
 Jeff Tang
0033fc9cf2
README update
Jeff Tang
0033fc9cf2
README update
|
4 ヶ月 前 | |
|---|---|---|
| .. | ||
| data | 4 ヶ月 前 | |
| fine_tuning | 4 ヶ月 前 | |
| README.md | 4 ヶ月 前 | |
| llama_eval.sh | 4 ヶ月 前 | |
| llama_text2sql.py | 4 ヶ月 前 | |
| requirements.txt | 4 ヶ月 前 | |
| text2sql_eval.py | 4 ヶ月 前 | |
README.md
Text2SQL Evaluation and Fine-Tuning Tools for Llama Models
This folder contains the scripts for evaluating Llama models on Text2SQL tasks, preparing supervised and reasoning datasets, fine-tuning Llama 3.1 8B with the datasets, and evaluating the fine-tuned model. The original dataset and scripts are from the BIRD-SQL benchmark and repo, but we have significantly simplified and streamlined them for Llama models hosted via Meta's Llama API or Together.ai, so you can quickly evaluate how well different Llama models perform Text2SQL tasks and how to fine-tune the models for better accuracy.
Quick Start on Evaluating Llama on Text2SQL
First, cd llama-cookbook/getting-started/llama-tools/text2sql and run pip install -r requirements.txt to install all the required packages.
Then, follow the steps below to evaluate Llama 3 & 4 models on Text2SQL using the BIRD benchmark:
Get the DEV dataset:
cd data sh download_dev_unzip.shOpen
llama_eval.shand setYOUR_API_KEYto your Llama API key or Together API key, then uncomment a line that starts withmodel=to specify the Llama model to use for the text2sql eval.Run the evaluation script
sh llama_eval.sh, which will use the BIRD DEV dataset (1534 examples in total) with external knowledge turned on to run the Llama model on each text question and compare the generated SQL with the gold SQL.
After the script completes, you'll see the accuracy of the Llama model on the BIRD DEV text2sql. For example, the total accuracy is about 54.24% with YOUR_API_KEY set to your Llama API key and model='Llama-3.3-70B-Instruct', or about 35.07% with YOUR_API_KEY set to your Together API key and model=meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo.
Note: To compare your evaluated accuracy of your selected Llama model with other results in the BIRD Dev leaderboard, click here.
| Model | Llama API Accuracy | Together Accuracy |
|---|---|---|
| Llama 3.1 8b | - | 35.66% |
| Llama 3.3 70b | 54.11% | 54.63% |
| Llama-3.1-405B | - | 55.80% |
| Llama 4 Scout | 44.39% | 43.94% |
| Llama 4 Maverick | 44.00% | 41.46% |
Supported Models
Together AI Models
- meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo
- meta-llama/Llama-3.3-70B-Instruct-Turbo
- meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8
- meta-llama/Llama-4-Scout-17B-16E-Instruct
- other Llama models hosted on Together AI
Llama API Models
- Llama-3.3-8B-Instruct
- Llama-3.3-70B-Instruct
- Llama-4-Maverick-17B-128E-Instruct-FP8
- Llama-4-Scout-17B-16E-Instruct-FP8
- other Llama models hosted on Llama API
Evaluation Process
SQL Generation:
llama_text2sql.pysends natural language questions to the specified Llama model and collects the generated SQL queries.SQL Execution:
text2sql_eval.pyexecutes both the generated SQL and ground truth SQL against the corresponding databases, then continues with steps 3 and 4 below.Result Comparison: The results from executing the generated SQL are compared with the results from the ground truth SQL to determine correctness.
Accuracy Calculation: Accuracy scores are calculated overall and broken down by difficulty levels (simple, moderate, challenging).
Preparing Fine-tuning Dataset
Using the TRAIN to prepare for supervised fine-tuning
Get the TRAIN dataset:
cd data sh download_train_unzip.shCreate the dataset
cd fine_tuning
python create_sft_dataset.py --input_json ../data/train/train.json --db_root_path ../data/train/train_databases
This will create train_text2sql_sft_dataset.json and test_text2sql_sft_dataset.json using the TRAIN set. Each line in the json files is in the conversation format ready for fine-tuning:
{"messages":[{"content":"You are a text to SQL query translator. Using the SQLite DB Schema and the External Knowledge, translate the following text question into a SQLite SQL select statement.","role":"system"},{"content":"-- DB Schema: <DB_SCHEMA>\n\n-- External Knowledge: <KNOWLEDGE_FROM_TRAIN>\n\n-- Question: <TEXT_QUESTION>","role":"user"},{"content":"<GOLD_SQL>","role":"assistant"}]}
Supervised Fine-tuning
First, you need to login to HuggingFace (via running huggingface-cli login and enter your HF token) and have been granted access to the Llama 3.1 8B Instruct model.
