# MiniGrid (formerly gym-minigrid)
[](https://pre-commit.com/)
[](https://github.com/psf/black)
There are other gridworld Gymnasium environments out there, but this one is
designed to be particularly simple, lightweight and fast. The code has very few
dependencies, making it less likely to break or fail to install. It loads no
external sprites/textures, and it can run at up to 5000 FPS on a Core i7
laptop, which means you can run your experiments faster. A known-working RL
implementation can be found [in this repository](https://github.com/lcswillems/torch-rl).
Requirements:
- Python 3.7 to 3.10
- Gymnasium v0.26
- NumPy 1.18+
- Matplotlib (optional, only needed for display) - 3.0+
Please use this bibtex if you want to cite this repository in your publications:
```
@misc{minigrid,
author = {Chevalier-Boisvert, Maxime and Willems, Lucas and Pal, Suman},
title = {Minimalistic Gridworld Environment for Gymnasium},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Farama-Foundation/MiniGrid}},
}
```
List of publications & submissions using MiniGrid or BabyAI (please open a pull request to add missing entries):
- [History Compression via Language Models in Reinforcement Learning.](https://proceedings.mlr.press/v162/paischer22a.html) (Johannes Kepler University Linz, PMLR 2022)
- [Leveraging Approximate Symbolic Models for Reinforcement Learning via Skill Diversity](https://arxiv.org/abs/2202.02886) (Arizona State University, ICML 2022)
- [How to Stay Curious while avoiding Noisy TVs using Aleatoric Uncertainty Estimation](https://proceedings.mlr.press/v162/mavor-parker22a.html) (University College London, Boston University, ICML 2022)
- [In a Nutshell, the Human Asked for This: Latent Goals for Following Temporal Specifications](https://openreview.net/pdf?id=rUwm9wCjURV) (Imperial College London, ICLR 2022)
- [Interesting Object, Curious Agent: Learning Task-Agnostic Exploration](https://arxiv.org/abs/2111.13119) (Meta AI Research, NeurIPS 2021)
- [Safe Policy Optimization with Local Generalized Linear Function Approximations](https://arxiv.org/abs/2111.04894) (IBM Research, Tsinghua University, NeurIPS 2021)
- [A Consciousness-Inspired Planning Agent for Model-Based Reinforcement Learning](https://arxiv.org/abs/2106.02097) (Mila, McGill University, NeurIPS 2021)
- [SPOTTER: Extending Symbolic Planning Operators through Targeted Reinforcement Learning](http://www.ifaamas.org/Proceedings/aamas2021/pdfs/p1118.pdf) (Tufts University, SIFT, AAMAS 2021)
- [Grid-to-Graph: Flexible Spatial Relational Inductive Biases for Reinforcement Learning](https://arxiv.org/abs/2102.04220) (UCL, AAMAS 2021)
- [Rank the Episodes: A Simple Approach for Exploration in Procedurally-Generated Environments](https://openreview.net/forum?id=MtEE0CktZht) (Texas A&M University, Kuai Inc., ICLR 2021)
- [Adversarially Guided Actor-Critic](https://openreview.net/forum?id=_mQp5cr_iNy) (INRIA, Google Brain, ICLR 2021)
- [Information-theoretic Task Selection for Meta-Reinforcement Learning](https://papers.nips.cc/paper/2020/file/ec3183a7f107d1b8dbb90cb3c01ea7d5-Paper.pdf) (University of Leeds, NeurIPS 2020)
- [BeBold: Exploration Beyond the Boundary of Explored Regions](https://arxiv.org/pdf/2012.08621.pdf) (UCB, December 2020)
- [Approximate Information State for Approximate Planning and Reinforcement Learning in Partially Observed Systems](https://arxiv.org/abs/2010.08843) (McGill, October 2020)
- [Prioritized Level Replay](https://arxiv.org/pdf/2010.03934.pdf) (FAIR, October 2020)
- [AllenAct: A Framework for Embodied AI Research](https://arxiv.org/pdf/2008.12760.pdf) (Allen Institute for AI, August 2020)
- [Learning with AMIGO: Adversarially Motivated Intrinsic Goals](https://arxiv.org/pdf/2006.12122.pdf) (MIT, FAIR, ICLR 2021)
- [RIDE: Rewarding Impact-Driven Exploration for Procedurally-Generated Environments](https://openreview.net/forum?id=rkg-TJBFPB) (FAIR, ICLR 2020)
- [Learning to Request Guidance in Emergent Communication](https://arxiv.org/pdf/1912.05525.pdf) (University of Amsterdam, Dec 2019)
- [Working Memory Graphs](https://arxiv.org/abs/1911.07141) (MSR, Nov 2019)
