusing specifically on the `copy(A[0:N])`, the shape of the array is defined within the brackets. The syntax for array shape is `[starting_index:size]`. This means that (in the code example) we are copying data from array `A`, starting at index 0 (the start of the array), and copying N elements (which is most likely the length of the entire array).\n",
"\n",
"We are also able to only copy a portion of the array:\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop copy(A[1:N-2])\n",
"```\n",
"\n",
"This would copy all of the elements of `A` except for the first, and last element.\n",
"\n",
"Lastly, if you do not specify a starting index, 0 is assumed. This means that\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop copy(A[0:N])\n",
"```\n",
"\n",
"is equivalent to\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop copy(A[:N])\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Making the Sample Code Work without Managed Memory\n",
"\n",
"In order to build our example code without CUDA managed memory we need to give the compiler more information about the arrays. How do our two loop nests use the arrays `A` and `Anew`? The `calcNext` function take `A` as input and generates `Anew` as output, but also needs Anew copied in because we need to maintain that *hot* boundary at the top. So you will want to add a `copyin` clause for `A` and a `copy` clause for `Anew` on your region. The `swap` function takes `Anew` as input and `A` as output, so it needs the exact opposite data clauses. It's also necessary to tell the compiler the size of the two arrays by using array shaping. Our arrays are `m` times `n` in size, so we'll tell the compiler their shape starts at `0` and has `n*m` elements, using the syntax above. Go ahead and add data clauses to the two `parallel loop` directives in `laplace2d.c`.\n",
"\n",
"Click on the [laplace2d.c](../source_code/lab2/laplace2d.c) link and modify `laplace2d.c`. Remember to **SAVE** your code after changes, before running below cells.\n",
"\n",
"Then try to build again."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2 && make clean && make laplace_no_managed && ./laplace"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Well, the good news is that it should have built correctly and run. If it didn't, check your data clauses carefully. The bad news is that now it runs a whole lot slower than it did before. Let's try to figure out why. The NVIDIA HPC compiler provides your executable with built-in timers, so let's start by enabling them and seeing what it shows. You can enable these timers by setting the environment variable `PGI_ACC_TIME=1`. Run the cell below to get the program output with the built-in profiler enabled.\n",
"\n",
"**Note:** Profiling will not be covered in this lab. Please have a look at the supplementary [slides](https://drive.google.com/file/d/1Asxh0bpntlmYxAPjBxOSThFIz7Ssd48b/view?usp=sharing)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2 && make clean && make laplace_no_managed && PGI_ACC_TIME=1 ./laplace "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Your output should look something like what you see below.\n",
"```\n",
" total: 189.014216 s\n",
"\n",
"Accelerator Kernel Timing data\n",
"/labs/lab2/English/C/laplace2d.c\n",
" calcNext NVIDIA devicenum=0\n",
" time(us): 53,290,779\n",
" 47: compute region reached 1000 times\n",
" 47: kernel launched 1000 times\n",
" grid: [4094] block: [128]\n",
" device time(us): total=2,427,090 max=2,447 min=2,406 avg=2,427\n",
" elapsed time(us): total=2,486,633 max=2,516 min=2,464 avg=2,486\n",
" 47: reduction kernel launched 1000 times\n",
" grid: [1] block: [256]\n",
" device time(us): total=19,025 max=20 min=19 avg=19\n",
" elapsed time(us): total=48,308 max=65 min=44 avg=48\n",
" 47: data region reached 4000 times\n",
" 47: data copyin transfers: 17000\n",
" device time(us): total=33,878,622 max=2,146 min=6 avg=1,992\n",
" 57: data copyout transfers: 10000\n",
" device time(us): total=16,966,042 max=2,137 min=9 avg=1,696\n",
"/labs/lab2/English/C/laplace2d.c\n",
" swap NVIDIA devicenum=0\n",
" time(us): 36,214,666\n",
" 62: compute region reached 1000 times\n",
" 62: kernel launched 1000 times\n",
" grid: [4094] block: [128]\n",
" device time(us): total=2,316,826 max=2,331 min=2,305 avg=2,316\n",
" elapsed time(us): total=2,378,419 max=2,426 min=2,366 avg=2,378\n",
" 62: data region reached 2000 times\n",
" 62: data copyin transfers: 8000\n",
" device time(us): total=16,940,591 max=2,352 min=2,114 avg=2,117\n",
" 70: data copyout transfers: 9000\n",
" device time(us): total=16,957,249 max=2,133 min=13 avg=1,884\n",
"```\n",
" \n",
"The total runtime was roughly 190 with the profiler turned on, but only about 130 seconds without. We can see that `calcNext` required roughly 53 seconds to run by looking at the `time(us)` line under the `calcNext` line. We can also look at the `data region` section and determine that 34 seconds were spent copying data to the device and 17 seconds copying data out for the device. The `swap` function has very similar numbers. That means that the program is actually spending very little of its runtime doing calculations. Why is the program copying so much data around? The screenshot below comes from the Nsight Systems profiler and shows part of one step of our outer while loop. The greenish and pink colors are data movement and the blue colors are our kernels (calcNext and swap). Notice that for each kernel we have copies to the device (greenish) before and copies from the device (pink) after. The means we have 4 segments of data copies for every iteration of the outer while loop.\n",
