|
|
@@ -1,51 +1,63 @@
|
|
|
-# GPT Crawler
|
|
|
+<!-- Markdown written with https://marketplace.visualstudio.com/items?itemName=yzhang.markdown-all-in-one -->
|
|
|
+
|
|
|
+# GPT Crawler <!-- omit from toc -->
|
|
|
|
|
|
Crawl a site to generate knowledge files to create your own custom GPT from one or multiple URLs
|
|
|
|
|
|
|
|
|
|
|
|
+- [Example](#example)
|
|
|
+- [Get started](#get-started)
|
|
|
+ - [Running locally](#running-locally)
|
|
|
+ - [Clone the repository](#clone-the-repository)
|
|
|
+ - [Install dependencies](#install-dependencies)
|
|
|
+ - [Configure the crawler](#configure-the-crawler)
|
|
|
+ - [Run your crawler](#run-your-crawler)
|
|
|
+ - [Alternative methods](#alternative-methods)
|
|
|
+ - [Running in a container with Docker](#running-in-a-container-with-docker)
|
|
|
+ - [Running as a CLI](#running-as-a-cli)
|
|
|
+ - [Development](#development)
|
|
|
+ - [Upload your data to OpenAI](#upload-your-data-to-openai)
|
|
|
+ - [Create a custom GPT](#create-a-custom-gpt)
|
|
|
+ - [Create a custom assistant](#create-a-custom-assistant)
|
|
|
+- [Contributing](#contributing)
|
|
|
|
|
|
## Example
|
|
|
|
|
|
-[Here is a custom GPT](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) that I quickly made to help answer questions about how to use and integrate [Builder.io](https://www.builder.io) by simply providing the URL to the Builder docs.
|
|
|
+[Here is a custom GPT](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) that I quickly made to help answer questions about how to use and integrate [Builder.io](https://www.builder.io) by simply providing the URL to the Builder docs.
