
Minimalistic Gridworld Environment (MiniGrid)
 Maxime Chevalier-Boisvert
fad2fc94ee
Modified fetch env for flat encoding
Maxime Chevalier-Boisvert
fad2fc94ee
Modified fetch env for flat encoding
|
6 년 전 | |
|---|---|---|
| figures | 6 년 전 | |
| gym_minigrid | 6 년 전 | |
| pytorch-rl | 6 년 전 | |
| .gitignore | 7 년 전 | |
| LICENSE | 7 년 전 | |
| README.md | 6 년 전 | |
| run_tests.py | 6 년 전 | |
| setup.py | 6 년 전 | |
| standalone.py | 7 년 전 |
README.md
Minimalistic Gridworld Environment (MiniGrid)
There are other gridworld Gym environments out there, but this one is designed to be particularly simple, lightweight and fast. The code has very few dependencies, making it less likely to break or fail to install. It loads no external sprites/textures, and it can run at up to 5800 FPS on a quad-core laptop, which means you can run your experiments faster. Batteries are included: a known-working RL implementation is supplied in this repository to help you get started.
Requirements:
- Python 3
- OpenAI Gym
- NumPy
- PyQT 5 for graphics
This environment has been built at the MILA as part of the Baby AI Game project.
Installation
Clone this repository and install the other dependencies with pip3:
git clone https://github.com/maximecb/gym-minigrid.git
cd gym-minigrid
pip3 install -e .
Optionally, if you wish use the reinforcement learning code included under /pytorch-rl, you can install its dependencies as follows:
cd pytorch-rl
# PyTorch
conda install pytorch torchvision -c soumith
# Dependencies needed by OpenAI baselines
sudo apt install libopenmpi-dev zlib1g-dev cmake
# OpenAI baselines
git clone https://github.com/openai/baselines.git
cd baselines
pip3 install -e .
cd ..
# Other requirements
pip3 install -r requirements.txt
Note: the pytorch-rl code is a custom fork of this repository, which was modified to work with this environment.
Basic Usage
To run the standalone UI application, which allows you to manually control the agent with the arrow keys:
./standalone.py
The environment being run can be selected with the --env-name option, eg:
./standalone.py --env-name MiniGrid-Empty-8x8-v0
Basic reinforcement learning code is provided in the pytorch-rl subdirectory.
You can perform training using the ACKTR algorithm with:
python3 pytorch-rl/main.py --env-name MiniGrid-Empty-6x6-v0 --no-vis --num-processes 32 --algo acktr
You can view the result of training using the enjoy.py script:
python3 pytorch-rl/enjoy.py --env-name MiniGrid-Empty-6x6-v0 --load-dir ./trained_models/acktr
Design
The environment is partially observable and uses a compact and efficient encoding, with just 3 inputs per visible grid cell. It is also easy to produce an array of pixels for observations if desired.
Each cell/tile in the grid world contains one object, each object has an associated discrete color. The objects currently supported are walls, doors, locked doors, keys, balls,boxes and a goal square. The basic version of the environment has just 4 possible actions: turn left, turn right, move forward and pickup/toggle to interact with objects. The agent can carry one carryable item at a time (eg: ball or key). By default, only sparse rewards for reaching the goal square are provided.
Extending the environment with new object types and dynamics should be very easy. If you wish to do this, you should take a look at the gym_minigrid/minigrid.py source file.
Included Environments
The environments listed below are implemented in the gym_minigrid/envs directory. Each environment provides one or more configurations registered with OpenAI gym. Each environment is also programmatically tunable in terms of size/complexity, which is useful for curriculum learning or to fine-tune difficulty.
Empty environment
Registered configurations:
MiniGrid-Empty-6x6-v0MiniGrid-Empty-8x8-v0MiniGrid-Empty-16x16-v0
![]()
This environment is an empty room, and the goal of the agent is to reach the green goal square, which provides a sparse reward. A small penalty is subtracted for the number of steps to reach the goal. This environment is useful, with small rooms, to validate that your RL algorithm works correctly, and with large rooms to experiment with sparse rewards.
Door & key environment
Registered configurations:
MiniGrid-DoorKey-5x5-v0MiniGrid-DoorKey-6x6-v0MiniGrid-DoorKey-8x8-v0MiniGrid-DoorKey-16x16-v0

This environment has a key that the agent must pick up in order to unlock a goal and then get to the green goal square. This environment is difficult, because of the sparse reward, to solve using classical RL algorithms. It is useful to experiment with curiosity or curriculum learning.
Multi-room environment
Registered configurations:
MiniGrid-MultiRoom-N6-v0

This environment has a series of connected rooms with doors that must be opened in order to get to the next room. The final room has the green goal square the agent must get to. This environment is extremely difficult to solve using classical RL. However, by gradually increasing the number of rooms and building a curriculum, the environment can be solved.
Fetch environment
Registered configurations:
MiniGrid-Fetch-5x5-N2-v0MiniGrid-Fetch-8x8-N3-v0
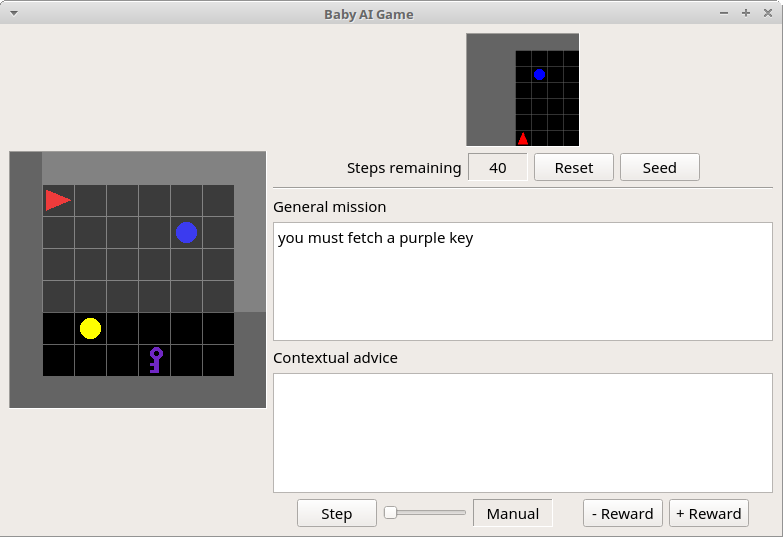
This environment has multiple objects of assorted types and colors. The agent receives a textual string as part of its observation telling it which object to pick up. Picking up the wrong object produces a negative reward.
Four room question answering environment
Registered configurations:
MiniGrid-FourRoomQA-v0

This environment is inspired by the Embodied Question Answering paper. The question are of the form:
Are there any keys in the red room?
There are four colored rooms, and the agent starts at a random position in the grid. Multiple objects of different types and colors are also placed at random positions in random rooms. A question and answer pair is generated, the question is given to the agent as an observation, and the agent has a limited number of time steps to explore the environment and produce a response. This environment can be easily modified to add more question types or to diversify the way the questions are phrased.