- [Fast Task-Adaptation for Tasks Labeled Using Natural Language in Reinforcement Learning](https://arxiv.org/pdf/1910.04040.pdf) (Oct 2019, University of Antwerp)
- [Generalization in Reinforcement Learning with Selective Noise Injection and Information Bottleneck](https://arxiv.org/abs/1910.12911) (MSR, NeurIPS, Oct 2019)
- [Recurrent Independent Mechanisms](https://arxiv.org/pdf/1909.10893.pdf) (Mila, Sept 2019)
- [Learning Effective Subgoals with Multi-Task Hierarchical Reinforcement Learning](http://surl.tirl.info/proceedings/SURL-2019_paper_10.pdf) (Tsinghua University, August 2019)
- [Mastering emergent language: learning to guide in simulated navigation](https://arxiv.org/abs/1908.05135) (University of Amsterdam, Aug 2019)
- [Transfer Learning by Modeling a Distribution over Policies](https://arxiv.org/abs/1906.03574) (Mila, June 2019)
- [Reinforcement Learning with Competitive Ensembles of Information-Constrained Primitives](https://arxiv.org/abs/1906.10667) (Mila, June 2019)
- [Learning distant cause and effect using only local and immediate credit assignment](https://arxiv.org/abs/1905.11589) (Incubator 491, May 2019)
- [Practical Open-Loop Optimistic Planning](https://arxiv.org/abs/1904.04700) (INRIA, April 2019)
- [Learning World Graphs to Accelerate Hierarchical Reinforcement Learning](https://arxiv.org/abs/1907.00664) (Salesforce Research, 2019)
- [Variational State Encoding as Intrinsic Motivation in Reinforcement Learning](https://mila.quebec/wp-content/uploads/2019/05/WebPage.pdf) (Mila, TARL 2019)
- [Unsupervised Discovery of Decision States Through Intrinsic Control](https://tarl2019.github.io/assets/papers/modhe2019unsupervised.pdf) (Georgia Tech, TARL 2019)
- [Modeling the Long Term Future in Model-Based Reinforcement Learning](https://openreview.net/forum?id=SkgQBn0cF7) (Mila, ICLR 2019)
- [Unifying Ensemble Methods for Q-learning via Social Choice Theory](https://arxiv.org/pdf/1902.10646.pdf) (Max Planck Institute, Feb 2019)
- [Planning Beyond The Sensing Horizon Using a Learned Context](https://personalrobotics.cs.washington.edu/workshops/mlmp2018/assets/docs/18_CameraReadySubmission.pdf) (MLMP@IROS, 2018)
- [Guiding Policies with Language via Meta-Learning](https://arxiv.org/abs/1811.07882) (UC Berkeley, Nov 2018)
- [On the Complexity of Exploration in Goal-Driven Navigation](https://arxiv.org/abs/1811.06889) (CMU, NeurIPS, Nov 2018)
- [Transfer and Exploration via the Information Bottleneck](https://openreview.net/forum?id=rJg8yhAqKm) (Mila, Nov 2018)
- [Creating safer reward functions for reinforcement learning agents in the gridworld](https://gupea.ub.gu.se/bitstream/2077/62445/1/gupea_2077_62445_1.pdf) (University of Gothenburg, 2018)
- [BabyAI: First Steps Towards Grounded Language Learning With a Human In the Loop](https://arxiv.org/abs/1810.08272) (Mila, ICLR, Oct 2018)
This environment has been built as part of work done at [Mila](https://mila.quebec). The Dynamic obstacles environment has been added as part of work done at [IAS in TU Darmstadt](https://www.ias.informatik.tu-darmstadt.de/) and the University of Genoa for mobile robot navigation with dynamic obstacles.
## Installation
There is now a [pip package](https://pypi.org/project/minigrid/) available, which is updated periodically:
```
pip install minigrid
```
Alternatively, to get the latest version of MiniGrid, you can clone this repository and install the dependencies with `pip3`:
```
git clone https://github.com/Farama-Foundation/MiniGrid
cd MiniGrid
pip install -e .
```
## Basic Usage
There is a UI application which allows you to manually control the agent with the arrow keys:
```
./minigrid/examples/manual_control.py
```
The environment being run can be selected with the `--env` option, eg:
```
./minigrid/examples/manual_control.py --env MiniGrid-Empty-8x8-v0
```
## Reinforcement Learning
If you want to train an agent with reinforcement learning, I recommend using the code found in the [torch-rl](https://github.com/lcswillems/torch-rl) repository.
This code has been tested and is known to work with this environment. The default hyper-parameters are also known to converge.
