|
|
@@ -8,6 +8,123 @@ This recipe demonstrates how to fine-tune Llama 3.2 11B Vision model on a synthe
|
|
|
- Compare trade-offs between LoRA and Full Parameter Fine-tuning on both task-specific and general benchmarks
|
|
|
- Provide guidance on data preparation, training configuration, and evaluation methodologies
|
|
|
|
|
|
+## Results
|
|
|
+
|
|
|
+### Task-Specific Performance (W2 Extraction)
|
|
|
+
|
|
|
+<table border="1" cellpadding="5" cellspacing="0">
|
|
|
+<tr style="background-color: #f0f0f0;">
|
|
|
+<th>Benchmark</th>
|
|
|
+<th>11B bf16 (Baseline)</th>
|
|
|
+<th>LoRA</th>
|
|
|
+<th>FPFT</th>
|
|
|
+<th>FPFT int4</th>
|
|
|
+
|
|
|
+</tr>
|
|
|
+<tr>
|
|
|
+<td><strong>W2 extraction acc</strong></td>
|
|
|
+<td>58</td>
|
|
|
+<td><strong>72</strong></td>
|
|
|
+<td><strong>97</strong></td>
|
|
|
+<td><strong>96</strong></td>
|
|
|
+
|
|
|
+</tr>
|
|
|
+</table>
|
|
|
+
|
|
|
+### General Benchmark Performance (llama-verifications)
|
|
|
+
|
|
|
+<table border="1" cellpadding="5" cellspacing="0">
|
|
|
+<tr style="background-color: #f0f0f0;">
|
|
|
+<th>Benchmark</th>
|
|
|
+<th>11B bf16 (Baseline)</th>
|
|
|
+<th>LoRA</th>
|
|
|
+<th>FPFT</th>
|
|
|
+<th>FPFT int4</th>
|
|
|
+
|
|
|
+</tr>
|
|
|
+<tr>
|
|
|
+<td>bfclv3</td>
|
|
|
+<td>39.87</td>
|
|
|
+<td>39.87</td>
|
|
|
+<td>39.85</td>
|
|
|
+<td>34.67</td>
|
|
|
+
|
|
|
+</tr>
|
|
|
+<tr>
|
|
|
+<td>docvqa</td>
|
|
|
+<td>86.88</td>
|
|
|
+<td>85.08</td>
|
|
|
+<td>86.3</td>
|
|
|