" \n",
"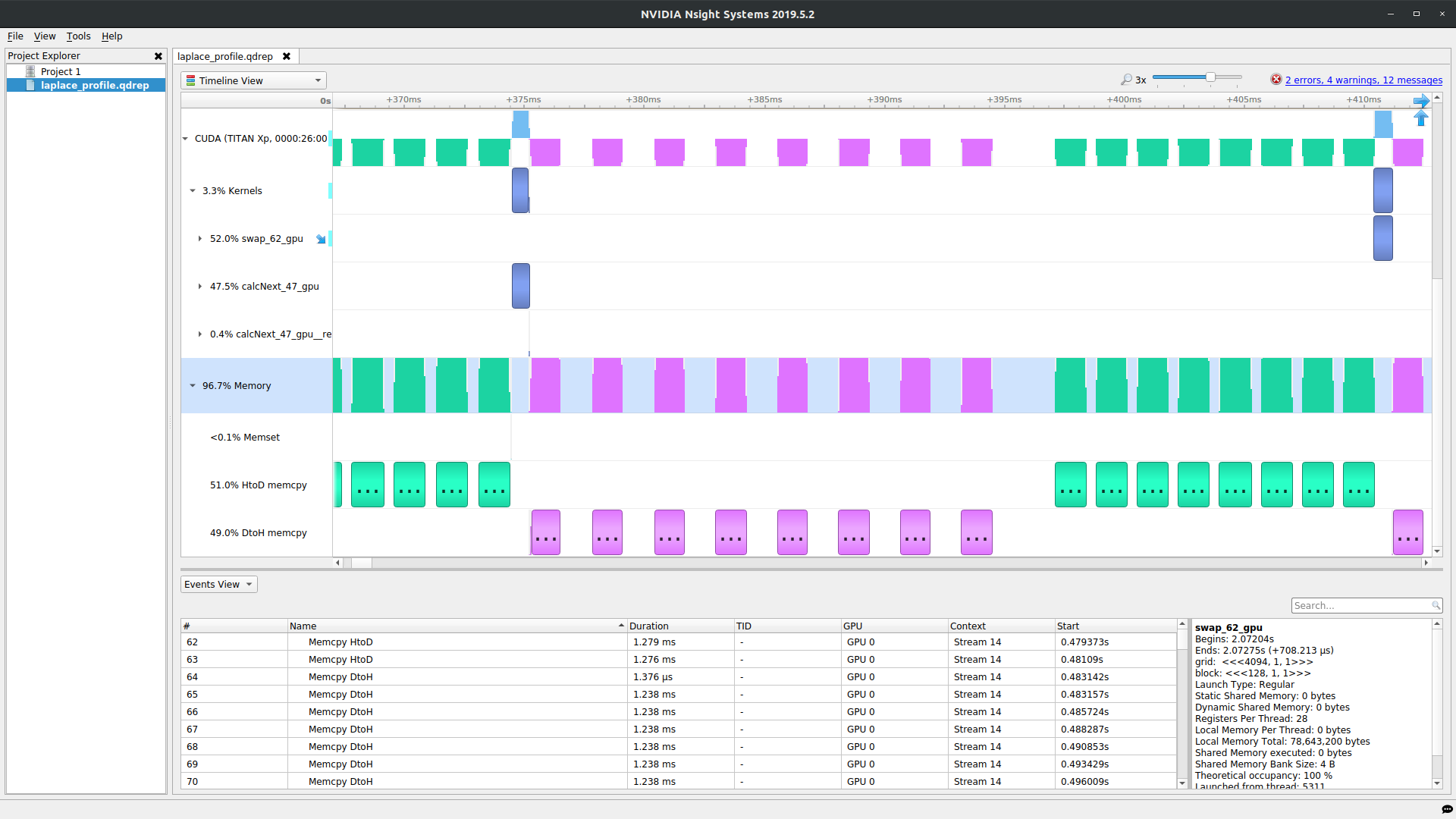\n",
" \n",
"Let's contrast this with the managed memory version. The image below shows the same program built with managed memory. Notice that there's a lot of \"data migration\" at the first kernel launch, where the data is first used, but there's no data movement between kernels after that. This tells me that the data movement isn't really needed between these kernels, but we need to tell the compiler that.\n",
" \n",
"\n",
"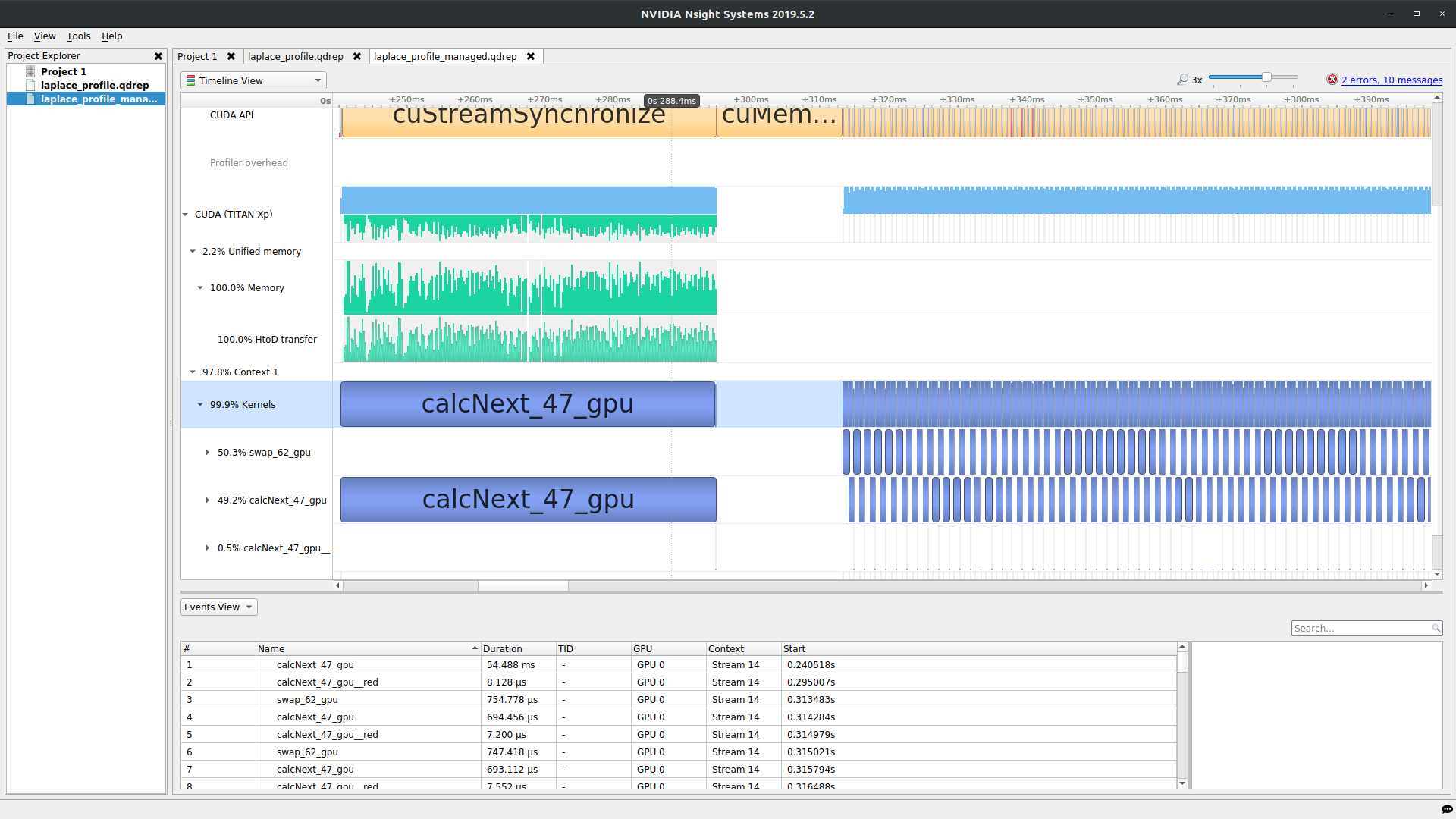\n",
"\n",
"Because the loops are in two separate function, the compiler can't really see that the data is reused on the GPU between those function. We need to move our data movement up to a higher level where we can reuse it for each step through the program. To do that, we'll add OpenACC data directives."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## OpenACC Structured Data Directive\n",
"\n",
"The OpenACC data directives allow the programmer to explicitly manage the data on the device (in our case, the GPU). Specifically, the structured data directive will mark a static region of our code as a **data region**.\n",
"\n",
"```cpp\n",
"< Initialize data on host (CPU) >\n",
"\n",
"#pragma acc data < data clauses >\n",
"{\n",
"\n",
" < Code >\n",
"\n",
"}\n",
"```\n",
"\n",
"Device memory allocation happens at the beginning of the region, and device memory deallocation happens at the end of the region. Additionally, any data movement from the host to the device (CPU to GPU) happens at the beginning of the region, and any data movement from the device to the host (GPU to CPU) happens at the end of the region. Memory allocation/deallocation and data movement is defined by which clauses the programmer includes (the `copy`, `copyin`, `copyout`, and `create` clauses we saw above).\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Encompassing Multiple Compute Regions\n",
"\n",
"A single data region can contain any number of parallel/kernels regions. Take the following example:\n",
"\n",
"```cpp\n",
"#pragma acc data copyin(A[0:N], B[0:N]) create(C[0:N])\n",
"{\n",
"\n",
" #pragma acc parallel loop\n",
" for( int i = 0; i < N; i++ )\n",
" {\n",
" C[i] = A[i] + B[i];\n",
" }\n",
" \n",
" #pragma acc parallel loop\n",
" for( int i = 0; i < N; i++ )\n",
" {\n",
" A[i] = C[i] + B[i];\n",
" }\n",
"\n",
"}\n",
"```\n",
"\n",
"You may also encompass function calls within the data region:\n",
"\n",
"```cpp\n",
"void copy(int *A, int *B, int N)\n",
"{\n",
" #pragma acc parallel loop\n",
" for( int i = 0; i < N; i++ )\n",
" {\n",
" A[i] = B[i];\n",
" }\n",
"}\n",
"\n",
"...\n",
"\n",
"#pragma acc data copyout(A[0:N],B[0:N]) copyin(C[0:N])\n",
"{\n",
" copy(A, C, N);\n",
" \n",
" copy(A, B, N);\n",
"}\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Adding the Structured Data Directive to our Code\n",
"\n",
"Add a structured data directive to the code to properly handle the arrays `A` and `Anew`. We've already added data clauses to our two functions, so this time we'll move up the calltree and add a structured data region around our while loop in the main program. Think about the input and output to this while loop and choose your data clauses for `A` and `Anew` accordingly.\n",
"\n",
"Click on the [jacobi.c](../source_code/lab2/jacobi.c) link and modify `jacobi.c`. Remember to **SAVE** your code after changes, before running below cells.\n",
"\n",
"Then, run the following script to check you solution. You code should run just as good as (or slightly better) than our managed memory code."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2 && make clean && make laplace_no_managed && ./laplace"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Did your runtime go down? It should have but the answer should still match the previous runs. Let's take a look at the profiler now.\n",
"\n",
"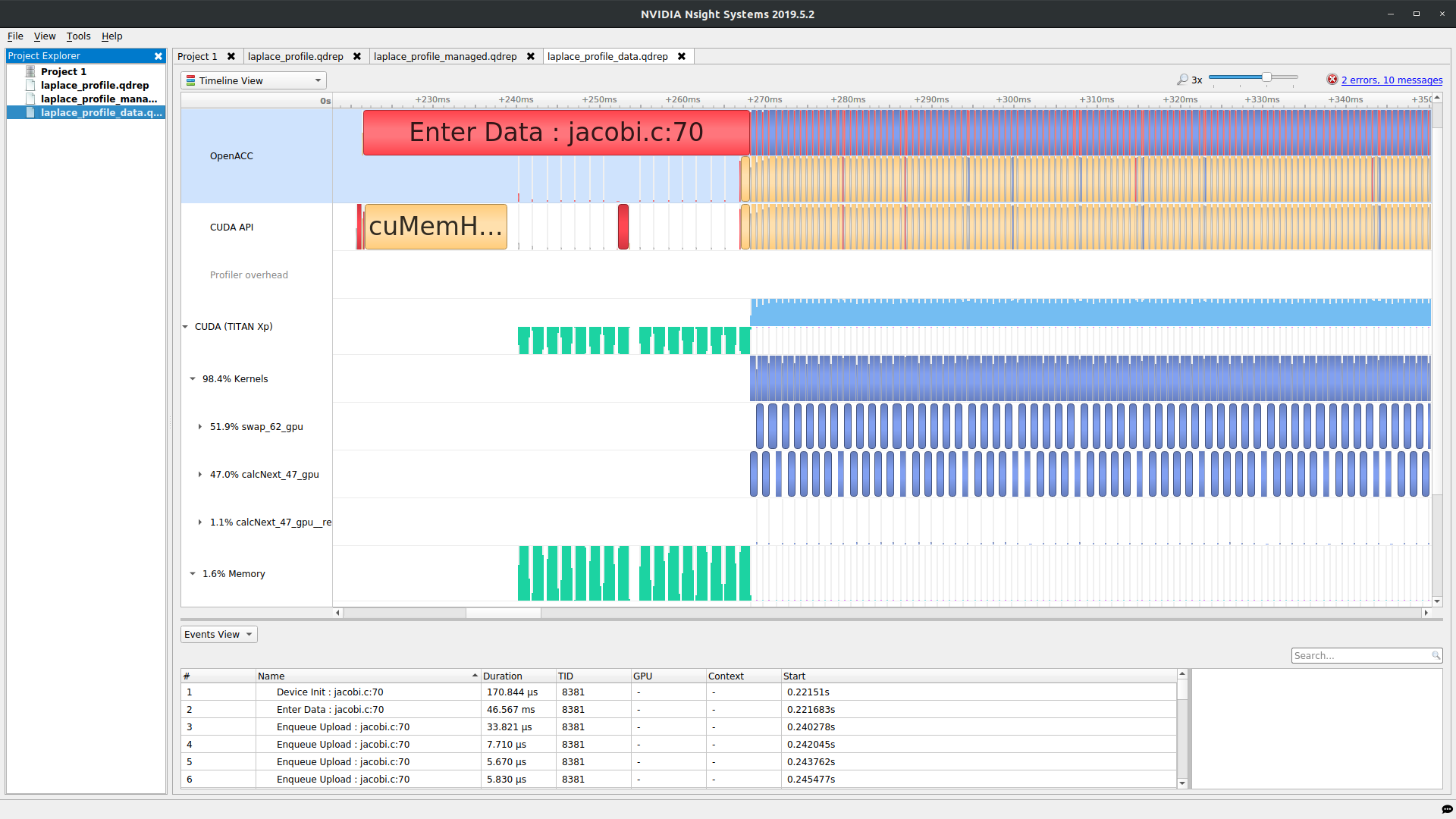\n",
"\n",
"Notice that we no longer see the greenish and pink bars on either side of each iteration, like we did before. Instead, we see a red OpenACC `Enter Data` region which contains some greenish bars corresponding to host-to-device data transfer preceding any GPU kernel launches. This is because our data movement is now handled by the outer data region, not the data clauses on each loop. Data clauses count how many times an array has been placed into device memory and only copies data the outermost time it encounters an array. This means that the data clauses we added to our two functions are now used only for shaping and no data movement will actually occur here anymore, thanks to our outer `data` region.\n",
"\n",
"\n",
"\n",