A sample training command is:
```
cd torch-rl
python3 -m scripts.train --env MiniGrid-Empty-8x8-v0 --algo ppo
```
## Wrappers
MiniGrid is built to support tasks involving natural language and sparse rewards.
The observations are dictionaries, with an 'image' field, partially observable
view of the environment, a 'mission' field which is a textual string
describing the objective the agent should reach to get a reward, and a 'direction'
field which can be used as an optional compass. Using dictionaries makes it
easy for you to add additional information to observations
if you need to, without having to encode everything into a single tensor.
There are a variety of wrappers to change the observation format available in [minigrid/wrappers.py](/minigrid/wrappers.py).
If your RL code expects one single tensor for observations, take a look at `FlatObsWrapper`.
There is also an `ImgObsWrapper` that gets rid of the 'mission' field in observations, leaving only the image field tensor.
Please note that the default observation format is a partially observable view of the environment using a
compact and efficient encoding, with 3 input values per visible grid cell, 7x7x3 values total.
These values are **not pixels**. If you want to obtain an array of RGB pixels as observations instead,
use the `RGBImgPartialObsWrapper`. You can use it as follows:
```python
import gymnasium as gym
from minigrid.wrappers import RGBImgPartialObsWrapper, ImgObsWrapper
env = gym.make('MiniGrid-Empty-8x8-v0')
env = RGBImgPartialObsWrapper(env) # Get pixel observations
env = ImgObsWrapper(env) # Get rid of the 'mission' field
obs, _ = env.reset() # This now produces an RGB tensor only
```
## Design
Structure of the world:
- The world is an NxM grid of tiles
- Each tile in the grid world contains zero or one object
- Cells that do not contain an object have the value `None`
- Each object has an associated discrete color (string)
- Each object has an associated type (string)
- Provided object types are: wall, floor, lava, door, key, ball, box and goal
- The agent can pick up and carry exactly one object (eg: ball or key)
- To open a locked door, the agent has to be carrying a key matching the door's color
Actions in the basic environment:
- Turn left
- Turn right
- Move forward
- Pick up an object
- Drop the object being carried
- Toggle (open doors, interact with objects)
- Done (task completed, optional)
Default tile/observation encoding:
- Each tile is encoded as a 3 dimensional tuple: `(OBJECT_IDX, COLOR_IDX, STATE)`
- `OBJECT_TO_IDX` and `COLOR_TO_IDX` mapping can be found in [minigrid/minigrid.py](minigrid/minigrid.py)
- `STATE` refers to the door state with 0=open, 1=closed and 2=locked
By default, sparse rewards are given for reaching a green goal tile. A
reward of 1 is given for success, and zero for failure. There is also an
environment-specific time step limit for completing the task.
You can define your own reward function by creating a class derived
from `MiniGridEnv`. Extending the environment with new object types or new actions
should be very easy. If you wish to do this, you should take a look at the
[minigrid/minigrid.py](minigrid/minigrid.py) source file.
## Included Environments
The environments listed below are implemented in the [minigrid/envs](/minigrid/envs) directory.
Each environment provides one or more configurations registered with OpenAI gym. Each environment
is also programmatically tunable in terms of size/complexity, which is useful for curriculum learning
or to fine-tune difficulty.
### Empty environment
This environment is an empty room, and the goal of the agent is to reach the
green goal square, which provides a sparse reward. A small penalty is
subtracted for the number of steps to reach the goal. This environment is
useful, with small rooms, to validate that your RL algorithm works correctly,
and with large rooms to experiment with sparse rewards and exploration.
The random variants of the environment have the agent starting at a random
position for each episode, while the regular variants have the agent always
starting in the corner opposite to the goal.

