Maxime Chevalier-Boisvert
80b3178610
Moved rl code to pytorch-rl. Fixed warnings. Fixed issue w/ flat obs.
Maxime Chevalier-Boisvert
80b3178610
Moved rl code to pytorch-rl. Fixed warnings. Fixed issue w/ flat obs.
|
8 년 전 | |
|---|---|---|
| .. | ||
| imgs | 8 년 전 | |
| LICENSE | 8 년 전 | |
| README.md | 8 년 전 | |
| arguments.py | 8 년 전 | |
| distributions.py | 8 년 전 | |
| enjoy.py | 8 년 전 | |
| envs.py | 8 년 전 | |
| kfac.py | 8 년 전 | |
| main.py | 8 년 전 | |
| model.py | 8 년 전 | |
| requirements.txt | 8 년 전 | |
| storage.py | 8 년 전 | |
| utils.py | 8 년 전 | |
| visualize.py | 8 년 전 | |
README.md
pytorch-a2c-ppo-acktr
Update 10/06/2017: added enjoy.py and a link to pretrained models!
Update 09/27/2017: now supports both Atari and MuJoCo/Roboschool!
This is a PyTorch implementation of
- Advantage Actor Critic (A2C), a synchronous deterministic version of A3C
- Proximal Policy Optimization PPO
- Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation ACKTR
Also see the OpenAI posts: A2C/ACKTR and PPO for more information.
This implementation is inspired by the OpenAI baselines for A2C, ACKTR and PPO. It uses the same hyper parameters and the model since they were well tuned for Atari games.
Supported (and tested) environments (via OpenAI Gym)
- Atari Learning Environment
- MuJoCo
- PyBullet (including Racecar, Minitaur and Kuka)
I highly recommend PyBullet as a free open source alternative to MuJoCo for continuous control tasks.
All environments are operated using exactly the same Gym interface. See their documentations for a comprehensive list.
Requirements
- Python 3 (it might work with Python 2, but I didn't test it)
- PyTorch
- Visdom
- OpenAI baselines
In order to install requirements, follow:
# PyTorch
conda install pytorch torchvision -c soumith
# Baselines for Atari preprocessing
git clone https://github.com/openai/baselines.git
cd baselines
pip install -e .
# Other requirements
pip install -r requirements.txt
Contributions
Contributions are very welcome. If you know how to make this code better, don't hesitate to send a pull request. Also see a todo list below.
Also I'm searching for volunteers to run all experiments on Atari and MuJoCo (with multiple random seeds).
Disclaimer
It's extremely difficult to reproduce results for Reinforcement Learning methods. See "Deep Reinforcement Learning that Matters" for more information. I tried to reproduce OpenAI results as closely as possible. However, majors differences in performance can be caused even by minor differences in TensorFlow and PyTorch libraries.
TODO
- Improve this README file. Rearrange images.
- Improve performance of KFAC, see kfac.py for more information
- Run evaluation for all games and algorithms
Training
Start a Visdom server with python -m visdom.server, it will serve http://localhost:8097/ by default.
Atari
A2C
python main.py --env-name "PongNoFrameskip-v4"
PPO
python main.py --env-name "PongNoFrameskip-v4" --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --num-processes 8 --num-steps 128 --num-mini-batch 4 --vis-interval 1 --log-interval 1
ACKTR
python main.py --env-name "PongNoFrameskip-v4" --algo acktr --num-processes 32 --num-steps 20
MuJoCo
A2C
python main.py --env-name "Reacher-v1" --num-stack 1 --num-frames 1000000
PPO
python main.py --env-name "Reacher-v1" --algo ppo --use-gae --vis-interval 1 --log-interval 1 --num-stack 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --tau 0.95 --num-frames 1000000
ACKTR
ACKTR requires some modifications to be made specifically for MuJoCo. But at the moment, I want to keep this code as unified as possible. Thus, I'm going for better ways to integrate it into the codebase.
Enjoy
Load a pretrained model from my Google Drive.
Also pretrained models for other games are available on request. Send me an email or create an issue, and I will upload it.
Disclaimer: I might have used different hyper-parameters to train these models.
