# Fine-tuning Llama 3.2 11B Vision for Structured Data Extraction
This recipe demonstrates how to fine-tune Llama 3.2 11B Vision model on a synthetic W-2 tax form dataset for structured data extraction. The tutorial compares LoRA (Low-Rank Adaptation) and full parameter fine-tuning approaches, evaluating their trade-offs in terms of accuracy, memory consumption, and computational requirements.
## Objectives
- Showcase how to fine-tune and evaluate on a specific extraction use case
- Demonstrate custom benchmarking for structured output tasks
- Compare trade-offs between LoRA and Full Parameter Fine-tuning on both task-specific and general benchmarks
- Provide guidance on data preparation, training configuration, and evaluation methodologies
## Results
### Task-Specific Performance (W2 Extraction)
| Benchmark |
11B bf16 (Baseline) |
LoRA |
FPFT |
FPFT int4 |
| W2 extraction acc |
58 |
72 |
98 |
96 |
### General Benchmark Performance (llama-verifications)
| Benchmark |
11B bf16 (Baseline) |
LoRA |
FPFT |
FPFT int4 |
| bfclv3 |
39.87 |
39.87 |
39.85 |
34.67 |
| docvqa |
86.88 |
85.08 |
86.3 |
78.95 |
| gpqa-cot-diamond |
27.78 |
27.78 |
26 |
28 |
| ifeval |
74.79 |
74.78 |
74.54 |
74.42 |
| mmlu-pro-cot |
48.43 |
48.13 |
48.33 |
46.14 |
### LM Evaluation Harness Results
| Benchmark |
11B bf16 (Baseline) |
FPFT |
| gsm8k_cot_llama_strict |
85.29 |
85.29 |
| gsm8k_cot_llama_flexible |
85.44 |
85.44 |
| chartqa llama exact |
0 |
0 |
| chartqa llama relaxed |
34.16 |
35.58 |
| chartqa llama anywhere |
43.53 |
46.52 |
## Prerequisites
- CUDA-compatible GPU with at least 40GB VRAM
- HuggingFace account with access to Llama models
- Python 3.10+
## Setup
### Environment Creation
```bash
git clone git@github.com:meta-llama/llama-cookbook.git
cd llama-cookbook/getting-started/finetuning/vision
conda create -n image-ft python=3.12 -y
conda activate image-ft
```
### Dependencies Installation
```bash
pip install torchtune torch torchvision torchaudio torchao bitsandbytes transformers==4.51.1 accelerate vllm==0.9.2 lm_eval wandb
```
Install torchtune nightly for the latest vision model support:
```bash
pip install --pre --upgrade torchtune --extra-index-url https://download.pytorch.org/whl/nightly/cpu
```
**Important**: Log in to your HuggingFace account to download the model and datasets:
```bash
huggingface-cli login
```
## Dataset Preparation
The dataset contains 2,000 examples of synthetic W-2 forms with three splits: train (1,800), test (100), and validation (100). For this use case, we found that fewer training examples (30% train, 70% test) provided sufficient improvement while allowing for more comprehensive evaluation.
The preparation script:
1. Reshuffles the train/test splits according to the specified ratio
2. Removes unnecessary JSON structure wrappers from ground truth
3. Adds standardized prompts for training
```bash
python prepare_w2_dataset.py --train-ratio 0.3
```
This creates a new dataset directory: `fake_w2_us_tax_form_dataset_train30_test70`
**Configuration Note**: If you change the train ratio, update the `dataset.data_files.train` path in the corresponding YAML configuration files.
## Model Download
Download the base Llama 3.2 11B Vision model:
```bash
tune download meta-llama/Llama-3.2-11B-Vision-Instruct --output-dir Llama-3.2-11B-Vision-Instruct
```
This downloads to the expected directory structure used in the provided YAML files. If you change the directory, update these keys in the configuration files:
- `checkpointer.checkpoint_dir`
- `tokenizer.path`
## Baseline Evaluation
Before fine-tuning, establish a baseline by evaluating the pre-trained model on the test set.