|
|
|
|
|
|
This project crawled the docs and generated the file that I uploaded as the basis for the custom GPT.
|
|
|
|
|
|
-[Try it out yourself](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) by asking questions about how to integrate Builder.io into a site.
|
|
|
+[Try it out yourself](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) by asking questions about how to integrate Builder.io into a site.
|
|
|
|
|
|
> Note that you may need a paid ChatGPT plan to access this feature
|
|
|
|
|
|
## Get started
|
|
|
|
|
|
-### Prerequisites
|
|
|
+### Running locally
|
|
|
|
|
|
-Be sure you have Node.js >= 16 installed
|
|
|
+#### Clone the repository
|
|
|
|
|
|
-### Clone the repo
|
|
|
+Be sure you have Node.js >= 16 installed.
|
|
|
|
|
|
```sh
|
|
|
git clone https://github.com/builderio/gpt-crawler
|
|
|
```
|
|
|
|
|
|
-### Install Dependencies
|
|
|
+#### Install dependencies
|
|
|
|
|
|
```sh
|
|
|
npm i
|
|
|
```
|
|
|
|
|
|
-If you do not have Playwright installed:
|
|
|
-```sh
|
|
|
-npx playwright install
|
|
|
-```
|
|
|
-
|
|
|
-### Configure the crawler
|
|
|
+#### Configure the crawler
|
|
|
|
|
|
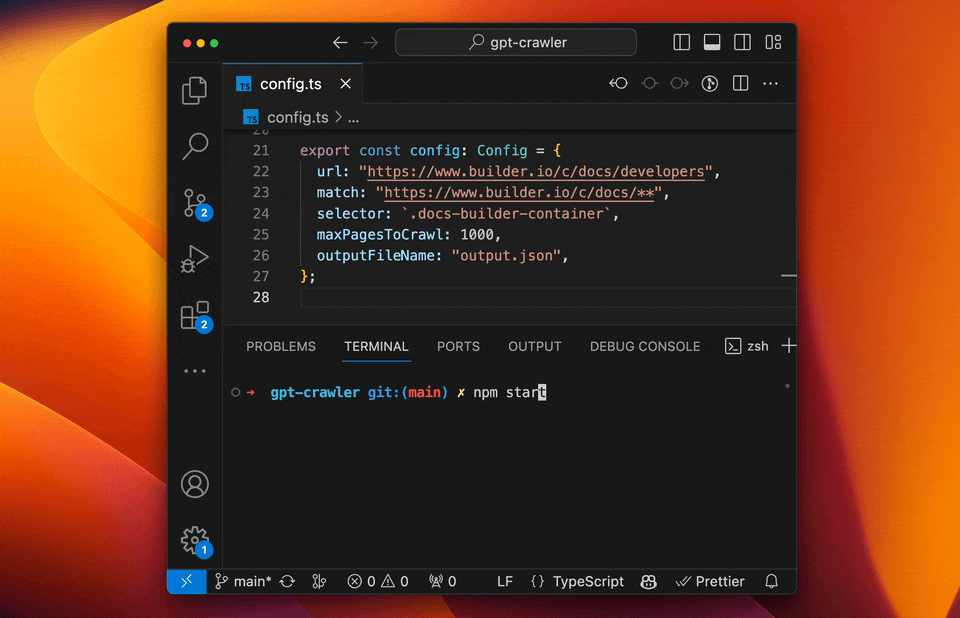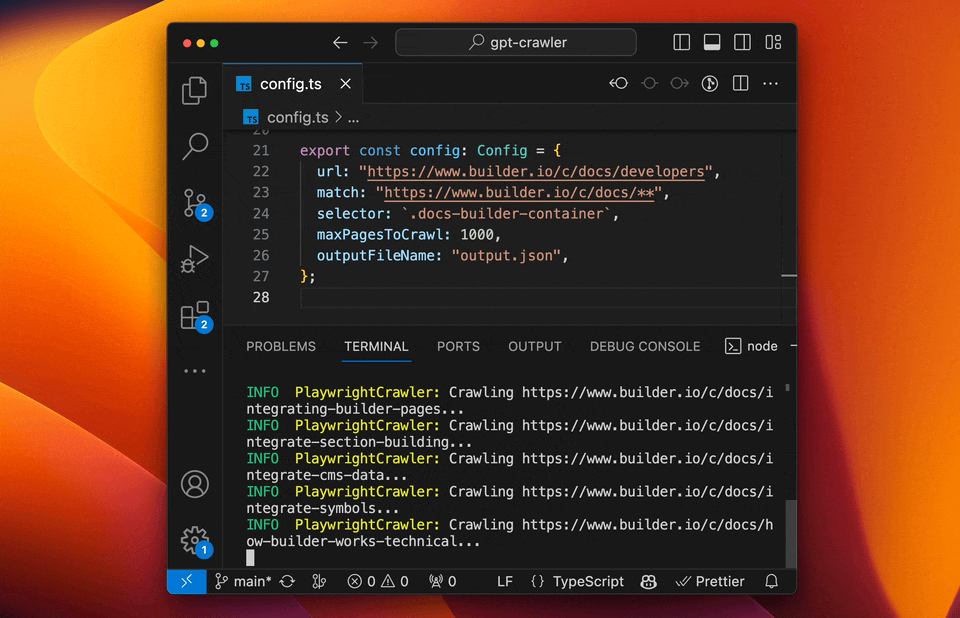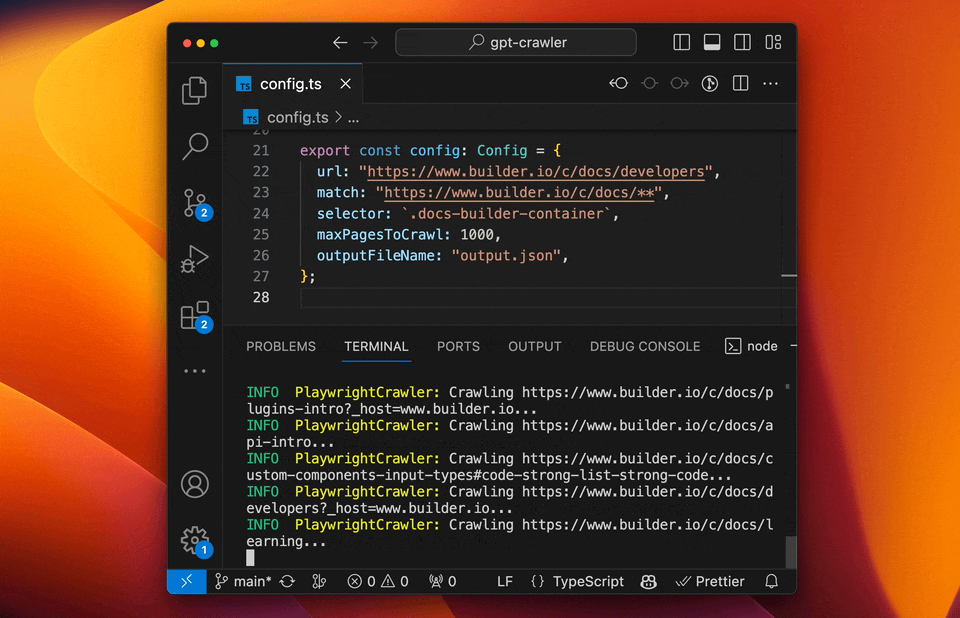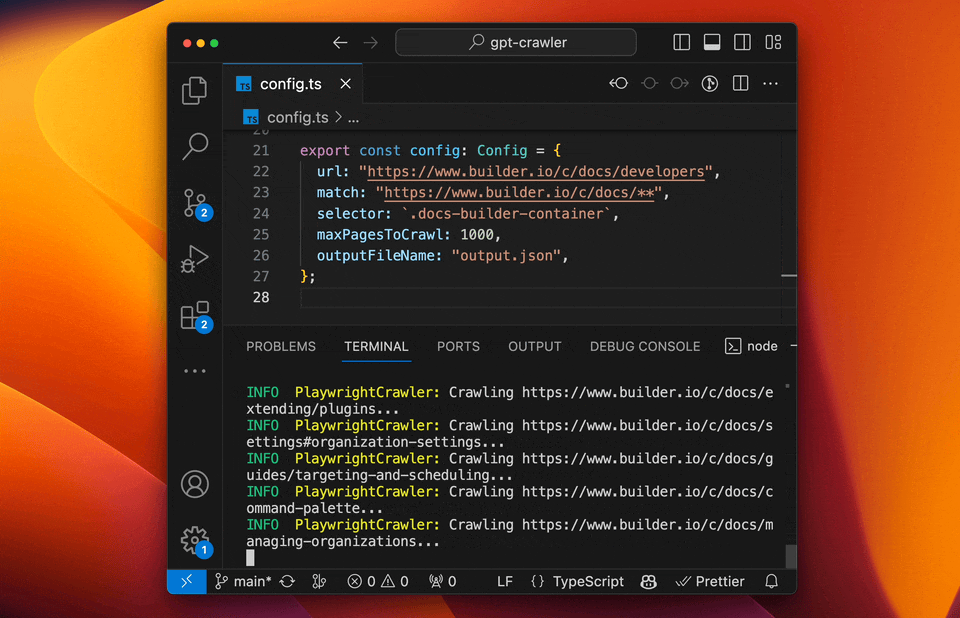
Open [config.ts](config.ts) and edit the `url` and `selectors` properties to match your needs.
|
|
|
|
|
|
E.g. to crawl the Builder.io docs to make our custom GPT you can use:
|
|
|
|
|
|
```ts
|
|
|
-export const config: Config = {
|
|
|
+export const defaultConfig: Config = {
|
|
|
url: "https://www.builder.io/c/docs/developers",
|
|
|
match: "https://www.builder.io/c/docs/**",
|
|
|
selector: `.docs-builder-container`,
|
|
|
@@ -69,23 +81,41 @@ type Config = {
|
|
|
/** File name for the finished data */
|
|
|
outputFileName: string;
|
|
|
/** Optional cookie to be set. E.g. for Cookie Consent */
|
|
|
- cookie?: {name: string; value: string}
|
|
|
+ cookie?: { name: string; value: string };
|
|
|
/** Optional function to run for each page found */
|
|
|
onVisitPage?: (options: {
|
|
|
page: Page;
|
|
|
pushData: (data: any) => Promise<void>;
|
|
|
}) => Promise<void>;
|
|
|
- /** Optional timeout for waiting for a selector to appear */
|
|
|
- waitForSelectorTimeout?: number;
|
|
|
+ /** Optional timeout for waiting for a selector to appear */
|
|
|
+ waitForSelectorTimeout?: number;
|
|
|
};
|
|
|
```
|
|
|
|
|
|
-### Run your crawler
|
|
|
+#### Run your crawler
|
|
|
|
|
|
```sh
|
|
|
npm start
|
|
|
```
|
|
|
|
|
|
+### Alternative methods
|
|
|
+
|
|
|
+#### [Running in a container with Docker](./containerapp/README.md)
|
|
|
+
|
|
|
+To obtain the `output.json` with a containerized execution. Go into the `containerapp` directory. Modify the `config.ts` same as above, the `output.json`file should be generated in the data folder. Note : the `outputFileName` property in the `config.ts` file in containerapp folder is configured to work with the container.