Registered configurations:
- `MiniGrid-Empty-5x5-v0`
- `MiniGrid-Empty-Random-5x5-v0`
- `MiniGrid-Empty-6x6-v0`
- `MiniGrid-Empty-Random-6x6-v0`
- `MiniGrid-Empty-8x8-v0`
- `MiniGrid-Empty-16x16-v0`
### Four rooms environment
Classic four room reinforcement learning environment. The agent must navigate
in a maze composed of four rooms interconnected by 4 gaps in the walls. To
obtain a reward, the agent must reach the green goal square. Both the agent
and the goal square are randomly placed in any of the four rooms.

Registered configurations:
- `MiniGrid-FourRooms-v0`
### Door & key environment
This environment has a key that the agent must pick up in order to unlock
a goal and then get to the green goal square. This environment is difficult,
because of the sparse reward, to solve using classical RL algorithms. It is
useful to experiment with curiosity or curriculum learning.

Registered configurations:
- `MiniGrid-DoorKey-5x5-v0`
- `MiniGrid-DoorKey-6x6-v0`
- `MiniGrid-DoorKey-8x8-v0`
- `MiniGrid-DoorKey-16x16-v0`
### Multi-room environment
This environment has a series of connected rooms with doors that must be
opened in order to get to the next room. The final room has the green goal
square the agent must get to. This environment is extremely difficult to
solve using RL alone. However, by gradually increasing the number of
rooms and building a curriculum, the environment can be solved.

Registered configurations:
- `MiniGrid-MultiRoom-N2-S4-v0` (two small rooms)
- `MiniGrid-MultiRoom-N4-S5-v0` (four rooms)
- `MiniGrid-MultiRoom-N6-v0` (six rooms)
### Fetch environment
This environment has multiple objects of assorted types and colors. The
agent receives a textual string as part of its observation telling it
which object to pick up. Picking up the wrong object terminates the
episode with zero reward.

Registered configurations:
- `MiniGrid-Fetch-5x5-N2-v0`
- `MiniGrid-Fetch-6x6-N2-v0`
- `MiniGrid-Fetch-8x8-N3-v0`
### Go-to-door environment
This environment is a room with four doors, one on each wall. The agent
receives a textual (mission) string as input, telling it which door to go to,
(eg: "go to the red door"). It receives a positive reward for performing the
`done` action next to the correct door, as indicated in the mission string.

Registered configurations:
- `MiniGrid-GoToDoor-5x5-v0`
- `MiniGrid-GoToDoor-6x6-v0`
- `MiniGrid-GoToDoor-8x8-v0`
### Put-near environment
The agent is instructed through a textual string to pick up an object and
place it next to another object. This environment is easy to solve with two
objects, but difficult to solve with more, as it involves both textual
understanding and spatial reasoning involving multiple objects.
Registered configurations:
- `MiniGrid-PutNear-6x6-N2-v0`
- `MiniGrid-PutNear-8x8-N3-v0`
### Red and blue doors environment
The agent is randomly placed within a room with one red and one blue door
facing opposite directions. The agent has to open the red door and then open
the blue door, in that order. Note that, surprisingly, this environment is
solvable without memory.
Registered configurations:
- `MiniGrid-RedBlueDoors-6x6-v0`
- `MiniGrid-RedBlueDoors-8x8-v0`
### Memory environment
This environment is a memory test. The agent starts in a small room
where it sees an object. It then has to go through a narrow hallway
which ends in a split. At each end of the split there is an object,
one of which is the same as the object in the starting room. The
agent has to remember the initial object, and go to the matching
object at split.
Registered configurations:
- `MiniGrid-MemoryS17Random-v0`
- `MiniGrid-MemoryS13Random-v0`
- `MiniGrid-MemoryS13-v0`
- `MiniGrid-MemoryS11-v0`
### Locked room environment
The environment has six rooms, one of which is locked. The agent receives
a textual mission string as input, telling it which room to go to in order
to get the key that opens the locked room. It then has to go into the locked
room in order to reach the final goal. This environment is extremely difficult
to solve with vanilla reinforcement learning alone.
Registered configurations:
- `MiniGrid-LockedRoom-v0`
### Key corridor environment
This environment is similar to the locked room environment, but there are
multiple registered environment configurations of increasing size,
making it easier to use curriculum learning to train an agent to solve it.
The agent has to pick up an object which is behind a locked door. The key is
hidden in another room, and the agent has to explore the environment to find
it. The mission string does not give the agent any clues as to where the
key is placed. This environment can be solved without relying on language.