"This reference counting behavior is really handy for code development and testing. Just like we just did, you can add clauses to each of your OpenACC `parallel loop` or `kernels` regions to get everything running on the accelerator and then just wrap those functions with a data region when you're done and the data movement magically disappears. Furthermore, if you want to isolate one of those functions into a standalone test case you can do so easily, because the data clause is already in the code. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## OpenACC Update Directive\n",
"\n",
"When we use the data clauses you are only able to copy data between host and device memory at the beginning and end of your regions, but what if you need to copy data in the middle? For example, what if we wanted to debug our code by printing out the array every 100 steps to make sure it looks right? In order to transfer data at those times, we can use the `update` directive. The update directive will explicitly transfer data between the host and the device. The `update` directive has two clauses:\n",
"\n",
"* `self` - The self clause will transfer data from the device to the host (GPU to CPU). You will sometimes see this clause called the `host` clause.\n",
"* `device` - The device clause will transfer data from the host to the device (CPU to GPU).\n",
"\n",
"The syntax would look like:\n",
"\n",
"`#pragma acc update self(A[0:N])`\n",
"\n",
"`#pragma acc update device(A[0:N])`\n",
"\n",
"All of the array shaping rules apply.\n",
"\n",
"As an example, let's create a version of our laplace code where we want to print the array `A` after every 100 iterations of our loop. The code will look like this:\n",
"\n",
"```cpp\n",
"#pragma acc data copyin( A[:m*n],Anew[:m*n] )\n",
"{\n",
" while ( error > tol && iter < iter_max )\n",
" {\n",
" error = calcNext(A, Anew, m, n);\n",
" swap(A, Anew, m, n);\n",
" \n",
" if(iter % 100 == 0)\n",
" {\n",
" printf(\"%5d, %0.6f\\n\", iter, error);\n",
" for( int i = 0; i < n; i++ )\n",
" {\n",
" for( int j = 0; j < m; j++ )\n",
" {\n",
" printf(\"%0.2f \", A[i+j*m]);\n",
" }\n",
" printf(\"\\n\");\n",
" }\n",
" }\n",
" \n",
" iter++;\n",
"\n",
" }\n",
"}\n",
"```\n",
"\n",
"Let's run this code (on a very small data set, so that we don't overload the console by printing thousands of numbers)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2/update && make clean && make laplace_no_update && ./laplace_no_update 10 10"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can see that the array is not changing. This is because the host copy of `A` is not being *updated* between loop iterations. Let's add the update directive, and see how the output changes.\n",
"\n",
"```cpp\n",
"#pragma acc data copyin( A[:m*n],Anew[:m*n] )\n",
"{\n",
" while ( error > tol && iter < iter_max )\n",
" {\n",
" error = calcNext(A, Anew, m, n);\n",
" swap(A, Anew, m, n);\n",
" \n",
" if(iter % 100 == 0)\n",
" {\n",
" printf(\"%5d, %0.6f\\n\", iter, error);\n",
" \n",
" #pragma acc update self(A[0:m*n])\n",
" \n",
" for( int i = 0; i < n; i++ )\n",
" {\n",
" for( int j = 0; j < m; j++ )\n",
" {\n",
" printf(\"%0.2f \", A[i+j*m]);\n",
" }\n",
" printf(\"\\n\");\n",
" }\n",
" }\n",
" \n",
" iter++;\n",
"\n",
" }\n",
"}\n",
"```"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2/update/solution && make clean && make laplace_update && ./laplace_update 10 10"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Although you weren't required to add an `update` directive to this example code, except in the contrived example above, it's an extremely important directive for real applications because it allows you to do I/O or communication necessary for your code to execute without having to pay the cost of allocating and decallocating arrays on the device each time you do so."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Conclusion\n",
"\n",
"Relying on managed memory to handle data management can reduce the effort the programmer needs to parallelize their code, however, not all GPUs work with managed memory, and it is also lower performance than using explicit data management. In this lab you learned about how to use *data clauses* and *structured data directives* to explicitly manage device memory and remove your reliance on CUDA Managed Memory. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Bonus Task\n",
"\n",
"If you would like some additional lessons on using OpenACC, there is an Introduction to OpenACC video series available from the OpenACC YouTube page. The fifth video in the series covers a lot of the content that was covered in this lab. \n",
"\n",
"[Introduction to Parallel Programming with OpenACC - Part 5](https://youtu.be/0zTX7-CPvV8) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Post-Lab Summary\n",
"\n",
"If you would like to download this lab for later viewing, it is recommend you go to your browsers File menu (not the Jupyter notebook file menu) and save the complete web page. This will ensure the images are copied down as well.\n",
"\n",
"You can also execute the following cell block to create a zip-file of the files you've been working on, and download it with the link below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%bash\n",
"cd ..\n",
"rm -f openacc_files.zip\n",