Atari
python enjoy.py --load-dir trained_models/a2c --env-name "PongNoFrameskip-v4" --num-stack 4
MuJoCo
python enjoy.py --load-dir trained_models/ppo --env-name "Reacher-v1" --num-stack 1
Results
A2C
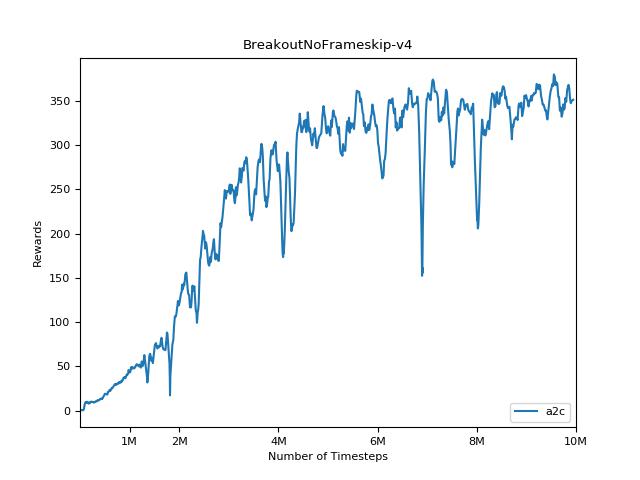