Then run python trl_sft.py. After the fine-tuning completes, you'll see the fine-tuned model saved to llama31-8b-text2sql-fine_tuning.
After running tensorboard --logdir ./llama31-8b-text2sql-fine_tuning you can open http://localhost:6006 to see the train loss chat etc:
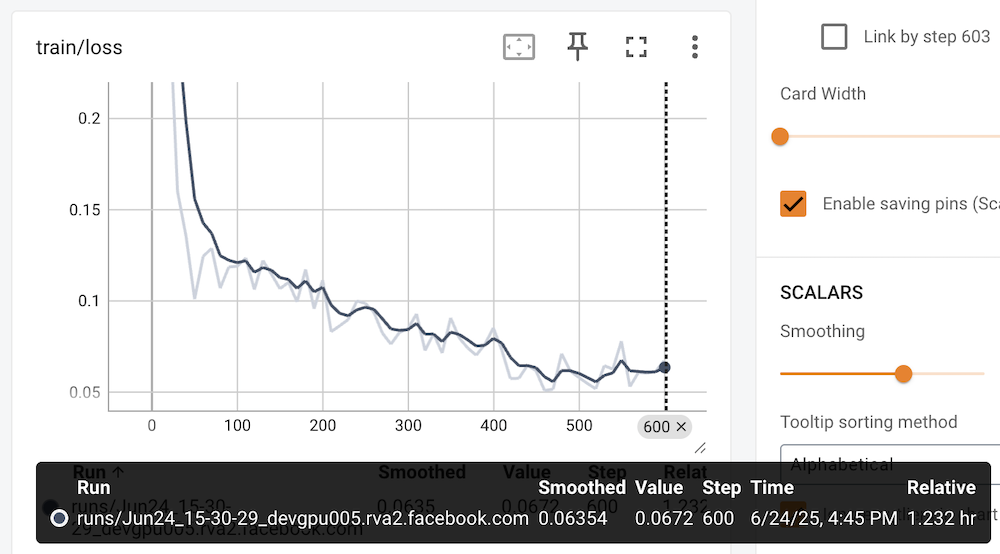
Evaluating the fine-tuned model
First, modify llama_eval.sh to use the fine-tuned model:
YOUR_API_KEY='finetuned'
model='fine_tuning/llama31-8b-text2sql'
Then run sh llama_eval.sh to evaluate the fine-tuned model. The accuracy on the BIRD DEV dataset is about 37.16%. This is a 165% improvement over the model before fine-tuning, which has an accuracy of about 14.02% on the same dataset - you can confirm this by comparing the fine-tuned model's accuracy above with the original model's accuracy by modifying llama_eval.sh to use the original model:
YOUR_API_KEY='huggingface'
model='meta-llama/Llama-3.1-8B-Instruct'
Then running sh llama_eval.sh to evaluate the original model.
Note: We are using the 4-bit quantized Llama 3.1 8b model to reduce the memory footprint and improve the efficiency (as shown in the code nippet of llama_text2sql.py below), hence the accuracy of the quantized version (14.02%) is quite lower than the accuracy of the original Llama 3.1 8b (35.66%).
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
Creating a reasoning dataset from the TRAIN dataset
In the fine_tuning folder, run:
python create_reasoning_dataset.py --input_json data/train/train.json --db_root_path data/train/train_databases
This will create text2sql_cot_dataset dataset in HuggingFace format, which is ready for fine-tuning with the reasoning prompt. Each line in the json file is in the conversation format ready for fine-tuning:
"messages": [
{
"role": "system",
"content": "You are a text to SQL query translator. Using the SQLite DB Schema and the External Knowledge, generate the step-by-step reasoning and the final SQLite SQL select statement from the text question.",
},
{"role": "user", "content": prompt},
{"role": "assistant", "content": reasoning},
]