"zip -r openacc_files.zip *"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**After** executing the above zip command, you should be able to download and share the zip file by holding down Shift and Right-Clicking [Here](../openacc_files.zip)\n",
"\n",
"--- \n",
"\n",
"## Licensing \n",
"\n",
"This material is released by OpenACC-Standard.org, in collaboration with NVIDIA Corporation, under the Creative Commons Attribution 4.0 International (CC BY 4.0)."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.9"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
\n",
"\n",
"This is the OpenACC 3-Step development cycle.\n",
"\n",
"**Analyze** your code, and predict where potential parallelism can be uncovered. Use profiler to help understand what is happening in the code, and where parallelism may exist.\n",
"\n",
"**Parallelize** your code, starting with the most time consuming parts. Focus on maintaining correct results from your program.\n",
"\n",
"**Optimize** your code, focusing on maximizing performance. Performance may not increase all-at-once during early parallelization.\n",
"\n",
"We are currently tackling the **parallelize** and **optimize** steps by adding the *data clauses* necessary to parallelize the code without CUDA Managed Memory and then *structured data directives* to optimize the data movement of our code."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Run the Code (With Managed Memory)\n",
"\n",
"In the [previous lab](openacc_c_lab1.ipynb), we added OpenACC loop directives and relied on a feature called CUDA Managed Memory to deal with the separate CPU & GPU memories for us. Just adding OpenACC to our two loop nests we achieved a considerable performance boost. However, managed memory is not compatible with all GPUs or all compilers and it sometimes performs worse than programmer-defined memory management. Let's start with our solution from the previous lab and use this as our performance baseline. Note the runtime from the follow cell."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2 && make clean && make laplace_managed && ./laplace_managed"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Optional: Analyze the Code\n",
"\n",
"If you would like a refresher on the code files that we are working on, you may view both of them using the two links below by openning the downloaded file.\n",
"\n",
"[jacobi.c](../source_code/lab2/jacobi.c) \n",
"[laplace2d.c](../source_code/lab2/laplace2d.c) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Building Without Managed Memory\n",
"\n",
"For this exercise we ultimately don't want to use CUDA Managed Memory, so let's remove the managed option from our compiler options. Try building and running the code now. What happens?"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2 && make clean && make laplace_no_managed && ./laplace"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Uh-oh, this time our code failed to build. Let's take a look at the compiler output to understand why:\n",
"\n",
"```\n",
"jacobi.c:\n",
"laplace2d.c:\n",
"NVC++-S-0155-Compiler failed to translate accelerator region (see -Minfo messages): Could not find allocated-variable index for symbol (laplace2d.c: 47)\n",
"calcNext:\n",
" 47, Accelerator kernel generated\n",
" Generating Tesla code\n",
" 48, #pragma acc loop gang /* blockIdx.x */\n",
" 50, #pragma acc loop vector(128) /* threadIdx.x */\n",
" 54, Generating implicit reduction(max:error)\n",
" 48, Accelerator restriction: size of the GPU copy of Anew,A is unknown\n",
" 50, Loop is parallelizable\n",
"NVC++-F-0704-Compilation aborted due to previous errors. (laplace2d.c)\n",
"NVC++/x86-64 Linux 18.7-0: compilation aborted\n",
"```\n",
"\n",
"This error message is not very intuitive, so let me explain it to you.:\n",
"\n",
"* `NVC++-S-0155-Compiler failed to translate accelerator region (see -Minfo messages): Could not find allocated-variable index for symbol (laplace2d.c: 47)` - The compiler doesn't like something about a variable from line 47 of our code.\n",
"* `48, Accelerator restriction: size of the GPU copy of Anew,A is unknown` - I don't see any further information about line 47, but at line 48 the compiler is struggling to understand the size and shape of the arrays Anew and A. It turns out, this is our problem.\n",
"\n",
"So, what these cryptic compiler errors are telling us is that the compiler needs to create copies of A and Anew on the GPU in order to run our code there, but it doesn't know how big they are, so it's giving up. We'll need to give the compiler more information about these arrays before it can move forward, so let's find out how to do that."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## OpenACC Data Clauses\n",
"\n",
"Data clauses allow the programmer to specify data transfers between the host and device (or in our case, the CPU and the GPU). Because they are clauses, they can be added to other directives, such as the `parallel loop` directive that we used in the previous lab. Let's look at an example where we do not use a data clause.\n",
"\n",
"```cpp\n",
"int *A = (int*) malloc(N * sizeof(int));\n",
"\n",
"#pragma acc parallel loop\n",
"for( int i = 0; i < N; i++ )\n",
"{\n",
" A[i] = 0;\n",