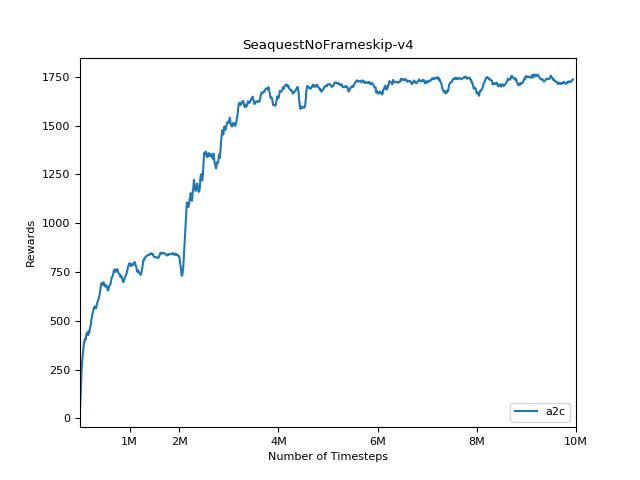
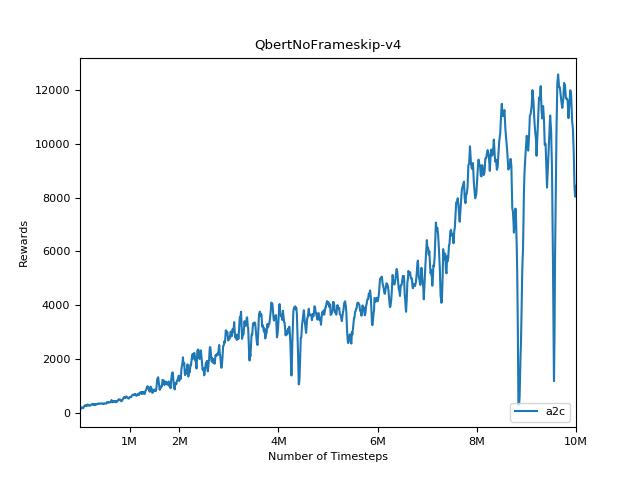
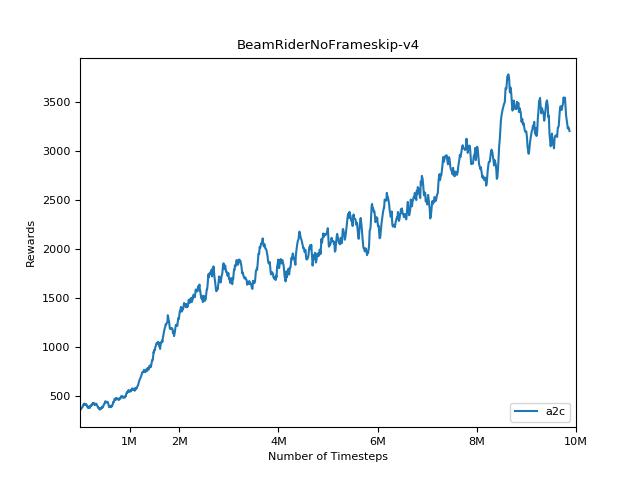
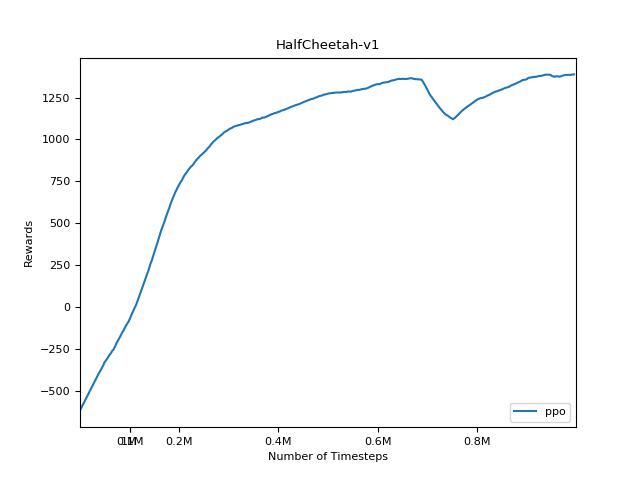
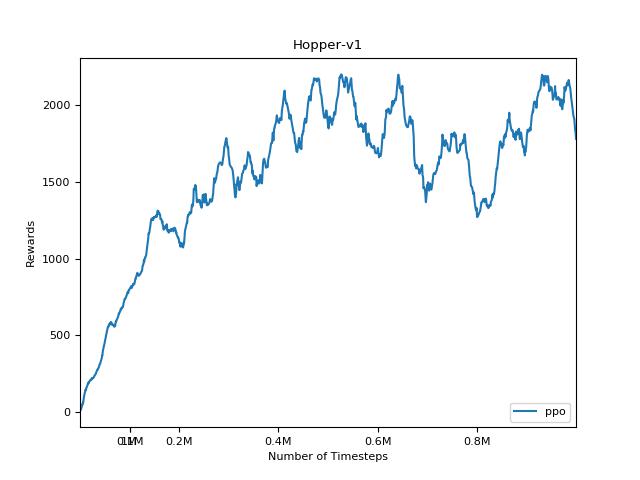
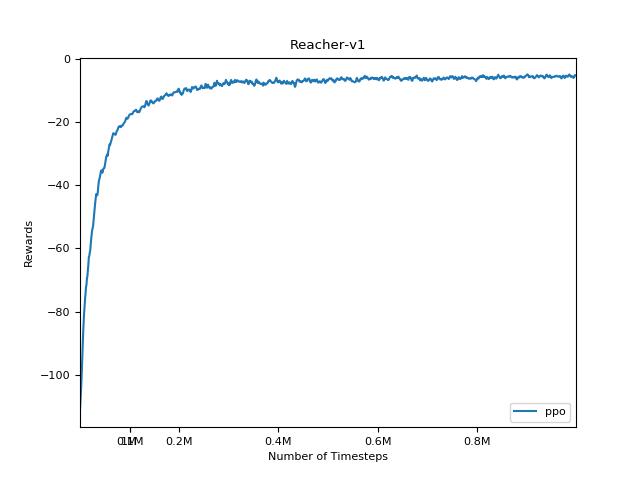