+<td>78.95</td>
|
|
|
+
|
|
|
+</tr>
|
|
|
+<tr>
|
|
|
+<td>gpqa-cot-diamond</td>
|
|
|
+<td>27.78</td>
|
|
|
+<td>27.78</td>
|
|
|
+<td>26</td>
|
|
|
+<td>28</td>
|
|
|
+
|
|
|
+</tr>
|
|
|
+<tr>
|
|
|
+<td>ifeval</td>
|
|
|
+<td>74.79</td>
|
|
|
+<td>74.78</td>
|
|
|
+<td>74.54</td>
|
|
|
+<td>74.42</td>
|
|
|
+
|
|
|
+</tr>
|
|
|
+<tr>
|
|
|
+<td>mmlu-pro-cot</td>
|
|
|
+<td>48.43</td>
|
|
|
+<td>48.13</td>
|
|
|
+<td>48.33</td>
|
|
|
+<td>46.14</td>
|
|
|
+
|
|
|
+</tr>
|
|
|
+</table>
|
|
|
+
|
|
|
+### LM Evaluation Harness Results
|
|
|
+
|
|
|
+<table border="1" cellpadding="5" cellspacing="0">
|
|
|
+<tr style="background-color: #f0f0f0;">
|
|
|
+<th>Benchmark</th>
|
|
|
+<th>11B bf16 (Baseline)</th>
|
|
|
+<th>FPFT</th>
|
|
|
+
|
|
|
+</tr>
|
|
|
+<tr>
|
|
|
+<td>gsm8k_cot_llama_strict</td>
|
|
|
+<td>85.29</td>
|
|
|
+<td>85.29</td>
|
|
|
+
|
|
|
+</tr>
|
|
|
+<tr>
|
|
|
+<td>gsm8k_cot_llama_flexible</td>
|
|
|
+<td>85.44</td>
|
|
|
+<td>85.44</td>
|
|
|
+
|
|
|
+</tr>
|
|
|
+<tr>
|
|
|
+<td>chartqa llama exact</td>
|
|
|
+<td>0</td>
|
|
|
+<td>0</td>
|
|
|
+
|
|
|
+</tr>
|
|
|
+<tr>
|
|
|
+<td>chartqa llama relaxed</td>
|
|
|
+<td>34.16</td>
|
|
|
+<td>35.58</td>
|
|
|
+
|
|
|
+</tr>
|
|
|
+<tr>
|
|
|
+<td>chartqa llama anywhere</td>
|
|
|
+<td>43.53</td>
|
|
|
+<td>46.52</td>
|
|
|
+
|
|
|
+</tr>
|
|
|
+</table>
|
|
|
+
|
|
|
## Prerequisites
|
|
|
- CUDA-compatible GPU with at least 40GB VRAM
|
|
|
- HuggingFace account with access to Llama models