Registered configurations:
- `MiniGrid-KeyCorridorS3R1-v0`
- `MiniGrid-KeyCorridorS3R2-v0`
- `MiniGrid-KeyCorridorS3R3-v0`
- `MiniGrid-KeyCorridorS4R3-v0`
- `MiniGrid-KeyCorridorS5R3-v0`
- `MiniGrid-KeyCorridorS6R3-v0`
### Unlock environment
The agent has to open a locked door. This environment can be solved without
relying on language.

Registered configurations:
- `MiniGrid-Unlock-v0`
### Unlock pickup environment
The agent has to pick up a box which is placed in another room, behind a
locked door. This environment can be solved without relying on language.

Registered configurations:
- `MiniGrid-UnlockPickup-v0`
### Blocked unlock pickup environment
The agent has to pick up a box which is placed in another room, behind a
locked door. The door is also blocked by a ball which the agent has to move
before it can unlock the door. Hence, the agent has to learn to move the ball,
pick up the key, open the door and pick up the object in the other room.
This environment can be solved without relying on language.

Registered configurations:
- `MiniGrid-BlockedUnlockPickup-v0`
## Obstructed maze environment
The agent has to pick up a box which is placed in a corner of a 3x3 maze.
The doors are locked, the keys are hidden in boxes and doors are obstructed
by balls. This environment can be solved without relying on language.









Registered configurations:
- `MiniGrid-ObstructedMaze-1Dl-v0`
- `MiniGrid-ObstructedMaze-1Dlh-v0`
- `MiniGrid-ObstructedMaze-1Dlhb-v0`
- `MiniGrid-ObstructedMaze-2Dl-v0`
- `MiniGrid-ObstructedMaze-2Dlh-v0`
- `MiniGrid-ObstructedMaze-2Dlhb-v0`
- `MiniGrid-ObstructedMaze-1Q-v0`
- `MiniGrid-ObstructedMaze-2Q-v0`
- `MiniGrid-ObstructedMaze-Full-v0`
## Distributional shift environment
This environment is based on one of the DeepMind [AI safety gridworlds](https://github.com/deepmind/ai-safety-gridworlds).
The agent starts in the top-left corner and must reach the goal which is in the top-right corner, but has to avoid stepping
into lava on its way. The aim of this environment is to test an agent's ability to generalize. There are two slightly
different variants of the environment, so that the agent can be trained on one variant and tested on the other.


Registered configurations:
- `MiniGrid-DistShift1-v0`
- `MiniGrid-DistShift2-v0`
## Lava gap environment
The agent has to reach the green goal square at the opposite corner of the room,
and must pass through a narrow gap in a vertical strip of deadly lava. Touching
the lava terminate the episode with a zero reward. This environment is useful
for studying safety and safe exploration.
Registered configurations:
- `MiniGrid-LavaGapS5-v0`
- `MiniGrid-LavaGapS6-v0`
- `MiniGrid-LavaGapS7-v0`

## Lava crossing environment
The agent has to reach the green goal square on the other corner of the room
while avoiding rivers of deadly lava which terminate the episode in failure.
Each lava stream runs across the room either horizontally or vertically, and
has a single crossing point which can be safely used; Luckily, a path to the
goal is guaranteed to exist. This environment is useful for studying safety and
safe exploration.