"}\n",
"```\n",
"\n",
"We have allocated an array `A` outside of our parallel region. This means that `A` is allocated in the CPU memory. However, we access `A` inside of our loop, and that loop is contained within a *parallel region*. Within that parallel region, `A[i]` is attempting to access a memory location within the GPU memory. We didn't explicitly allocate `A` on the GPU, so one of two things will happen.\n",
"\n",
"1. The compiler will understand what we are trying to do, and automatically copy `A` from the CPU to the GPU.\n",
"2. The program will check for an array `A` in GPU memory, it won't find it, and it will throw an error.\n",
"\n",
"Instead of hoping that we have a compiler that can figure this out, we could instead use a *data clause*.\n",
"\n",
"```cpp\n",
"int *A = (int*) malloc(N * sizeof(int));\n",
"\n",
"#pragma acc parallel loop copy(A[0:N])\n",
"for( int i = 0; i < N; i++ )\n",
"{\n",
" A[i] = 0;\n",
"}\n",
"```\n",
"\n",
"We will learn the `copy` data clause first, because it is the easiest to use. With the inclusion of the `copy` data clause, our program will now copy the content of `A` from the CPU memory, into GPU memory. Then, during the execution of the loop, it will properly access `A` from the GPU memory. After the parallel region is finished, our program will copy `A` from the GPU memory back to the CPU memory. Let's look at one more direct example.\n",
"\n",
"```cpp\n",
"int *A = (int*) malloc(N * sizeof(int));\n",
"\n",
"for( int i = 0; i < N; i++ )\n",
"{\n",
" A[i] = 0;\n",
"}\n",
"\n",
"#pragma acc parallel loop copy(A[0:N])\n",
"for( int i = 0; i < N; i++ )\n",
"{\n",
" A[i] = 1;\n",
"}\n",
"```\n",
"\n",
"Now we have two loops; the first loop will execute on the CPU (since it does not have an OpenACC parallel directive), and the second loop will execute on the GPU. Array `A` will be allocated on the CPU, and then the first loop will execute. This loop will set the contents of `A` to be all 0. Then the second loop is encountered; the program will copy the array `A` (which is full of 0's) into GPU memory. Then, we will execute the second loop on the GPU. This will edit the GPU's copy of `A` to be full of 1's.\n",
"\n",
"At this point, we have two separate copies of `A`. The CPU copy is full of 0's, and the GPU copy is full of 1's. Now, after the parallel region finishes, the program will copy `A` back from the GPU to the CPU. After this copy, both the CPU and the GPU will contain a copy of `A` that contains all 1's. The GPU copy of `A` will then be deallocated.\n",
"\n",
"This image offers another step-by-step example of using the copy clause.\n",
"\n",
"\n",
"\n",
"We are also able to copy multiple arrays at once by using the following syntax.\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop copy(A[0:N], B[0:N])\n",
"for( int i = 0; i < N; i++ )\n",
"{\n",
" A[i] = B[i];\n",
"}\n",
"```\n",
"\n",
"Of course, we might not want to copy our data both to and from the GPU memory. Maybe we only need the array's values as inputs to the GPU region, or maybe it's only the final results we care about, or perhaps the array is only used temporarily on the GPU and we don't want to copy it either directive. The following OpenACC data clauses provide a bit more control than just the `copy` clause.\n",
"\n",
"* `copyin` - Create space for the array and copy the input values of the array to the device. At the end of the region, the array is deleted without copying anything back to the host.\n",
"* `copyout` - Create space for the array on the device, but don't initialize it to anything. At the end of the region, copy the results back and then delete the device array.\n",
"* `create` - Create space of the array on the device, but do not copy anything to the device at the beginning of the region, nor back to the host at the end. The array will be deleted from the device at the end of the region.\n",
"* `present` - Don't do anything with these variables. I've put them on the device somewhere else, so just assume they're available.\n",
"\n",
"You may also use them to operate on multiple arrays at once, by including those arrays as a comma separated list.\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop copy( A[0:N], B[0:M], C[0:Q] )\n",
"```\n",
"\n",
"You may also use more than one data clause at a time.\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop create( A[0:N] ) copyin( B[0:M] ) copyout( C[0:Q] )\n",
"```\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Array Shaping\n",
"\n",
"The shape of the array specifies how much data needs to be transferred. Let's look at an example:\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop copy(A[0:N])\n",
"for( int i = 0; i < N; i++ )\n",
"{\n",
" A[i] = 0;\n",
"}\n",
"```\n",
"\n",
"Focusing specifically on the `copy(A[0:N])`, the shape of the array is defined within the brackets. The syntax for array shape is `[starting_index:size]`. This means that (in the code example) we are copying data from array `A`, starting at index 0 (the start of the array), and copying N elements (which is most likely the length of the entire array).\n",
"\n",
"We are also able to only copy a portion of the array:\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop copy(A[1:N-2])\n",