|
|
|
@@ -173,9 +290,9 @@ pip install llama-verifications
|
|
|
Run benchmark evaluation:
|
|
|
```bash
|
|
|
uvx llama-verifications run-benchmarks \
|
|
|
- --benchmarks mmlu-pro-cot,gpqa,gpqa-cot-diamond \
|
|
|
- --provider http://localhost:8003/v1 \
|
|
|
- --model <model_path> \
|
|
|
+ --benchmarks mmlu-pro-cot,gpqa-cot-diamond,bfclv3,docvqa \
|
|
|
+ --provider http://localhost:8001/v1 \
|
|
|
+ --model <model_served_name> \
|
|
|
--continue-on-failure \
|
|
|
--max-parallel-generations 100
|
|
|
```
|
|
|
@@ -205,134 +322,7 @@ CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch -m lm_eval --model hf-multimodal
|
|
|
|
|
|
```
|
|
|
|
|
|
-## Results
|
|
|
-
|
|
|
-### Task-Specific Performance (W2 Extraction)
|
|
|
-
|
|
|
-<table border="1" cellpadding="5" cellspacing="0">
|
|
|
-<tr style="background-color: #f0f0f0;">
|
|
|
-<th>Benchmark</th>
|
|
|
-<th>11B bf16 (Baseline)</th>
|
|
|
-<th>LoRA</th>
|
|
|
-<th>FPFT int4</th>
|
|
|
-<th>FPFT</th>
|
|
|
-<th>90B bf16</th>
|
|
|
-</tr>
|
|
|
-<tr>
|
|
|
-<td><strong>W2 extraction acc</strong></td>
|
|
|
-<td>58</td>
|
|
|
-<td><strong>72</strong></td>
|
|
|
-<td><strong>96</strong></td>
|
|
|
-<td><strong>97</strong></td>
|
|
|
-<td>N/A</td>
|
|
|
-</tr>
|
|
|
-</table>
|
|
|
|
|
|
-### General Benchmark Performance (llama-verifications)
|
|
|
-
|
|
|
-<table border="1" cellpadding="5" cellspacing="0">
|
|
|
-<tr style="background-color: #f0f0f0;">
|
|
|
-<th>Benchmark</th>
|
|
|
