
 WillKoehrsen
ecd53446f5
Done with notebook
WillKoehrsen
ecd53446f5
Done with notebook
|
6 年之前 | |
|---|---|---|
| .. | ||
| .pytest_cache | 6 年之前 | |
| data | 6 年之前 | |
| images | 6 年之前 | |
| Development.ipynb | 6 年之前 | |
| Fitting.ipynb | 6 年之前 | |
| Medium Stats Analysis.ipynb | 6 年之前 | |
| Time Series Analysis.ipynb | 6 年之前 | |
| Work In Progress.ipynb | 6 年之前 | |
| bargraphs.py | 6 年之前 | |
| data-science-writing-2018.ipynb | 6 年之前 | |
| readme.md | 6 年之前 | |
| retrieval.py | 6 年之前 | |
| view_extraction.py | 6 年之前 | |
| visuals.py | 6 年之前 | |
readme.md
Tools for analyzing Medium article statistics
The Medium stats Python toolkit is a suite of tools for retrieving, analyzing, predicting, and visualizing
your Medium article stats. You can also run on my Medium statistics
which are located in data/
Note: running on Mac may first require setting
export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YESfrom the command line to enable parallel processingFor complete usage refer to
Medium Stats AnalysisData retrieval code lives in
retrieval.pyVisualization and analysis code is in
visuals.pySee also the Medium article "Medium Analysis in Python"
Contributions are welcome and appreciated
For help contact wjk68@case.edu or twitter.com/@koehrsen_will
Basic usage
Use your own Medium statistics
- Go to the stats page https://medium.com/me/stats
- Scroll all the way down to the bottom so all the articles are loaded
- Right click, and hit 'save as'
- Save the file as
stats.htmlin thedata/directory. You can also save the responses to do a similar analysis.
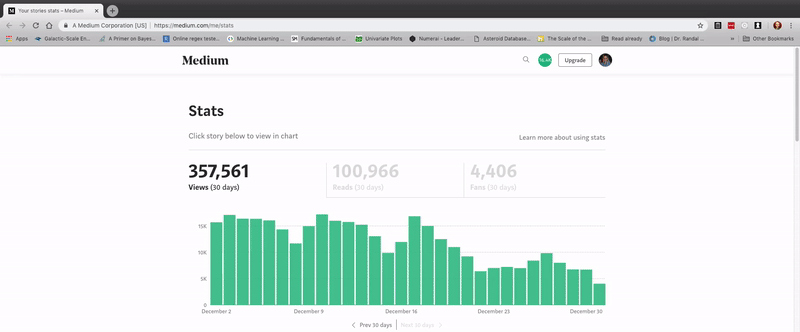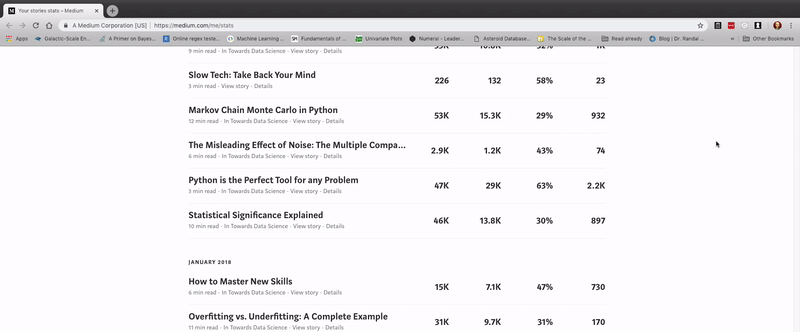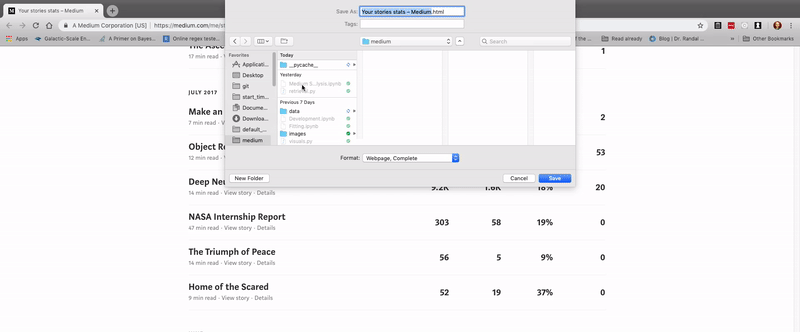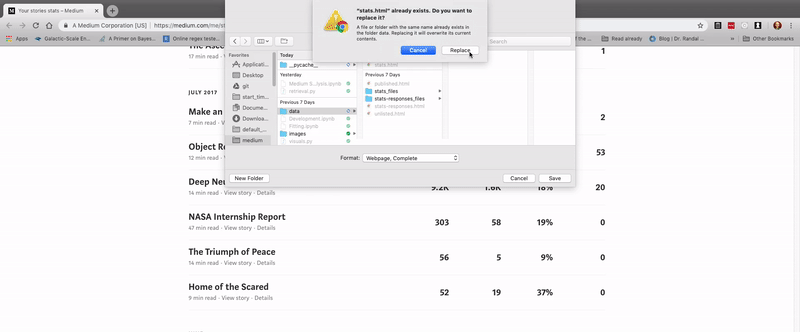
If you don't do this, you can still go to the next step and use the provided data!
Retrieving Statistics
- Open up a Jupyter Notebook or Python terminal in the
medium/directory and run
from retrieval import get_data
df = get_data(fname='stats.html')
Analysis and Visualization
- Interactive plots are not rendered on GitHub. To view the plots with their full
capability, use NBviewer (
Medium Stats Analysison NBviewer) All plots can be opened in the plotly online editor to finish up for publication
Histogram:
make_hist(df, x, category=None)Cumulative plot:
make_cum_plot(df, y, category=None, ranges=False)Scatter plots:
make_scatter_plot(df, x, y, fits=None, xlog=False, ylog=False, category=None, scale=None, sizeref=2, annotations=None, ranges=False, title_override=None)Scatter plot with three variables: pass in
categoryorscaletomake_scatter_plotUnivariate Linear Regression:
make_linear_regression(df, x, y, intercept_0)Univariate polynomial fitting:
make_poly_fits(df, x, y, degree=6)Multivariate Linear Regression: pass in list of
xtomake_linear_regressionFuture extrapolation:
make_extrapolation(df, y, years, degree=4)More methods will be coming soon!
Submit pull requests with your own code, or open issues for suggestions!