### Start vLLM Server
For single GPU (H100):
```bash
CUDA_VISIBLE_DEVICES="0" python -m vllm.entrypoints.openai.api_server --model Llama-3.2-11B-Vision-Instruct/ --port 8001 --max-model-len 65000 --max-num-seqs 10
```
For multi-GPU setup:
```bash
CUDA_VISIBLE_DEVICES="0,1" python -m vllm.entrypoints.openai.api_server --model Llama-3.2-11B-Vision-Instruct/ --port 8001 --max-model-len 65000 --tensor-parallel-size 2 --max-num-seqs 10
```
### Run Baseline Evaluation
```bash
python evaluate.py --server_url http://localhost:8001/v1 --model Llama-3.2-11B-Vision-Instruct/ --structured --dataset fake_w2_us_tax_form_dataset_train30_test70/test --limit 100 --max_workers 25
```
## Fine-tuning
### Configuration Overview
The repository includes two pre-configured YAML files:
- `11B_full_w2.yaml`: Full parameter fine-tuning configuration
- `11B_lora_w2.yaml`: LoRA fine-tuning configuration
Key differences:
**Full Parameter Fine-tuning:**
- Trains encoder and fusion layers, leaving decoder frozen
- Higher memory requirements but potentially better performance
- Learning rate: 2e-5
- Optimizer: PagedAdamW8bit for memory efficiency
**LoRA Fine-tuning:**
- Only trains low-rank adapters across enconder and fusion layers only as well. Decoder is frozen.
- Significantly lower memory requirements
- Learning rate: 1e-4
- LoRA rank: 8, alpha: 16
- Frozen decoder with LoRA on encoder and fusion layers
### WandB Configuration
Before training, update the WandB entity in your YAML files:
```yaml
metric_logger:
_component_: torchtune.training.metric_logging.WandBLogger
project: llama3_2_w2_extraction
entity: # Update this
```
### Training Commands
**Full Parameter Fine-tuning:**
```bash
tune run full_finetune_single_device --config 11B_full_w2.yaml
```
**LoRA Fine-tuning:**
```bash
tune run lora_finetune_single_device --config 11B_lora_w2.yaml
```
**Note**: The VQA dataset component in torchtune is pre-configured to handle the multimodal format, eliminating the need for custom preprocessors.
## Model Evaluation
### Local Evaluation Setup
Start a vLLM server with your fine-tuned model:
**For LoRA model:**
```bash
CUDA_VISIBLE_DEVICES="0,1" python -m vllm.entrypoints.openai.api_server --model ./outputs/Llama-3.2-11B-Instruct-w2-lora/epoch_4/ --port 8001 --max-model-len 65000 --tensor-parallel-size 2 --max-num-seqs 10
```
**For full fine-tuned model:**
```bash
CUDA_VISIBLE_DEVICES="0,1" python -m vllm.entrypoints.openai.api_server --model ./outputs/Llama-3.2-11B-Instruct-w2-full/epoch_4/ --port 8001 --max-model-len 65000 --tensor-parallel-size 2
```
### Task-Specific Evaluation
```bash
python evaluate.py --server_url http://localhost:8001/v1 --model ./outputs/Llama-3.2-11B-Instruct-w2-full/epoch_4/ --structured --dataset fake_w2_us_tax_form_dataset_train30_test70/test --limit 100 --max_workers 25
```
### Cloud Evaluation Setup
To evaluate bigger models, like Llama 4 Maverick, we leverage cloud providers that server these models, like together.ai. Any OpenAI compatible provider should work out of the box with our evaluation script, as it uses the OpenAI SDK.