-<th>11B bf16 (Baseline)</th>
|
|
|
-<th>LoRA</th>
|
|
|
-<th>FPFT int4</th>
|
|
|
-<th>FPFT</th>
|
|
|
-<th>90B bf16</th>
|
|
|
-</tr>
|
|
|
-<tr>
|
|
|
-<td>bfclv3</td>
|
|
|
-<td>39.87</td>
|
|
|
-<td>39.87</td>
|
|
|
-<td>34.67</td>
|
|
|
-<td>39.85</td>
|
|
|
-<td>N/A</td>
|
|
|
-</tr>
|
|
|
-<tr>
|
|
|
-<td>docvqa</td>
|
|
|
-<td>86.88</td>
|
|
|
-<td>85.08</td>
|
|
|
-<td>78.95</td>
|
|
|
-<td>86.3</td>
|
|
|
-<td>N/A</td>
|
|
|
-</tr>
|
|
|
-<tr>
|
|
|
-<td>gpqa-cot-diamond</td>
|
|
|
-<td>27.78</td>
|
|
|
-<td>27.78</td>
|
|
|
-<td>28</td>
|
|
|
-<td>26</td>
|
|
|
-<td>N/A</td>
|
|
|
-</tr>
|
|
|
-<tr>
|
|
|
-<td>ifeval</td>
|
|
|
-<td>74.79</td>
|
|
|
-<td>74.78</td>
|
|
|
-<td>74.42</td>
|
|
|
-<td>74.54</td>
|
|
|
-<td>N/A</td>
|
|
|
-</tr>
|
|
|
-<tr>
|
|
|
-<td>mmlu-pro-cot</td>
|
|
|
-<td>48.43</td>
|
|
|
-<td>48.13</td>
|
|
|
-<td>46.14</td>
|
|
|
-<td>48.33</td>
|
|
|
-<td>N/A</td>
|
|
|
-</tr>
|
|
|
-</table>
|
|
|
-
|
|
|
-### LM Evaluation Harness Results
|
|
|
-
|
|
|
-<table border="1" cellpadding="5" cellspacing="0">
|
|
|
-<tr style="background-color: #f0f0f0;">
|
|
|
-<th>Benchmark</th>
|
|
|
-<th>11B bf16 (Baseline)</th>
|
|
|
-<th>LoRA</th>
|
|
|
-<th>FPFT int4</th>
|
|
|
-<th>FPFT</th>
|
|
|
-<th>90B bf16</th>
|
|
|
-</tr>
|
|
|
-<tr>
|
|
|
-<td>gsm8k_cot_llama_strict</td>
|
|
|
-<td>85.29</td>
|
|
|
-<td>N/A</td>
|
|
|
-<td>N/A</td>
|
|
|
-<td>85.29</td>
|
|
|
-<td>N/A</td>
|
|
|
-</tr>
|
|
|
-<tr>
|
|
|
-<td>gsm8k_cot_llama_flexible</td>