Registered configurations:
- `MiniGrid-LavaCrossingS9N1-v0`
- `MiniGrid-LavaCrossingS9N2-v0`
- `MiniGrid-LavaCrossingS9N3-v0`
- `MiniGrid-LavaCrossingS11N5-v0`
## Simple crossing environment
Similar to the `LavaCrossing` environment, the agent has to reach the green
goal square on the other corner of the room, however lava is replaced by
walls. This MDP is therefore much easier and maybe useful for quickly
testing your algorithms.




Registered configurations:
- `MiniGrid-SimpleCrossingS9N1-v0`
- `MiniGrid-SimpleCrossingS9N2-v0`
- `MiniGrid-SimpleCrossingS9N3-v0`
- `MiniGrid-SimpleCrossingS11N5-v0`
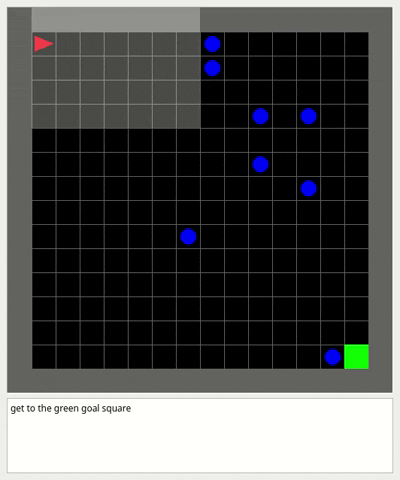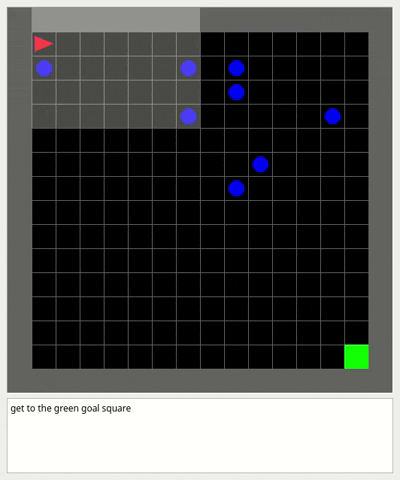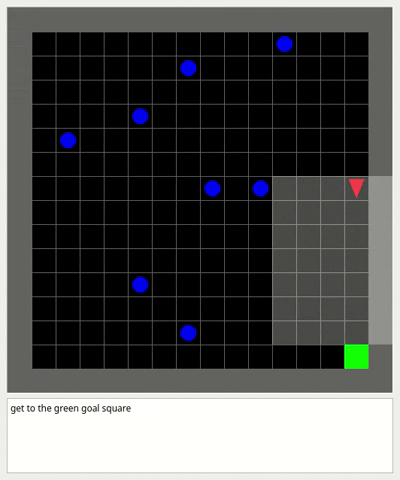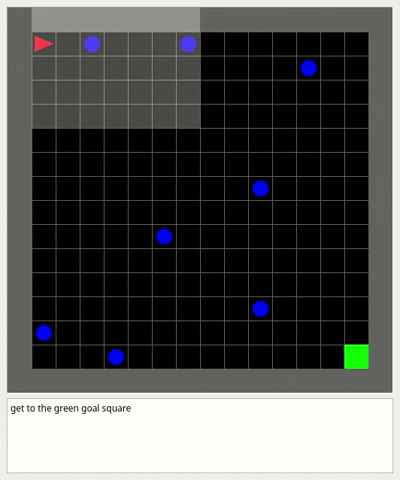
### Dynamic obstacles environment
This environment is an empty room with moving obstacles.
The goal of the agent is to reach the green goal square without colliding with any obstacle.
A large penalty is subtracted if the agent collides with an obstacle and the episode finishes.
This environment is useful to test Dynamic Obstacle Avoidance for mobile robots with Reinforcement Learning in Partial Observability.
Registered configurations:
- `MiniGrid-Dynamic-Obstacles-5x5-v0`
- `MiniGrid-Dynamic-Obstacles-Random-5x5-v0`
- `MiniGrid-Dynamic-Obstacles-6x6-v0`
- `MiniGrid-Dynamic-Obstacles-Random-6x6-v0`
- `MiniGrid-Dynamic-Obstacles-8x8-v0`
- `MiniGrid-Dynamic-Obstacles-16x16-v0`