```bash
TOGETHER_API_KEY= python evaluate.py --server_url https://api.together.xyz/v1 --model meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8 --structured --dataset fake_w2_us_tax_form_dataset_train30_test70/test --limit 100 --max_workers 25
```
### General Benchmark Evaluation
Install llama-verifications for standard benchmarks:
```bash
pip install llama-verifications
```
Run benchmark evaluation:
```bash
uvx llama-verifications run-benchmarks \
--benchmarks mmlu-pro-cot,gpqa-cot-diamond,bfclv3,docvqa \
--provider http://localhost:8001/v1 \
--model \
--continue-on-failure \
--max-parallel-generations 100
```
### LM Evaluation Harness
For additional benchmarks using lm-eval:
**With vLLM backend:**
```bash
CUDA_VISIBLE_DEVICES=0,1 lm_eval --model vllm \
--model_args pretrained=,tensor_parallel_size=2,dtype=auto,gpu_memory_utilization=0.9 \
--tasks gsm8k_cot_llama \
--batch_size auto \
--seed 4242
```
**With transformers backend:**
```bash
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch -m lm_eval --model hf-multimodal \
--model_args pretrained= \
--tasks chartqa_llama_90 \
--batch_size 16 \
--seed 4242 \
--log_samples \
--output_path results
```
## Key Findings
### Task-Specific Performance
- **Full Parameter Fine-tuning** achieved the best task-specific performance (97% accuracy on W2 extraction)
- **LoRA fine-tuning** provided substantial improvement (72% vs 58% baseline) with significantly lower resource requirements
- Both approaches showed dramatic improvement over the baseline for the specific task
### General Capability Preservation
- **LoRA fine-tuning** preserved general capabilities better, showing minimal degradation on standard benchmarks
- **Full Parameter fine-tuning** showed minimal degradation on industry benchmarks, making it the preferred choice for this small dataset and FT results. With a larger dataset, as the original split of 80/10/10 and more steps, we do see additional degradation on the benchmarks.