"```\n",
"\n",
"This would copy all of the elements of `A` except for the first, and last element.\n",
"\n",
"Lastly, if you do not specify a starting index, 0 is assumed. This means that\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop copy(A[0:N])\n",
"```\n",
"\n",
"is equivalent to\n",
"\n",
"```cpp\n",
"#pragma acc parallel loop copy(A[:N])\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Making the Sample Code Work without Managed Memory\n",
"\n",
"In order to build our example code without CUDA managed memory we need to give the compiler more information about the arrays. How do our two loop nests use the arrays `A` and `Anew`? The `calcNext` function take `A` as input and generates `Anew` as output, but also needs Anew copied in because we need to maintain that *hot* boundary at the top. So you will want to add a `copyin` clause for `A` and a `copy` clause for `Anew` on your region. The `swap` function takes `Anew` as input and `A` as output, so it needs the exact opposite data clauses. It's also necessary to tell the compiler the size of the two arrays by using array shaping. Our arrays are `m` times `n` in size, so we'll tell the compiler their shape starts at `0` and has `n*m` elements, using the syntax above. Go ahead and add data clauses to the two `parallel loop` directives in `laplace2d.c`.\n",
"\n",
"Click on the [laplace2d.c](../source_code/lab2/laplace2d.c) link and modify `laplace2d.c`. Remember to **SAVE** your code after changes, before running below cells.\n",
"\n",
"Then try to build again."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2 && make clean && make laplace_no_managed && ./laplace"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Well, the good news is that it should have built correctly and run. If it didn't, check your data clauses carefully. The bad news is that now it runs a whole lot slower than it did before. Let's try to figure out why. The NVIDIA HPC compiler provides your executable with built-in timers, so let's start by enabling them and seeing what it shows. You can enable these timers by setting the environment variable `PGI_ACC_TIME=1`. Run the cell below to get the program output with the built-in profiler enabled.\n",
"\n",
"**Note:** Profiling will not be covered in this lab. Please have a look at the supplementary [slides](https://drive.google.com/file/d/1Asxh0bpntlmYxAPjBxOSThFIz7Ssd48b/view?usp=sharing)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2 && make clean && make laplace_no_managed && PGI_ACC_TIME=1 ./laplace "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Your output should look something like what you see below.\n",
"```\n",
" total: 189.014216 s\n",
"\n",
"Accelerator Kernel Timing data\n",
"/labs/lab2/English/C/laplace2d.c\n",
" calcNext NVIDIA devicenum=0\n",
" time(us): 53,290,779\n",
" 47: compute region reached 1000 times\n",
" 47: kernel launched 1000 times\n",
" grid: [4094] block: [128]\n",
" device time(us): total=2,427,090 max=2,447 min=2,406 avg=2,427\n",
" elapsed time(us): total=2,486,633 max=2,516 min=2,464 avg=2,486\n",
" 47: reduction kernel launched 1000 times\n",
" grid: [1] block: [256]\n",
" device time(us): total=19,025 max=20 min=19 avg=19\n",
" elapsed time(us): total=48,308 max=65 min=44 avg=48\n",
" 47: data region reached 4000 times\n",
" 47: data copyin transfers: 17000\n",
" device time(us): total=33,878,622 max=2,146 min=6 avg=1,992\n",
" 57: data copyout transfers: 10000\n",
" device time(us): total=16,966,042 max=2,137 min=9 avg=1,696\n",
"/labs/lab2/English/C/laplace2d.c\n",
" swap NVIDIA devicenum=0\n",
" time(us): 36,214,666\n",
" 62: compute region reached 1000 times\n",
" 62: kernel launched 1000 times\n",
" grid: [4094] block: [128]\n",
" device time(us): total=2,316,826 max=2,331 min=2,305 avg=2,316\n",
" elapsed time(us): total=2,378,419 max=2,426 min=2,366 avg=2,378\n",
" 62: data region reached 2000 times\n",
" 62: data copyin transfers: 8000\n",
" device time(us): total=16,940,591 max=2,352 min=2,114 avg=2,117\n",
" 70: data copyout transfers: 9000\n",
" device time(us): total=16,957,249 max=2,133 min=13 avg=1,884\n",
"```\n",
" \n",
"The total runtime was roughly 190 with the profiler turned on, but only about 130 seconds without. We can see that `calcNext` required roughly 53 seconds to run by looking at the `time(us)` line under the `calcNext` line. We can also look at the `data region` section and determine that 34 seconds were spent copying data to the device and 17 seconds copying data out for the device. The `swap` function has very similar numbers. That means that the program is actually spending very little of its runtime doing calculations. Why is the program copying so much data around? The screenshot below comes from the Nsight Systems profiler and shows part of one step of our outer while loop. The greenish and pink colors are data movement and the blue colors are our kernels (calcNext and swap). Notice that for each kernel we have copies to the device (greenish) before and copies from the device (pink) after. The means we have 4 segments of data copies for every iteration of the outer while loop.\n",