|
|
|
+
|
|
|
+#### Running as a CLI
|
|
|
+
|
|
|
+<!-- TODO: Needs to be actually published -->
|
|
|
+
|
|
|
+##### Development
|
|
|
+
|
|
|
+To run the CLI locally while developing it:
|
|
|
+
|
|
|
+```sh
|
|
|
+npm run start:cli --url https://www.builder.io/c/docs/developers --match https://www.builder.io/c/docs/** --selector .docs-builder-container --maxPagesToCrawl 50 --outputFileName output.json
|
|
|
+```
|
|
|
+
|
|
|
### Upload your data to OpenAI
|
|
|
|
|
|
The crawl will generate a file called `output.json` at the root of this project. Upload that [to OpenAI](https://platform.openai.com/docs/assistants/overview) to create your custom assistant or custom GPT.
|
|
|
@@ -105,7 +135,6 @@ Use this option for UI access to your generated knowledge that you can easily sh
|
|
|
|
|
|
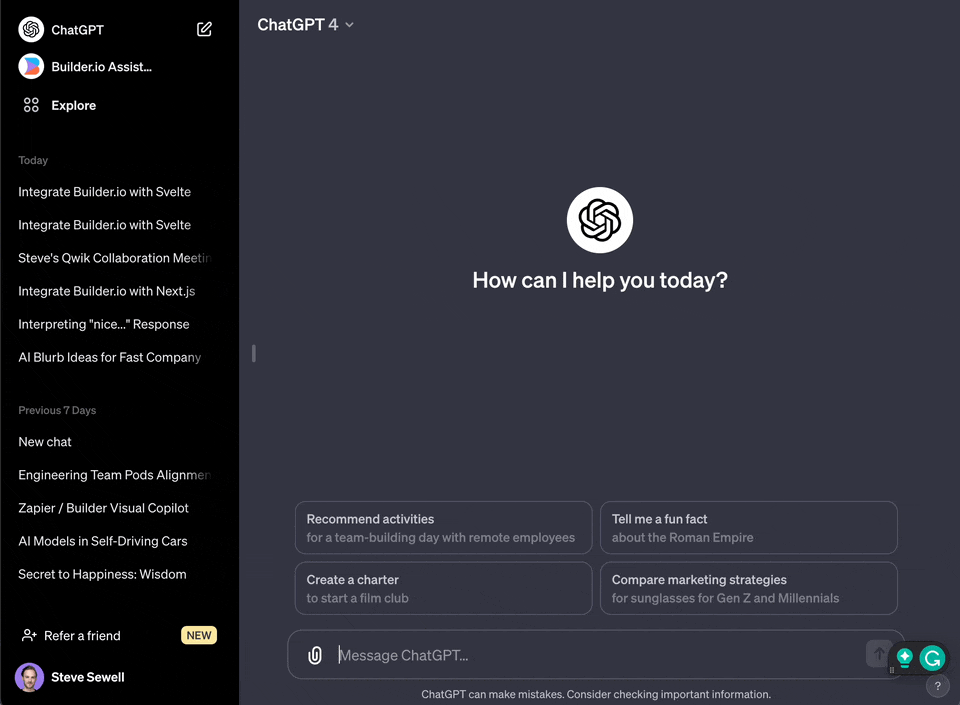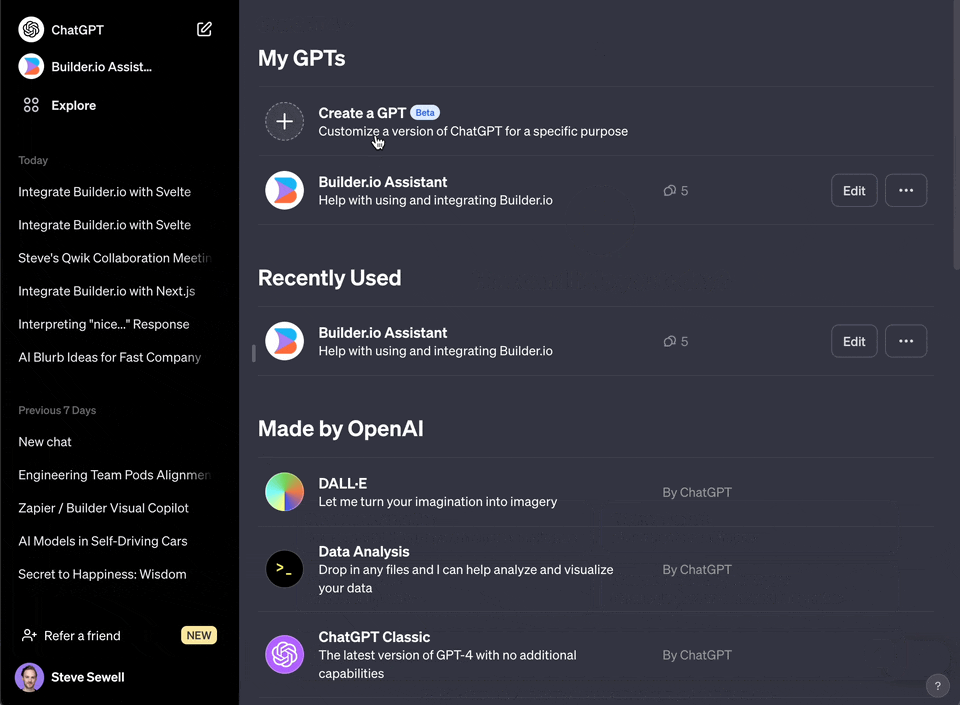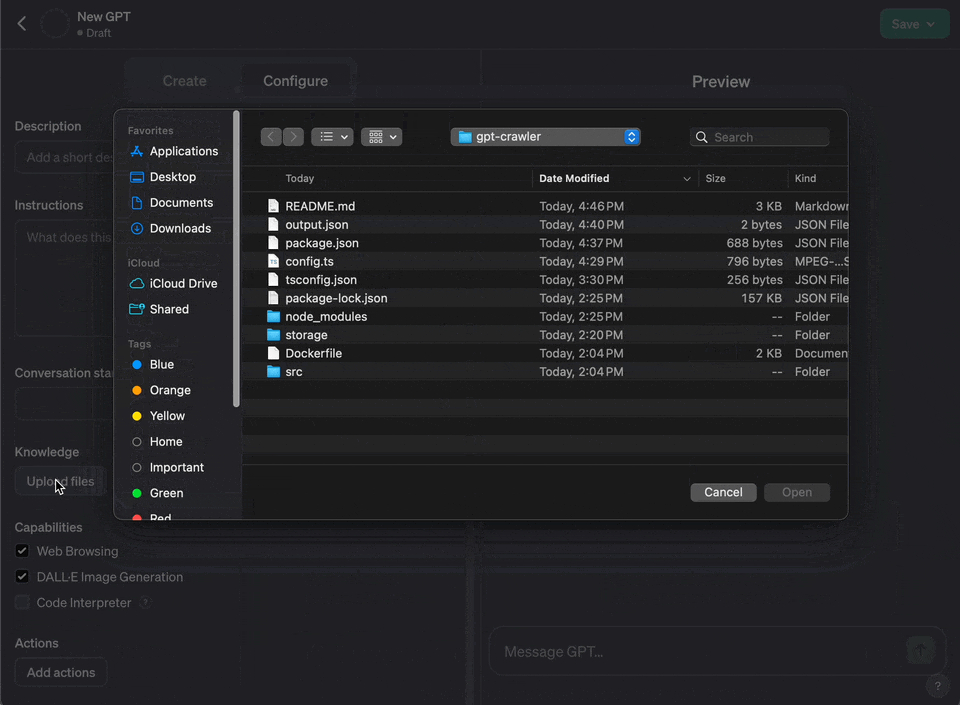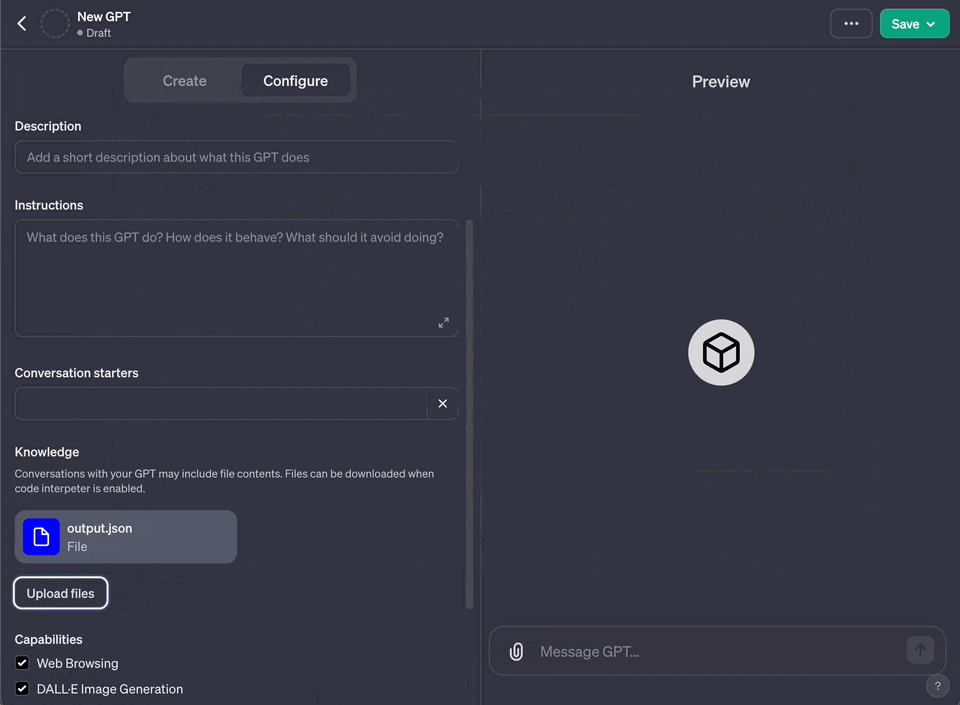
|
|
|
|
|
|
-
|
|
|
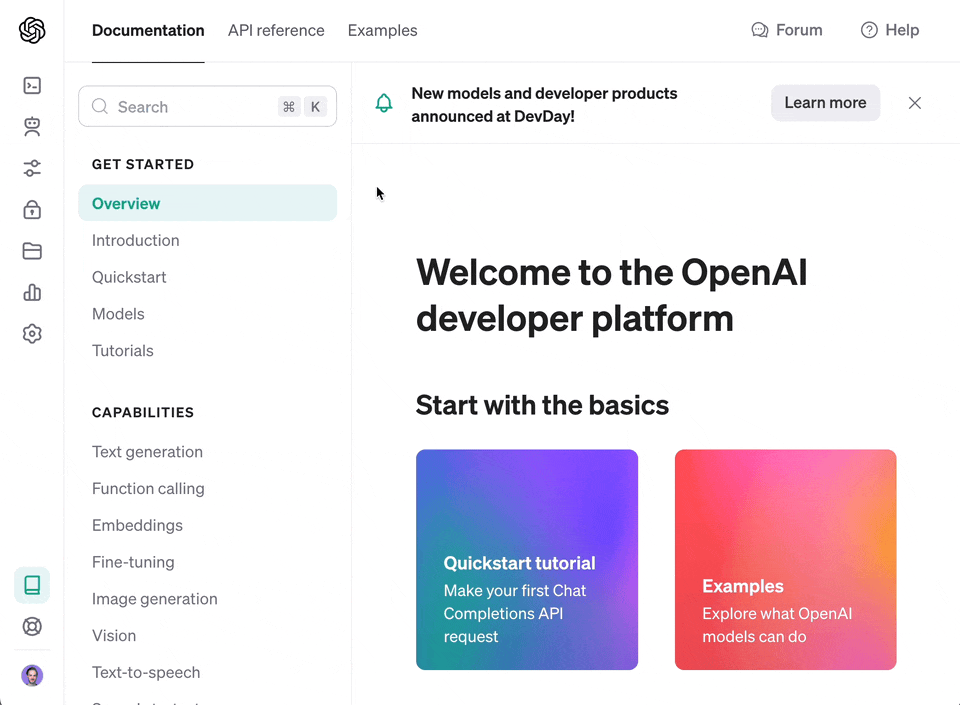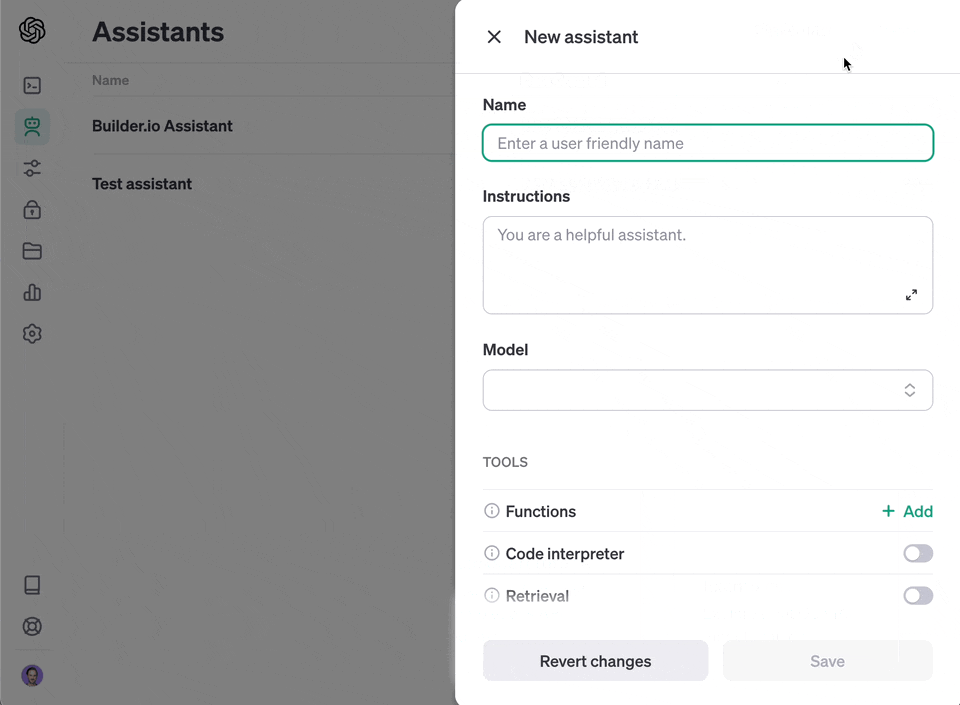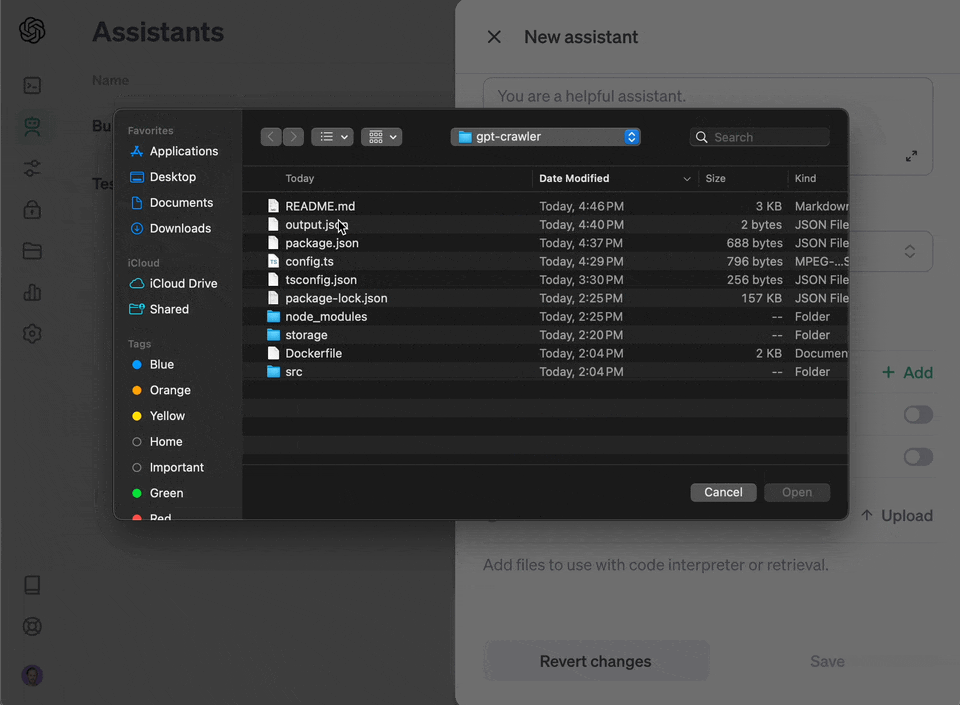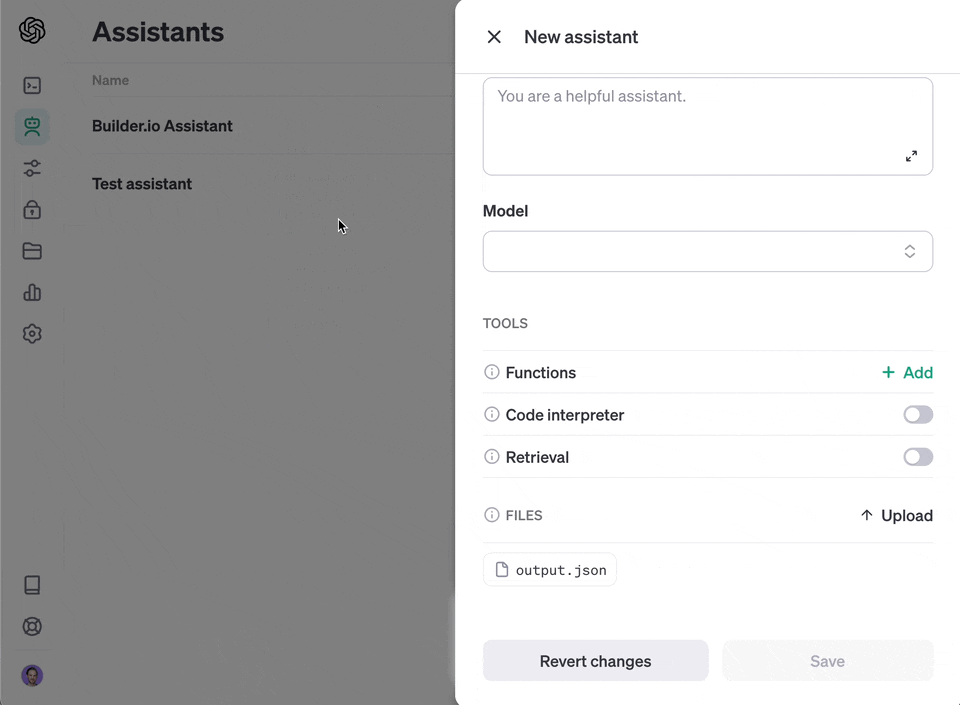
#### Create a custom assistant
|
|
|
|
|
|
Use this option for API access to your generated knowledge that you can integrate into your product.
|
|
|
@@ -116,10 +145,6 @@ Use this option for API access to your generated knowledge that you can integrat
|
|
|
|
|
|
|
|
|
|
|
|
-## (Alternate method) Running in a container with Docker
|
|
|
-To obtain the `output.json` with a containerized execution. Go into the `containerapp` directory. Modify the `config.ts` same as above, the `output.json`file should be generated in the data folder. Note : the `outputFileName` property in the `config.ts` file in containerapp folder is configured to work with the container.
|
|
|
-
|
|
|
-
|
|
|
## Contributing
|
|
|
|
|
|
Know how to make this project better? Send a PR!
|

 Steve Sewell
Steve Sewell