- Both methods maintained strong performance on mathematical reasoning tasks (gsm8k)
### Resource Efficiency
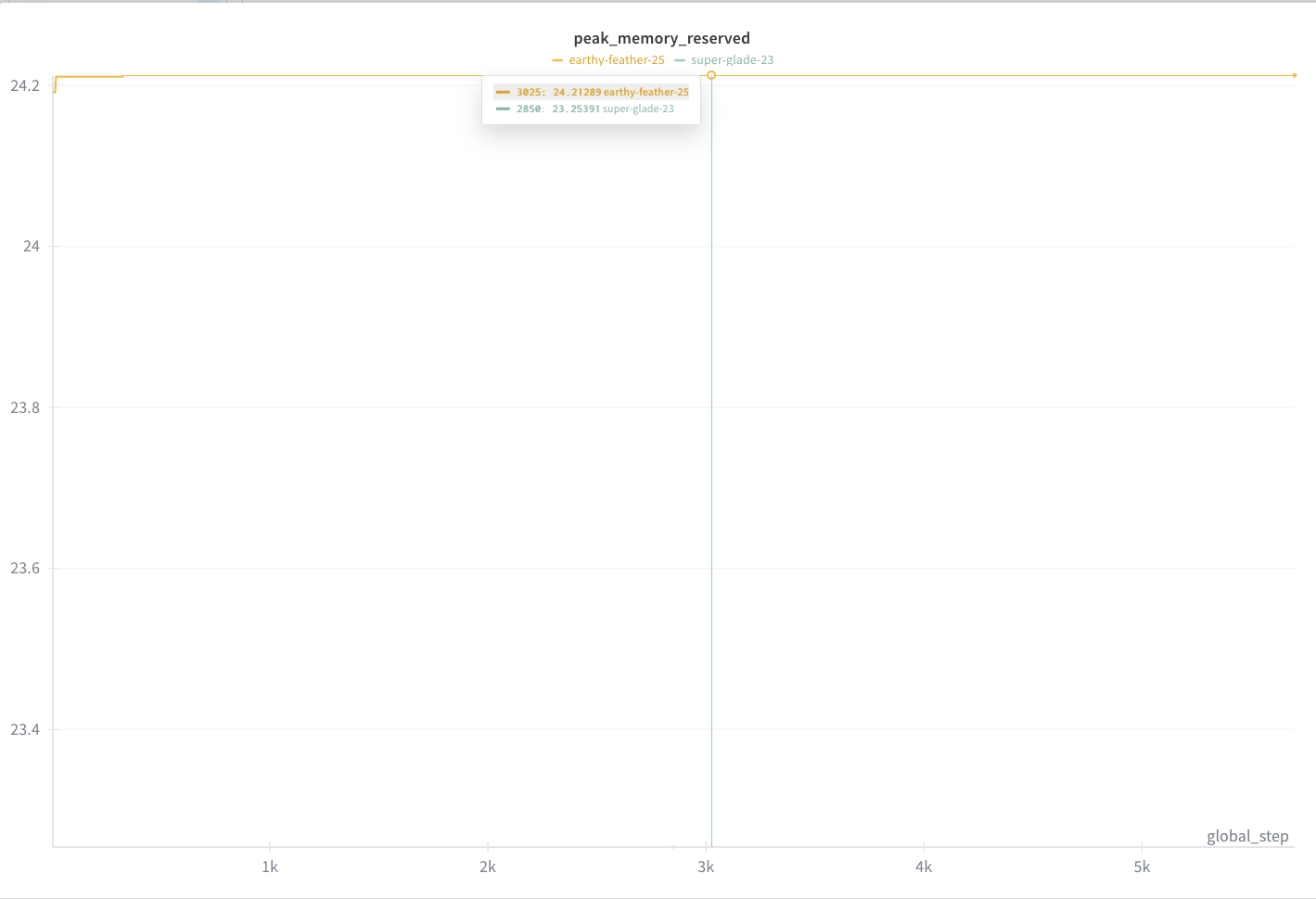
- **LoRA** requires significantly less GPU memory and training time
- **Full Parameter fine-tuning** requires more resources but achieves better task-specific performance
## Performance Graphs
### Performance
#### Peak memory
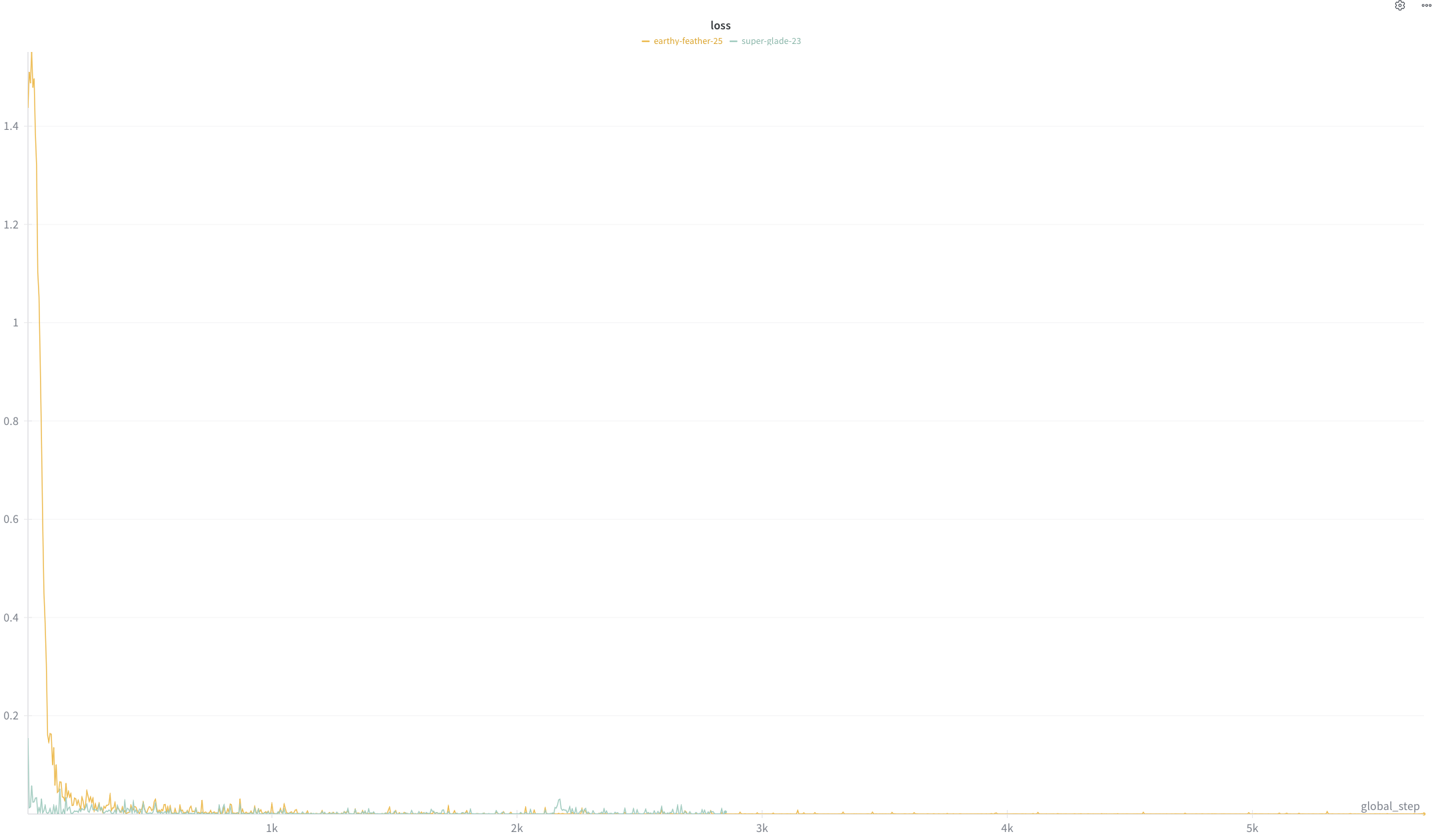
 #### Loss curve graph
#### Loss curve graph
 ## Comparison with Llama API
You can benchmark against the Llama API for comparison:
```bash
LLAMA_API_KEY="" python evaluate.py \
--server_url https://api.llama.com/compa/v1 \
--limit 100 \
--model Llama-4-Maverick-17B-128E-Instruct-FP8 \
--structured \
--max_workers 50 \
--dataset fake_w2_us_tax_form_dataset_train30_test70/test
```
## Best Practices
1. **Data Preparation**: Ensure your dataset format matches the expected structure. The preparation script handles common formatting issues.
2. **Configuration Management**: Always update paths in YAML files when changing directory structures.
3. **Memory Management**: Use PagedAdamW8bit optimizer for full parameter fine-tuning to reduce memory usage.
4. **Evaluation Strategy**: Evaluate both task-specific and general capabilities to understand trade-offs.
5. **Monitoring**: Use WandB for comprehensive training monitoring and comparison.
## Troubleshooting
### Common Issues
1. **CUDA Out of Memory**: Reduce batch size, enable gradient checkpointing, or use LoRA instead of full fine-tuning.
2. **Dataset Path Errors**: Verify that dataset paths in YAML files match your actual directory structure.
3. **Model Download Issues**: Ensure you're logged into HuggingFace and have access to Llama models.
4. **vLLM Server Connection**: Check that the server is running and accessible on the specified port.