|
|
|
-<td>85.44</td>
|
|
|
-<td>N/A</td>
|
|
|
-<td>N/A</td>
|
|
|
-<td>85.44</td>
|
|
|
-<td>N/A</td>
|
|
|
-</tr>
|
|
|
-<tr>
|
|
|
-<td>chartqa_llama_90_exact</td>
|
|
|
-<td>0</td>
|
|
|
-<td>N/A</td>
|
|
|
-<td>N/A</td>
|
|
|
-<td>0</td>
|
|
|
-<td>3.8</td>
|
|
|
-</tr>
|
|
|
-<tr>
|
|
|
-<td>chartqa_llama_90_relaxed</td>
|
|
|
-<td>34.16</td>
|
|
|
-<td>N/A</td>
|
|
|
-<td>N/A</td>
|
|
|
-<td>35.58</td>
|
|
|
-<td>44.12</td>
|
|
|
-</tr>
|
|
|
-<tr>
|
|
|
-<td>chartqa_llama_90_anywhere</td>
|
|
|
-<td>43.53</td>
|
|
|
-<td>N/A</td>
|
|
|
-<td>N/A</td>
|
|
|
-<td>46.52</td>
|
|
|
-<td>47.44</td>
|
|
|
-</tr>
|
|
|
-</table>
|
|
|
|
|
|
## Key Findings
|
|
|
|
|
|
@@ -351,7 +341,16 @@ CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch -m lm_eval --model hf-multimodal
|
|
|
- **Full Parameter fine-tuning** requires more resources but achieves better task-specific performance
|
|
|
|
|
|
## Performance Graphs
|
|
|
-*Note: Training loss curves and memory consumption graphs will be added here based on WandB logging data.*
|
|
|
+
|
|
|
+### Performance
|
|
|
+
|
|
|
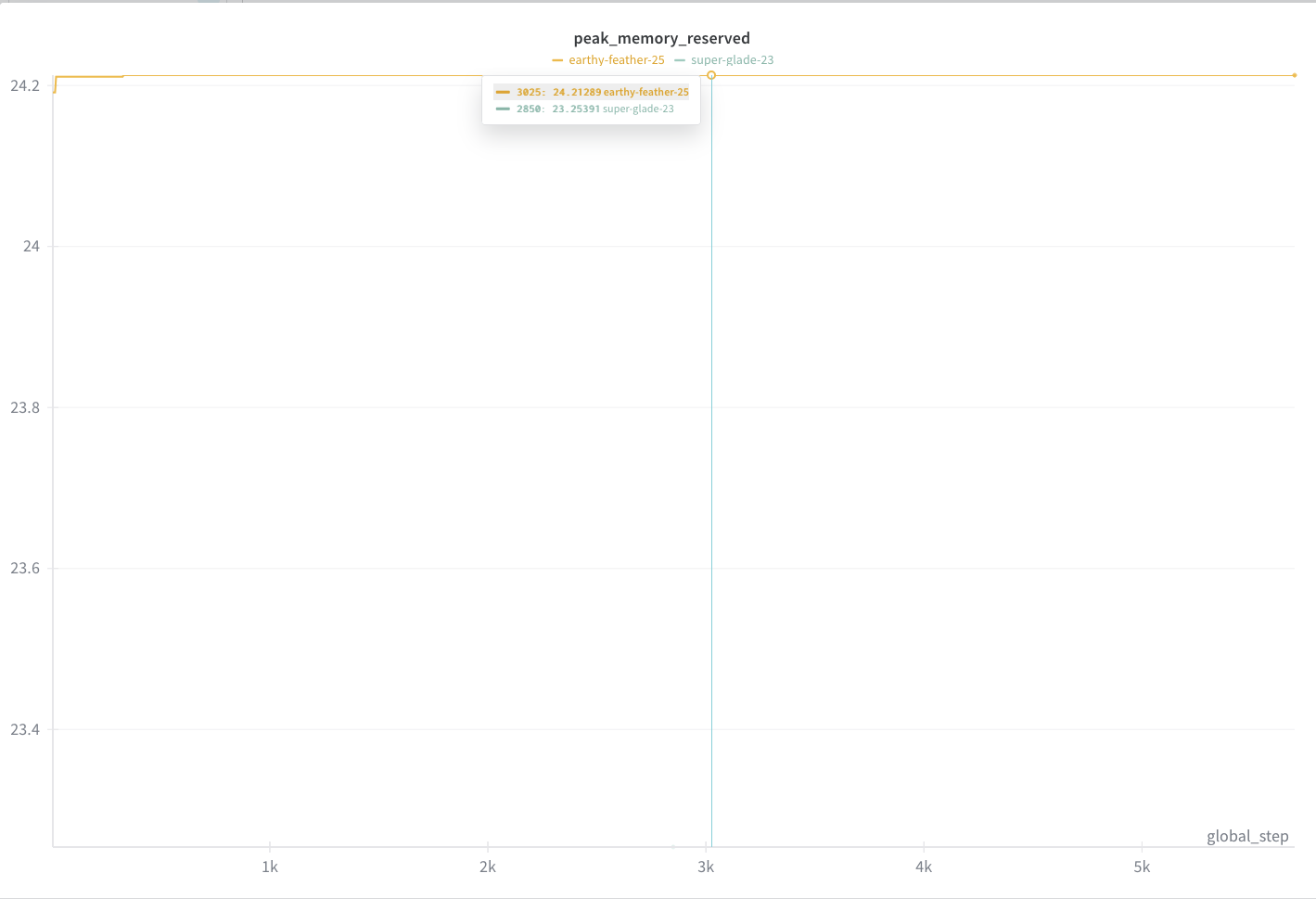
+#### Peak memory
|
|
|
+
|
|
|
+<img src="peak_memory.png" width="600" alt="Peak Memory Usage">
|
|
|
+
|
|
|
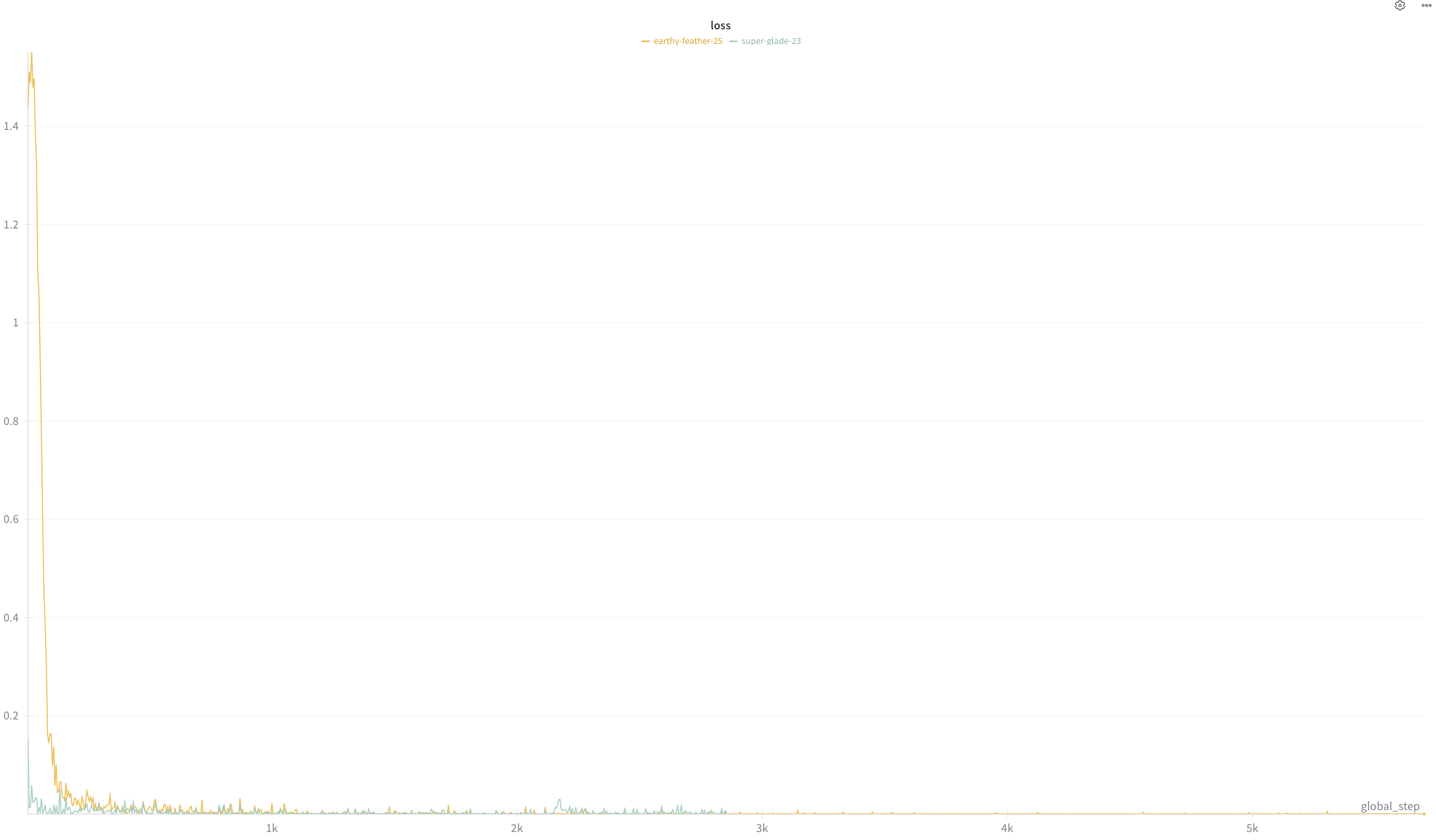
+#### Loss curve graph
|
|
|
+
|
|
|
+<img src="loss_curve.png" width="600" alt="Loss curve">
|
|
|
|
|
|
## Comparison with Llama API
|
|
|
|

 Beto de Paola
Beto de Paola
{kind=link}
{kind=link}