" \n",
"\n",
" \n",
"Let's contrast this with the managed memory version. The image below shows the same program built with managed memory. Notice that there's a lot of \"data migration\" at the first kernel launch, where the data is first used, but there's no data movement between kernels after that. This tells me that the data movement isn't really needed between these kernels, but we need to tell the compiler that.\n",
" \n",
"\n",
"\n",
"\n",
"Because the loops are in two separate function, the compiler can't really see that the data is reused on the GPU between those function. We need to move our data movement up to a higher level where we can reuse it for each step through the program. To do that, we'll add OpenACC data directives."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## OpenACC Structured Data Directive\n",
"\n",
"The OpenACC data directives allow the programmer to explicitly manage the data on the device (in our case, the GPU). Specifically, the structured data directive will mark a static region of our code as a **data region**.\n",
"\n",
"```cpp\n",
"< Initialize data on host (CPU) >\n",
"\n",
"#pragma acc data < data clauses >\n",
"{\n",
"\n",
" < Code >\n",
"\n",
"}\n",
"```\n",
"\n",
"Device memory allocation happens at the beginning of the region, and device memory deallocation happens at the end of the region. Additionally, any data movement from the host to the device (CPU to GPU) happens at the beginning of the region, and any data movement from the device to the host (GPU to CPU) happens at the end of the region. Memory allocation/deallocation and data movement is defined by which clauses the programmer includes (the `copy`, `copyin`, `copyout`, and `create` clauses we saw above).\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Encompassing Multiple Compute Regions\n",
"\n",
"A single data region can contain any number of parallel/kernels regions. Take the following example:\n",
"\n",
"```cpp\n",
"#pragma acc data copyin(A[0:N], B[0:N]) create(C[0:N])\n",
"{\n",
"\n",
" #pragma acc parallel loop\n",
" for( int i = 0; i < N; i++ )\n",
" {\n",
" C[i] = A[i] + B[i];\n",
" }\n",
" \n",
" #pragma acc parallel loop\n",
" for( int i = 0; i < N; i++ )\n",
" {\n",
" A[i] = C[i] + B[i];\n",
" }\n",
"\n",
"}\n",
"```\n",
"\n",
"You may also encompass function calls within the data region:\n",
"\n",
"```cpp\n",
"void copy(int *A, int *B, int N)\n",
"{\n",
" #pragma acc parallel loop\n",
" for( int i = 0; i < N; i++ )\n",
" {\n",
" A[i] = B[i];\n",
" }\n",
"}\n",
"\n",
"...\n",
"\n",
"#pragma acc data copyout(A[0:N],B[0:N]) copyin(C[0:N])\n",
"{\n",
" copy(A, C, N);\n",
" \n",
" copy(A, B, N);\n",
"}\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Adding the Structured Data Directive to our Code\n",
"\n",
"Add a structured data directive to the code to properly handle the arrays `A` and `Anew`. We've already added data clauses to our two functions, so this time we'll move up the calltree and add a structured data region around our while loop in the main program. Think about the input and output to this while loop and choose your data clauses for `A` and `Anew` accordingly.\n",
"\n",
"Click on the [jacobi.c](../source_code/lab2/jacobi.c) link and modify `jacobi.c`. Remember to **SAVE** your code after changes, before running below cells.\n",
"\n",
"Then, run the following script to check you solution. You code should run just as good as (or slightly better) than our managed memory code."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2 && make clean && make laplace_no_managed && ./laplace"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Did your runtime go down? It should have but the answer should still match the previous runs. Let's take a look at the profiler now.\n",
"\n",
"\n",
"\n",
"Notice that we no longer see the greenish and pink bars on either side of each iteration, like we did before. Instead, we see a red OpenACC `Enter Data` region which contains some greenish bars corresponding to host-to-device data transfer preceding any GPU kernel launches. This is because our data movement is now handled by the outer data region, not the data clauses on each loop. Data clauses count how many times an array has been placed into device memory and only copies data the outermost time it encounters an array. This means that the data clauses we added to our two functions are now used only for shaping and no data movement will actually occur here anymore, thanks to our outer `data` region.\n",
"\n",
"\n",
"\n",
"This reference counting behavior is really handy for code development and testing. Just like we just did, you can add clauses to each of your OpenACC `parallel loop` or `kernels` regions to get everything running on the accelerator and then just wrap those functions with a data region when you're done and the data movement magically disappears. Furthermore, if you want to isolate one of those functions into a standalone test case you can do so easily, because the data clause is already in the code. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## OpenACC Update Directive\n",
"\n",