## References
- [Torchtune Documentation](https://pytorch.org/torchtune/)
- [vLLM Documentation](https://vllm.readthedocs.io/)
- [LM Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness)
- [Synthetic Data Kit](https://github.com/meta-llama/synthetic-data-kit)
## Comparison with Llama API
You can benchmark against the Llama API for comparison:
```bash
LLAMA_API_KEY="" python evaluate.py \
--server_url https://api.llama.com/compa/v1 \
--limit 100 \
--model Llama-4-Maverick-17B-128E-Instruct-FP8 \
--structured \
--max_workers 50 \
--dataset fake_w2_us_tax_form_dataset_train30_test70/test
```
## Best Practices
1. **Data Preparation**: Ensure your dataset format matches the expected structure. The preparation script handles common formatting issues.
2. **Configuration Management**: Always update paths in YAML files when changing directory structures.
3. **Memory Management**: Use PagedAdamW8bit optimizer for full parameter fine-tuning to reduce memory usage.
4. **Evaluation Strategy**: Evaluate both task-specific and general capabilities to understand trade-offs.
5. **Monitoring**: Use WandB for comprehensive training monitoring and comparison.
## Troubleshooting
### Common Issues
1. **CUDA Out of Memory**: Reduce batch size, enable gradient checkpointing, or use LoRA instead of full fine-tuning.
2. **Dataset Path Errors**: Verify that dataset paths in YAML files match your actual directory structure.
3. **Model Download Issues**: Ensure you're logged into HuggingFace and have access to Llama models.
4. **vLLM Server Connection**: Check that the server is running and accessible on the specified port.
## References
- [Torchtune Documentation](https://pytorch.org/torchtune/)
- [vLLM Documentation](https://vllm.readthedocs.io/)
- [LM Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness)
- [Synthetic Data Kit](https://github.com/meta-llama/synthetic-data-kit)