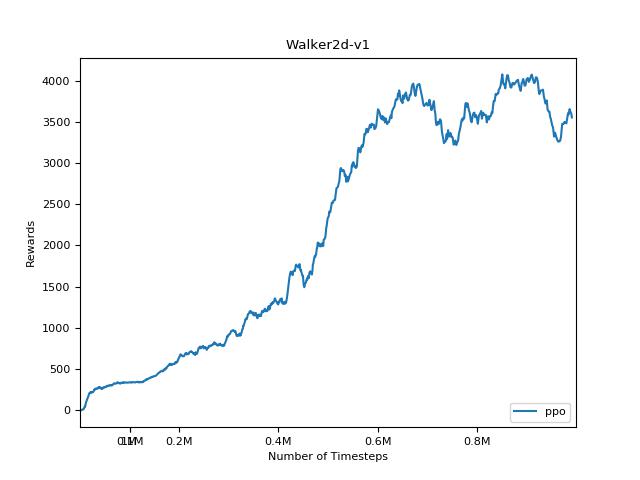
PPO
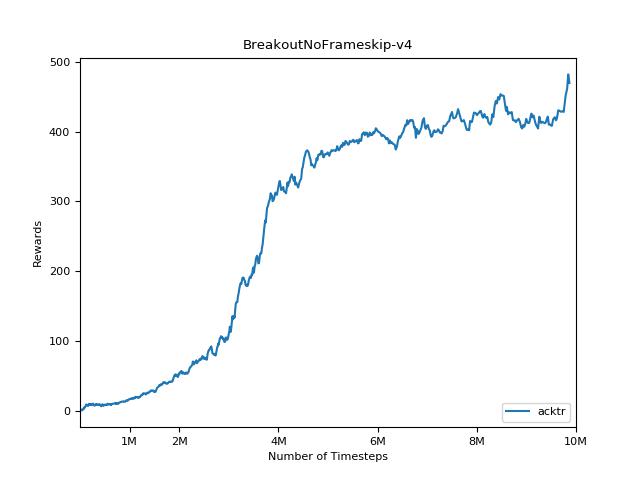
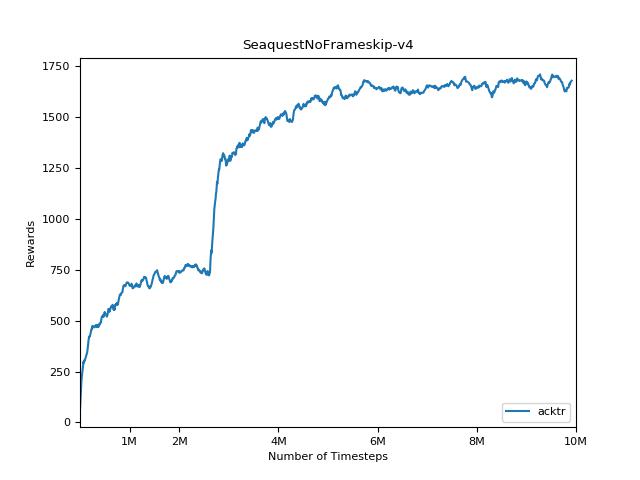
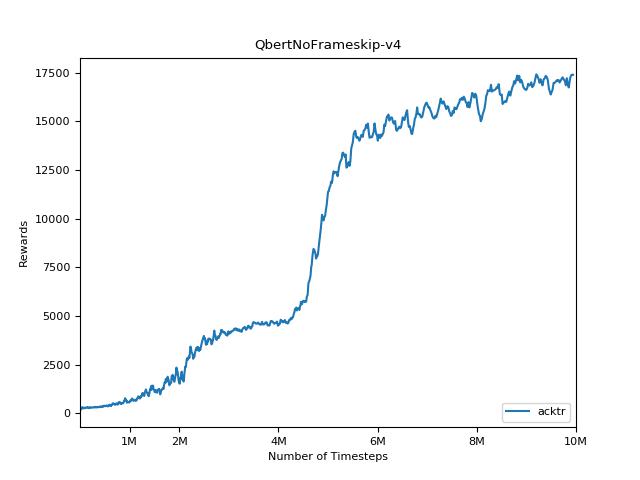
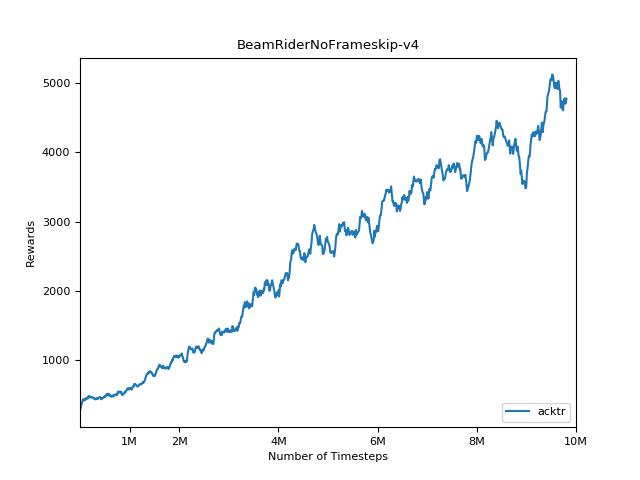
ACKTR