"When we use the data clauses you are only able to copy data between host and device memory at the beginning and end of your regions, but what if you need to copy data in the middle? For example, what if we wanted to debug our code by printing out the array every 100 steps to make sure it looks right? In order to transfer data at those times, we can use the `update` directive. The update directive will explicitly transfer data between the host and the device. The `update` directive has two clauses:\n",
"\n",
"* `self` - The self clause will transfer data from the device to the host (GPU to CPU). You will sometimes see this clause called the `host` clause.\n",
"* `device` - The device clause will transfer data from the host to the device (CPU to GPU).\n",
"\n",
"The syntax would look like:\n",
"\n",
"`#pragma acc update self(A[0:N])`\n",
"\n",
"`#pragma acc update device(A[0:N])`\n",
"\n",
"All of the array shaping rules apply.\n",
"\n",
"As an example, let's create a version of our laplace code where we want to print the array `A` after every 100 iterations of our loop. The code will look like this:\n",
"\n",
"```cpp\n",
"#pragma acc data copyin( A[:m*n],Anew[:m*n] )\n",
"{\n",
" while ( error > tol && iter < iter_max )\n",
" {\n",
" error = calcNext(A, Anew, m, n);\n",
" swap(A, Anew, m, n);\n",
" \n",
" if(iter % 100 == 0)\n",
" {\n",
" printf(\"%5d, %0.6f\\n\", iter, error);\n",
" for( int i = 0; i < n; i++ )\n",
" {\n",
" for( int j = 0; j < m; j++ )\n",
" {\n",
" printf(\"%0.2f \", A[i+j*m]);\n",
" }\n",
" printf(\"\\n\");\n",
" }\n",
" }\n",
" \n",
" iter++;\n",
"\n",
" }\n",
"}\n",
"```\n",
"\n",
"Let's run this code (on a very small data set, so that we don't overload the console by printing thousands of numbers)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2/update && make clean && make laplace_no_update && ./laplace_no_update 10 10"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can see that the array is not changing. This is because the host copy of `A` is not being *updated* between loop iterations. Let's add the update directive, and see how the output changes.\n",
"\n",
"```cpp\n",
"#pragma acc data copyin( A[:m*n],Anew[:m*n] )\n",
"{\n",
" while ( error > tol && iter < iter_max )\n",
" {\n",
" error = calcNext(A, Anew, m, n);\n",
" swap(A, Anew, m, n);\n",
" \n",
" if(iter % 100 == 0)\n",
" {\n",
" printf(\"%5d, %0.6f\\n\", iter, error);\n",
" \n",
" #pragma acc update self(A[0:m*n])\n",
" \n",
" for( int i = 0; i < n; i++ )\n",
" {\n",
" for( int j = 0; j < m; j++ )\n",
" {\n",
" printf(\"%0.2f \", A[i+j*m]);\n",
" }\n",
" printf(\"\\n\");\n",
" }\n",
" }\n",
" \n",
" iter++;\n",
"\n",
" }\n",
"}\n",
"```"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!cd ../source_code/lab2/update/solution && make clean && make laplace_update && ./laplace_update 10 10"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Although you weren't required to add an `update` directive to this example code, except in the contrived example above, it's an extremely important directive for real applications because it allows you to do I/O or communication necessary for your code to execute without having to pay the cost of allocating and decallocating arrays on the device each time you do so."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Conclusion\n",
"\n",
"Relying on managed memory to handle data management can reduce the effort the programmer needs to parallelize their code, however, not all GPUs work with managed memory, and it is also lower performance than using explicit data management. In this lab you learned about how to use *data clauses* and *structured data directives* to explicitly manage device memory and remove your reliance on CUDA Managed Memory. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Bonus Task\n",
"\n",
"If you would like some additional lessons on using OpenACC, there is an Introduction to OpenACC video series available from the OpenACC YouTube page. The fifth video in the series covers a lot of the content that was covered in this lab. \n",
"\n",
"[Introduction to Parallel Programming with OpenACC - Part 5](https://youtu.be/0zTX7-CPvV8) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Post-Lab Summary\n",
"\n",
"If you would like to download this lab for later viewing, it is recommend you go to your browsers File menu (not the Jupyter notebook file menu) and save the complete web page. This will ensure the images are copied down as well.\n",
"\n",
"You can also execute the following cell block to create a zip-file of the files you've been working on, and download it with the link below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%bash\n",
"cd ..\n",
"rm -f openacc_files.zip\n",
"zip -r openacc_files.zip *"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**After** executing the above zip command, you should be able to download and share the zip file by holding down Shift and Right-Clicking [Here](../openacc_files.zip)\n",
"\n",
"--- \n",
"\n",
"## Licensing \n",
"\n",
"This material is released by OpenACC-Standard.org, in collaboration with NVIDIA Corporation, under the Creative Commons Attribution 4.0 International (CC BY 4.0)."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.9"
}
},
"nbformat": 4,
"nbformat_minor": 4
}